
La función merge () se usa para fusionar dos objetos DataFrame o Series. Esta función se usa a menudo en el procesamiento de datos. El sitio web oficial da la definición de esta función de la siguiente manera:
pandas.merge(left, right, how: str = 'inner', on=None, left_on=None, right_on=None, left_index: bool = False, right_index: bool = False, sort: bool = False, suffixes='_x', '_y', copy: bool = True, indicator: bool = False, validate=None)Primero introduzca el significado y la función de cada parámetro;
| izquierda | DataFrame a la izquierda |
|---|
Lo anterior es una introducción a los parámetros. A continuación, se combinan algunas operaciones de ejemplo en torno a estos parámetros para explicar en detalle el uso específico de la función merge (), que se divide en varias partes:
Cuando los DataFrames izquierdo y derecho tienen el mismo valor de clave;
Establezca el parámetro en para lograr una combinación simple de dos DataFrames
In [1]: import pandas as pd
In [2]: data1 =pd.DataFrame({'key':['K0','K1','K2','K3'],
...: 'A':['A0','A1','A2','A3'],
...: 'B':['B0','B1','B2','B3']})
In [3]: data2 = pd.DataFrame({'key':['K0','K1','K2','K3'],})
In [4]: data2 = pd.DataFrame({'key':['K0','K1','K2','K3'],
...: 'C':['C0','C1','C2','C3'],
...: 'D':['D0','D1','D2','D3']})
In [5]: result = pd.merge(data1,data2,on = 'key')
In [6]: result
Out[6]:
key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3fusionar cuatro métodos de fusión
| cómo = "izquierda" | Solo la clave de la izquierda se usa como punto de referencia, y el elemento de falla coincidente de la derecha se establece en Nulo |
|---|
In [7]: data1 =pd.DataFrame({'a':['a1','a2','a3'],
...: 'b':['b1','b2','b3'],
...: 'key':['a','b','c'],
...: 'key1':['d','e','f']})
...:
...:
In [8]: data2 = pd.DataFrame({'c':['c1','c2','c3'],
...: 'd':['d1','d2','d3'],
...: 'key':['a','b','a'],
...: 'key1':['d','e','e']})cómo = "izquierda" 合并
Tome la clave del DataFrame a la izquierda como punto de referencia. Si la coincidencia falla a la derecha, reemplácela con NaN y elimine la fila donde aparece la clave adicional.
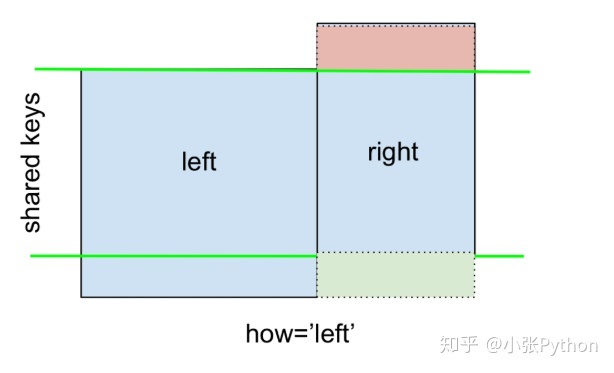
- Interpretación de gráficos:
- rojo: indica que la fila está eliminada;
- azul: representa que la fila está reservada;
- verde: indica que el valor no coincidente se reemplaza por NaN;
In [9]: # how = left,以左边键为基准
In [10]: pd.merge(data1,data2,how ="left",on = ['key','key1'])
Out[10]:
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 a3 b3 c f NaN NaNcómo = "correcto"
Según la clave del DataFrame derecho, el uso es similar a how = "left", pero la dirección es opuesta;

In [11]: #how = right ,以右边为基准
In [12]: pd.merge(data1,data2,how = 'right',on =['key','key1'])
Out[12]:
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 NaN NaN a e c3 d3cómo = "interior"
Este método de fusión se usa con más frecuencia, según las claves compartidas por los DataFrames izquierdo y derecho. La coincidencia correcta se conserva y todas las filas en las que falla la coincidencia se eliminan;

In [16]: # how = inner,取左右交集;
In [17]: pd.merge(data1,data2,how ='inner',on = ['key','key1'])
Out[17]:
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2cómo = "exterior"
En correspondencia con el uso de how = "inner", basado en las claves compartidas por los DataFrames izquierdo y derecho, las claves que coinciden correctamente se conservan y los valores clave que no coinciden se reemplazan por Nan;

In [13]: # how = outer,r取左右两边并集
In [15]: pd.merge(data1,data2,how ='outer',on = ['key','key1'])
Out[15]:
a b key key1 c d
0 a1 b1 a d c1 d1
1 a2 b2 b e c2 d2
2 a3 b3 c f NaN NaN
3 NaN NaN a e c3 d3DataFrame tiene diferentes valores clave combinados
Cuando los dos DataFrames que se van a fusionar tienen diferentes valores clave, los parámetros left_on y right_on deben usarse aquí para especificar los nombres de columna de los DataFrames izquierdo y derecho respectivamente;
left_on y right_on son claves como puntos de referencia
Al seleccionar el nombre de la clave para left_on, debe establecer el nombre de clave correspondiente para right_on, y debe asegurarse de que len (left_on) == len (right_on),
El parámetro de sufijos se agrega porque la izquierda y la derecha tienen el mismo nombre de columna (valor) para garantizar que los nombres de columna combinados sean diferentes
In [18]: df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
...: 'value': [1, 2, 3, 5]})
In [19]: df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
...: 'value': [5, 6, 7, 8]})
In [20]: df1
Out[20]:
lkey value
0 foo 1
1 bar 2
2 baz 3
3 foo 5
In [21]: df2
Out[21]:
rkey value
0 foo 5
1 bar 6
2 baz 7
3 foo 8
In [22]: pd.merge(df1,df2,left_on ='lkey')
In [23]: pd.merge(df1,df2,left_on ='lkey',right_on ='rkey')
Out[23]:
lkey value_x rkey value_y
0 foo 1 foo 5
1 foo 1 foo 8
2 foo 5 foo 5
3 foo 5 foo 8
4 bar 2 bar 6
5 baz 3 baz 7
# 设置 suffixes 参数之后
In [24]: pd.merge(df1,df2,left_on ='lkey',right_on ='rkey',suffixes=("_lf","_rf"))
Out[24]:
lkey value_lf rkey value_rf
0 foo 1 foo 5
1 foo 1 foo 8
2 foo 5 foo 5
3 foo 5 foo 8
4 bar 2 bar 6
5 baz 3 baz 7Antes de la operación, debe asegurarse de que la longitud del valor de la clave sea igual, len (left_on) == len (right_on) ; de lo contrario, se producirá el siguiente error:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-0660dac837b1> in <module>
----> 1 pd.merge(df1,df2,left_on ='lkey')
~\Anaconda3\lib\site-packages\pandas\core\reshape\merge.py in merge(left, right, how, on, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
79 copy=copy,
80 indicator=indicator,
---> 81 validate=validate,
82 )
83 return op.get_result()
~\Anaconda3\lib\site-packages\pandas\core\reshape\merge.py in __init__(self, left, right, how, on, left_on, right_on, axis, left_index, right_index, sort, suffixes, copy, indicator, validate)
617 warnings.warn(msg, UserWarning)
618
--> 619 self._validate_specification()
620
621 # note this function has side effects
~\Anaconda3\lib\site-packages\pandas\core\reshape\merge.py in _validate_specification(self)
1221 )
1222 self.left_on = [None] * n
-> 1223 if len(self.right_on) != len(self.left_on):
1224 raise ValueError("len(right_on) must equal len(left_on)")
1225
TypeError: object of type 'NoneType' has no len()Tome la columna de índice (índice) como el punto de referencia de fusión
merge () también puede utilizar la columna de índice como punto de referencia de fusión. En este momento, se utilizan los dos parámetros left_on y right_on, ambos establecidos en True;
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135Combine múltiples DataFrames al mismo tiempo
Hay muchas formas de fusionar múltiples DataFrames, aquí están las siguientes:
Fusión ineficiente ()
df1.merge(df2, ...).merge(df3, ...)Es necesario establecer varios parámetros cuando se combinan métodos, y son relativamente ineficaces;
pd.concat () para fusionar
pd.concat () puede fusionar varios DataFrames al mismo tiempo. El método de fusión es el mismo que los cuatro métodos merge () mencionados anteriormente. La diferencia es que la palabra clave cómo se usa para conectarse y join se usa como parámetro de conexión aquí:
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
4. El parámetro indicador
El parámetro indicador (establecido en True); se usa para indicar que se agregará una nueva columna al DataFrame, el nombre de la columna es _merge; para indicar la información del tipo de combinación de cada fila.
In [25]: pd.merge(data1,data2,how ='outer',on = ['key','key1'],indicator = True)
Out[25]:
a b key key1 c d _merge
0 a1 b1 a d c1 d1 both
1 a2 b2 b e c2 d2 both
2 a3 b3 c f NaN NaN left_only
3 NaN NaN a e c3 d3 right_onlyEl indicador también se puede establecer en Cadena, nombre de columna personalizado
In [27]: pd.merge(data1,data2,how ='outer',on = ['key','key1'],indicator ="col_info")
Out[27]:
a b key key1 c d col_info
0 a1 b1 a d c1 d1 both
1 a2 b2 b e c2 d2 both
2 a3 b3 c f NaN NaN left_only
3 NaN NaN a e c3 d3 right_onlyBueno, lo anterior es la introducción al uso de merge () en este artículo. El uso más profundo y completo de merge () se discutirá más adelante.
¡Finalmente, gracias a todos por leer!
Referencia:
1, https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html