Conceptos básicos de Docker
Imagen de espejo
¿Qué es el reflejo? En términos sencillos, es una combinación de archivo y carpeta de solo lectura. Contiene todos los archivos básicos y la información de configuración necesaria cuando el contenedor se está ejecutando y es la base para el inicio del contenedor. Entonces, si desea comenzar un contenedor, primero debe tener un espejo.
La creación de reflejos es un requisito previo para el inicio del contenedor Docker.
Si desea utilizar un espejo, puede utilizar estas dos formas:
1. Cree un espejo usted mismo.
Por lo general, una imagen se crea en base a una imagen básica y puede agregar contenido definido por el usuario a la imagen básica.
Por ejemplo: puede crear su propia imagen empresarial basada en la imagen centos, primero instale el servicio nginx, luego implemente su aplicación y, finalmente, realice una configuración personalizada, de modo que su propia imagen empresarial esté lista.
2. Extraiga las imágenes de espejo hechas por otros del almacén de espejos funcionales.
Algunos programas o sistemas de uso común tendrán imágenes oficiales.
Por ejemplo: nginx, ubuntu, centos, mysql, etc. Puede ir a Docker Hub para buscarlos y descargarlos.
envase
¿Qué es un contenedor?
Los contenedores son otro concepto central de Docker. En términos sencillos, el contenedor es la entidad de ejecución de la imagen.
La imagen es un archivo estático de solo lectura y el contenedor tiene una capa de archivo de escritura requerida en tiempo de ejecución, y el proceso en el contenedor está en un estado de ejecución. Es decir, el contenedor está ejecutando el proceso de aplicación real.
El contenedor tiene cinco estados: creación inicial, ejecución, detención, suspensión y eliminación.
Aunque la esencia de un contenedor es un proceso que se ejecuta en el host, el contenedor tiene su propio aislamiento de espacio de nombres independiente y restricciones de recursos. Es decir, dentro del contenedor, no puede ver el proceso, las variables de entorno, la red y otra información en el host. Ésta es la diferencia esencial entre el contenedor y el proceso que se ejecuta directamente en el host.
depósito
El almacén espejo de Docker es similar a un almacén de código, utilizado para almacenar y distribuir imágenes de Docker. El almacén de espejos se divide en almacén de espejos público y almacén de espejos privado.
En la actualidad, Docker Hub (https://hub.docker.com/) es el repositorio espejo público oficial de Docker. No solo tiene muchos espejos oficiales de aplicaciones o sistemas operativos, sino también muchos espejos desarrollados por organizaciones o individuos para nosotros. para almacenar de forma gratuita, descargar, investigar y utilizar. Además del repositorio espejo público, también puede crear su propio repositorio espejo privado.
La conexión entre espejo, contenedor y almacén se muestra en la siguiente figura:
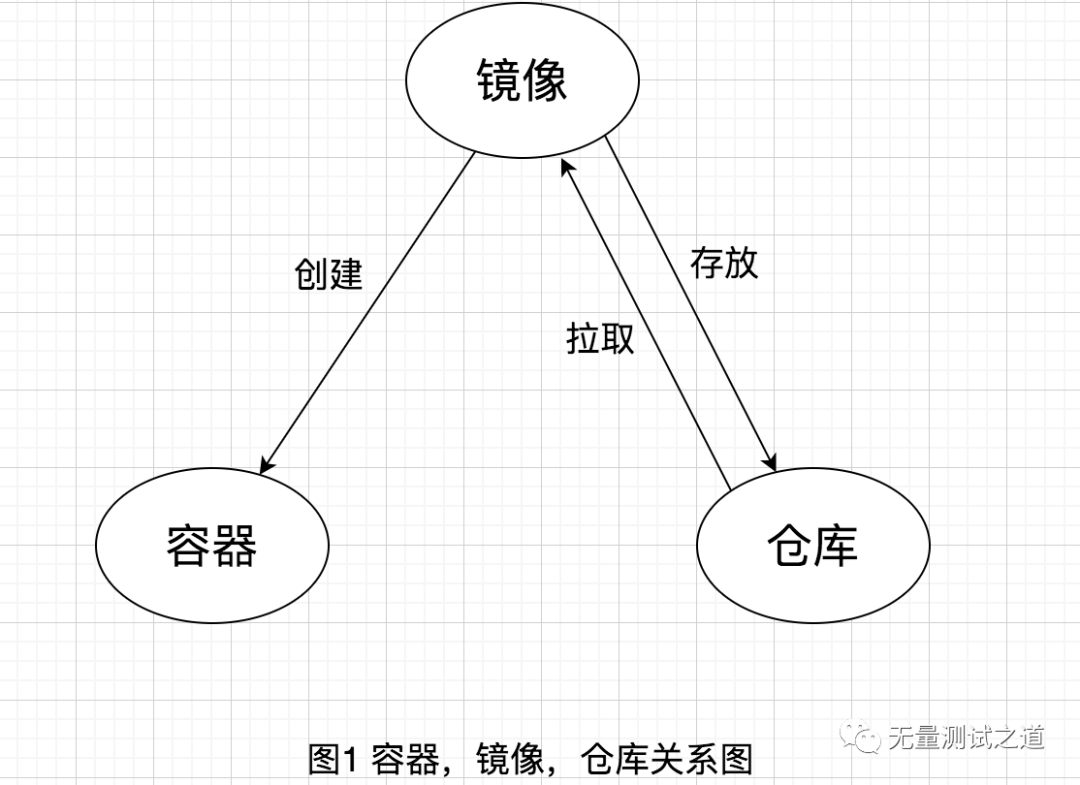

Como se puede ver en la figura anterior, la imagen es la piedra angular del contenedor y el contenedor es creado por la imagen. Una imagen puede crear varios contenedores, y el contenedor es la entidad en la que se ejecuta la imagen. El almacén se utiliza para almacenar y distribuir imágenes.
Arquitectura central de Docker
Antes de comprender la arquitectura central de Docker, introduzcamos brevemente la historia del desarrollo de contenedores.
Docker se convirtió en un éxito instantáneo en 2013 y desde entonces ha continuado despertando entusiasmo en el mundo de la TI y se ha convertido en sinónimo de tecnología de contenedores. Pero en este momento, además de los contenedores Docker, hay muchas otras tecnologías de contenedores en el mercado, como rkt, lxc, etc. de CoreOS.
Además de lanzar su propio software contenedor rkt, el equipo de CoreOS también ha creado un sistema operativo ligero basado en el kernel de Linux. Similar al proyecto de código abierto Docker, rkt es una versión de ejecución de contenedores que permite la creación de contenedores.
La aparición de tantas tecnologías de contenedores producirá inevitablemente algunos problemas. Por ejemplo, ¿cuál es el estándar para la tecnología de contenedores? ¿Quién debería hacer estándares para contenedores?
Quizás la mayoría de la gente dirá que Docker se ha convertido en el punto de referencia para la tecnología de contenedores ¿No es bueno considerar a Docker como el estándar para la tecnología de contenedores? El hecho no es tan simple como imaginaba. Porque en ese momento no solo había una disputa sobre los estándares de los contenedores, sino también una feroz disputa sobre la tecnología de orquestación. En ese momento, había tres fuerzas principales de la tecnología de orquestación, a saber, Docker Swarm, Kubernetes y Mesos.
Sin duda, Swarm está dispuesto a usar Docker como el único tiempo de ejecución del contenedor, pero Kubernetes y Mesos no están de acuerdo, porque no quieren ser demasiado solteros en la forma de programación.
En este contexto, finalmente estalló la guerra de contenedores y OCI surgió en este contexto.
El nombre completo de OCI es Open Container Initiative (Open Container Initiative) , que es una estructura de gobierno ligera y abierta. Con el fuerte apoyo de la Fundación Linux, la organización OCI se registró y estableció formalmente en junio de 2015. La fundación tiene como objetivo desarrollar un estándar de contenedor abierto para los usuarios en torno al formato y el tiempo de ejecución de la imagen de los contenedores industrializados.
En la actualidad, existen principalmente dos documentos estándar: el estándar de tiempo de ejecución del contenedor (especificación de tiempo de ejecución) y el estándar de imagen del contenedor (especificación de imagen).
Es precisamente debido a la guerra de contenedores que Docker tuvo que cambiar parte de la arquitectura técnica durante la guerra. Finalmente formó la arquitectura técnica que se muestra en la figura siguiente.
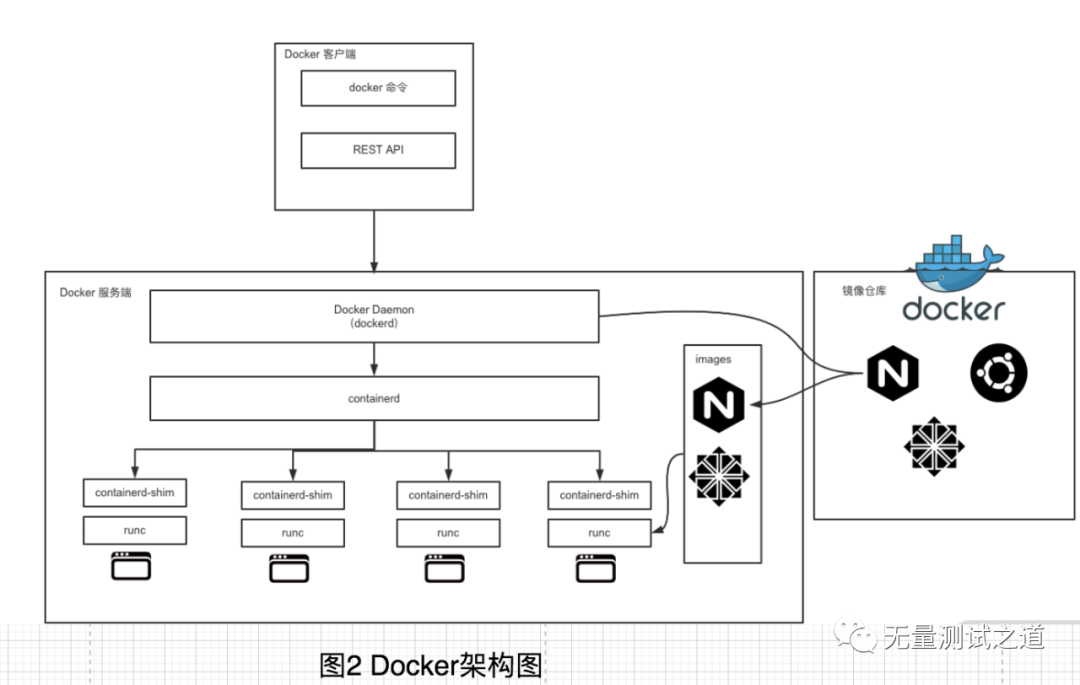

Podemos ver que la arquitectura general de Docker adopta el modelo C / S (Cliente / Servidor) , que se compone principalmente de dos partes: el cliente y el servidor.
El cliente es responsable de enviar las instrucciones de operación y el servidor es responsable de recibir y procesar las instrucciones. Hay muchas formas de comunicarse entre el cliente y el servidor, ya sea a través de sockets UNIX en la misma máquina o comunicación remota a través de una conexión de red.
La siguiente es una introducción al cliente y al servidor.
Cliente de Docker
Cliente de Docker es en realidad un término general. El comando de Docker es la forma principal para que los usuarios de Docker interactúen con el servidor de Docker.
Además de usar el comando docker, también puede solicitar directamente la API REST para interactuar con el servidor Docker, e incluso puede usar SDK en varios idiomas para interactuar con el servidor Docker. En la actualidad, la comunidad mantiene SDK en decenas de lenguajes como Go, Java, Python, PHP, etc., que son suficientes para satisfacer las necesidades diarias de todos.
Servidor Docker
El servidor Docker es el nombre colectivo de todos los servicios en segundo plano de Docker. Entre ellos, dockerd es un proceso de gestión en segundo plano muy importante, que se encarga de responder y procesar las solicitudes del cliente Docker, y luego convertir la solicitud del cliente en una operación específica de Docker.
Por ejemplo: la operación y gestión de objetos específicos como espejos, contenedores, redes y volúmenes montados.
Desde el nacimiento de Docker, el servidor ha sufrido muchas reestructuraciones. Al principio, todos los componentes del servidor estaban integrados en el binario de la ventana acoplable. Pero desde la versión 1.11, dockerd se ha convertido en un binario independiente. En este momento, el contenedor no es iniciado directamente por dockerd, sino que integra múltiples componentes como containerd y runC.
Aunque la arquitectura de Docker se refactoriza constantemente, las funciones básicas y el posicionamiento de cada módulo no han cambiado. Es lo mismo que un sistema de arquitectura C / S general. El módulo del lado del servidor de Docker es responsable de interactuar con el cliente de Docker y administrar los recursos de Docker, como contenedores, imágenes y redes.
Componentes importantes de Docker
Docker tiene dos componentes vitales: runC y containerd.
runC es una implementación oficial de Docker según el estándar de tiempo de ejecución del contenedor OCI. En términos simples, runC es una herramienta liviana que se usa para ejecutar contenedores, y realmente se usa para ejecutar contenedores.
Containerd es un componente central del servidor Docker. Se despojó de dockerd. Su nacimiento sigue completamente el estándar OCI y es el producto de la estandarización de contenedores. Containerd inicia y gestiona runC a través de containerd-shim Se puede decir que containerd realmente gestiona el ciclo de vida del contenedor.
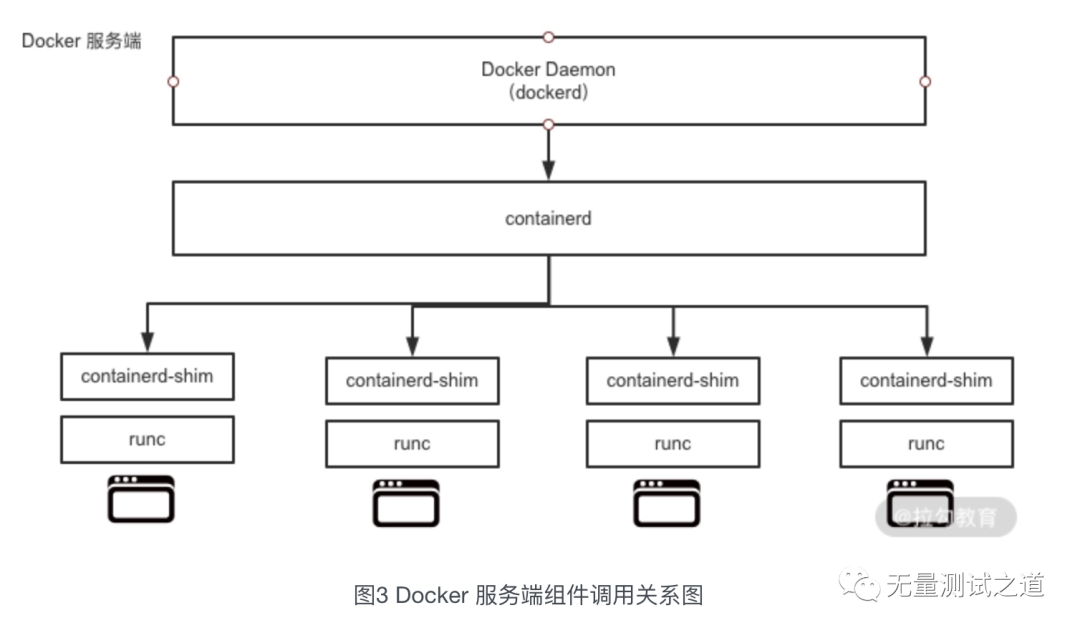
Como se puede ver en la Figura 3, dockerd se comunica con containerd a través de gRPC. Debido a que dockerd se ejecuta con un contenedor real, hay una capa estándar de OCI de containerd en el medio de runC, de modo que dockerd puede garantizar que la interfaz sea compatible con versiones anteriores.
gRPC es una llamada de servicio remoto. Para obtener más información, consulte https://grpc.io
containerd-shim, que significa una arandela, que es similar a una arandela intercalada entre un tornillo y una tuerca al atornillar un tornillo.
La función principal de containerd-shim es desacoplar containerd del proceso de contenedor real y usar containerd-shim como el proceso principal del proceso de contenedor, de modo que reiniciar dockerd no afecte el proceso de contenedor ya iniciado.
Después de comprender la relación entre dockerd, containerd y runC, puede iniciar un contenedor Docker para verificar la relación entre sus procesos.
La relación entre los componentes de Docker
Tome la versión 18.09.2 de Docker como ejemplo (si el siguiente comando no genera el resultado esperado cuando se ejecuta, puede ser un problema con la versión de Docker):
Primero, inicie un contenedor docker101tutorial con el siguiente comando:
$ docker run -d docker101tutorial sleep 5000Una vez iniciado el contenedor, verifique el PID de dockerd con el siguiente comando:
$ sudo ps aux |grep dockerd
root 4247 0.3 0.2 1447892 83236 ? Ssl Jul09 245:59 /usr/bin/dockerdDe la salida anterior, podemos saber que el PID de dockerd es 4247. Para verificar la relación de llamada entre los componentes de Docker en la figura anterior, use el comando pstree para verificar la relación padre-hijo del proceso:
$ sudo pstree -l -a -A 4247
dockerd
|-containerd --config /var/run/docker/containerd/containerd.toml --log-level info
| |-containerd-shim -namespace moby -workdir /var/lib/docker/containerd/daemon/io.containerd.runtime.v1.linux/moby/d14d20507073e5743e607efd616571c834f1a914f903db6279b8de4b5ba3a45a -address /var/run/docker/containerd/containerd.sock -containerd-binary /usr/bin/containerd -runtime-root /var/run/docker/runtime-runc
| | |-sleep 5000De hecho, cuando se inicia dockerd, se inicia containerd, y dockerd y containerd siempre existen.
Al ejecutar el comando docker run (crear e iniciar el contenedor a través de la imagen docker101tutorial), containerd creará containerd-shim para actuar como un proceso "shim" y luego iniciará el proceso real sleep 5000 del contenedor. A partir de esto, parece que este proceso es completamente consistente con el diagrama de arquitectura.
El contenido anterior es todo lo que se comparte hoy. Necesita dominar los conceptos de diseño centrales de la arquitectura de Docker: el principio de duplicación, contenedores y almacenes para poder usar y utilizar mejor Docker.
Bienvenido a prestar atención a la cuenta pública de [The Way of Infinite Testing], responder a [recibir recursos],
recursos de aprendizaje de programación de Python productos secos, automatización de la interfaz de usuario de la aplicación del marco Python + Appium , automatización de la interfaz de usuario web del marco Python + Selenium, API del marco Python + Unittest automatización,
Los recursos y códigos se envían gratis ~
Hay un código QR de la cuenta oficial en la parte inferior del artículo, puede escanearlo en WeChat y seguirlo.
Observaciones: Mi cuenta pública personal se ha abierto oficialmente, dedicada al intercambio de tecnología de prueba, que incluye: pruebas de big data, pruebas funcionales, desarrollo de pruebas, automatización de la interfaz API, operación y mantenimiento de pruebas, pruebas de automatización de la interfaz de usuario, etc., búsqueda pública de WeChat cuenta: "Wuliang The Way of Testing", o escanee el código QR a continuación:
¡Presta atención y crezcamos juntos!