premisa
Durante el proceso de ajuste, use
explaincomandos para ver el proceso de ejecución, incluido el tiempo de ejecución, el modo de escaneo, si se usan índices, etc., EXPLIQUE el análisis de uso
开启查询sql执行时间:
\timing on
关闭查询sql执行时间:
\timing off
1. Descripción del problema
Se llama con frecuencia a una interfaz de consulta y el proceso de consulta es lento
2. Ideas de optimización
- Primero considere optimizar las declaraciones SQL
- En segundo lugar, considere optimizar el código comercial
- Finalmente, considere si necesita agregar un mecanismo de almacenamiento en caché
3. Proceso de optimización
3.1 Optimizar SQL
SQL original, datos de consulta de grupo con el seq_id más grande en cada grupo, úselo en + group by para lograr
select name, version from yc_test where seq_id in(
select max(seq_id) from yc_test group by name
);
3.1.1 Ideas de optimización de SQL
- Considere agregar índices para acelerar la consulta
inSe convertiráory convertiráunion all, la eficiencia es menor. Considere usarexistsojoinreemplazar. ¿Por qué?
3.1.2 SQL optimizado
select a.name, a.version from yc_test a inner join (
select max(seq_id) as seq_id from yc_test group by name
) b on a.seq_id=b.seq_id;
3.1.3 Comparación antes y después de la optimización de SQL
explicar:
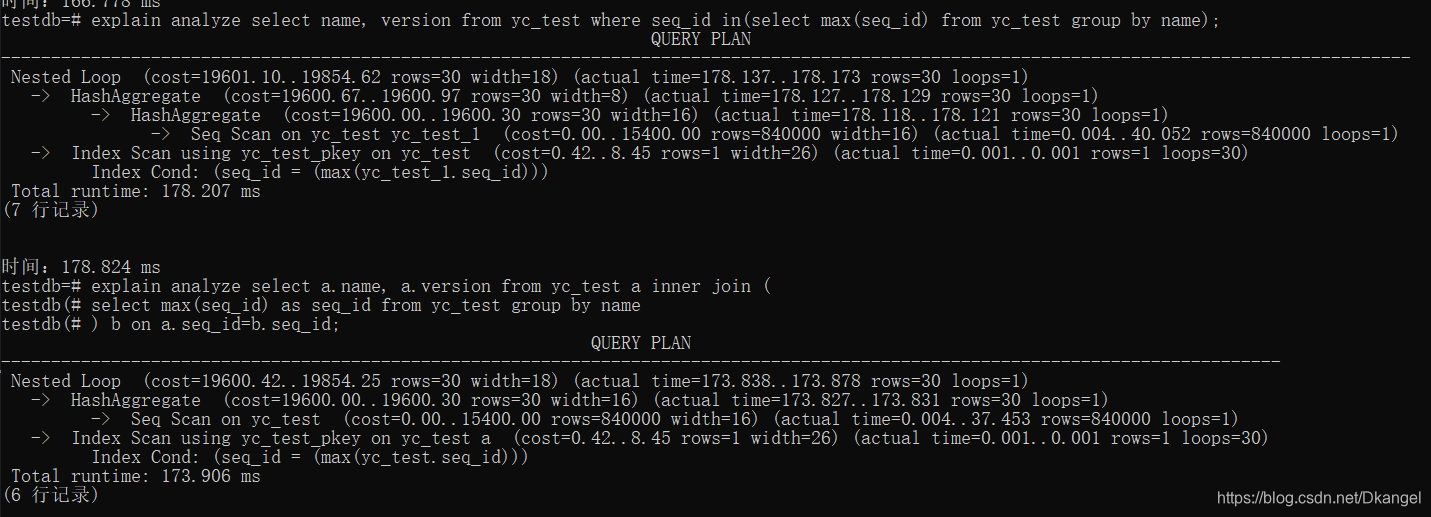
| sql | ventaja | Desventaja |
|---|---|---|
| en implementación | sql simple | in se convertirá en o y luego en union all, que es menos eficiente, como se muestra en la figura para una capa adicional de bucle |
| implementación de unión interna | Reducir una capa de circulación y mejorar la eficiencia. | Por el contrario, SQL es más complicado |
3.2 Optimizar el código comercial
Combinando escenarios comerciales funcionales (que pueden entenderse como registros históricos), leyó el código y descubrió que no todos los datos deben conservarse.
Solución de optimización:
定时器Limpie periódicamente los datos caducados para reducir la redundancia de datos业务逻辑Controle, juzgue si hay datos adicionales al guardar datos y elimine los datos adicionales si los hay.
3.3 Agregar mecanismo de almacenamiento en caché
热点数据, Puede considerar el almacenamiento en caché en la memoria (caché de variables) o el almacenamiento en la base de datos (Redis / Memcached)
Dado que la cantidad de datos se ha controlado y combinado con la planificación posterior, no se ha agregado ningún mecanismo de almacenamiento en caché.