El siguiente contenido se reproduce de https://www.toutiao.com/i6938300453767676455/
Gen intermitente 2021-03-11 15:53:07

[Nota del editor] Git es actualmente el sistema de control de versiones más popular. Desde el desarrollo local hasta la implementación de producción, usamos Git para nuestro control de versiones todos los días. Además de los comandos diarios, si desea tener una comprensión más profunda de Git Understand, luego, estudiar los principios de almacenamiento subyacentes de Git será muy útil para comprender Git y su uso. Incluso si no eres un desarrollador de Git, se recomienda que comprendas los principios subyacentes de Git. Tendrás un nuevo poder de Git. Comprenderá y será más útil en el proceso de uso diario de Git.
Este artículo está dirigido a lectores que tienen cierto conocimiento de Git. No presentará el rol y uso específicos de Git, ni presentará las diferencias con otros sistemas de control de versiones como Subversion. Principalmente presenta Git. La esencia de y los principios relacionados de su implementación de almacenamiento están diseñados para ayudar a los usuarios de Git a tener una comprensión más clara de su implementación interna cuando usan Git para el control de versiones.
Cual es la esencia de Git
Git es esencialmente una base de datos de valor-clave con dirección de contenido. Podemos insertar cualquier tipo de contenido en el repositorio de Git, y Git nos devolverá un valor de clave único. Podemos usar esta clave para recuperar el valor que insertamos en ese momento. Puede probarlo a través del comando subyacente git hash-object command:
➜ Zoker git:(master) ✗ cat testfile
Hello Git
➜ Zoker git:(master) ✗ git hash-object testfile -w
9f4d96d5b00d98959ea9960f069585ce42b1349a
Puede ver que hay un archivo llamado testfile en nuestro directorio. ¡El contenido es Hello Git! Usamos el comando git hash-object para escribir el contenido de este archivo en el repositorio de Git. La opción -w le dice a Git que escriba este contenido al directorio de base de datos de objetos Git. git / objects, y Git devolvió un valor SHA, este valor SHA es el valor clave del archivo que recuperaremos más adelante:
➜ Zoker git:(master) ✗ git cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git
Usamos el comando git cat-file para recuperar el contenido que se acaba de guardar en el repositorio de Git. Aunque no es tan intuitivo como el comando de Redis get set, de hecho es una base de datos KV, ¿verdad?
Los datos que acabamos de intentar insertar son un objeto básico de tipo blob. Git también tiene otros tipos de objetos como árbol y confirmación. Estos diferentes tipos de objetos tienen relaciones de asociación específicas y asocian lógicamente diferentes objetos. Solo cuando nos levantamos podemos controlar y echa un vistazo a las diferentes versiones. Más adelante ampliaremos estos diferentes tipos de objetos Primero comprendamos la estructura de directorios de Git y veamos cómo se almacenan los datos en Git.
Estructura de directorio de Git
A través de la introducción en la sección anterior, sabemos que Git es esencialmente una base de datos KV, y también mencionamos que el contenido se escribe en el directorio de objetos .git / objects, entonces, ¿dónde está ubicado este directorio? ¿Cómo almacena Git estos datos? En esta sección, nos enfocamos en la estructura del directorio de almacenamiento de Git y entendemos cómo Git almacena diferentes tipos de datos.
Para obtener una introducción más detallada, consulte:
https://github.com/git/git/blo ... t.txt
A través de git init podemos inicializar un almacén de Git vacío en el directorio actual. Git generará automáticamente un directorio .git. Este directorio .git es el centro de almacenamiento para todos los metadatos de Git posteriores. Echemos un vistazo a su estructura de directorios:
➜ Zoker git init
Initialized empty Git repository in /Users/zoker/tmp/Zoker/.git/
➜ Zoker git:(master) ✗ tree .git
.git
├── HEAD // 是一个符号引用,指明当前工作目录的版本引用信息,我们平时执行 checkout 命令时就会改变 HEAD 的内容
├── config // 配置当前存储库的一些信息,如:Proxy、用户信息、引用等,此处的配置项相对于全局配置权重更高
├── description // 仓库描述信息
├── hooks // 钩子目录,执行 Git 相关命令后的回调脚本,默认会有一些模板
│ ├── update.sample
│ ├── pre-receive.sample
│ └── ...
├── info // 存储一些额外的仓库信息如 refs、exclude、attributes 等
│ └── exclude
├── objects // 元数据存储中心
│ ├── info
│ └── pack
└── refs // 存放引用信息,也就是分支、标签
├── heads
└── tags
El almacén de Git generado por la inicialización predeterminada solo tiene estos archivos. Además, hay algunos otros tipos de archivos y directorios, como registros de módulos de refs empaquetados, etc. Estos archivos tienen usos específicos y son solo después de operaciones o configuraciones específicas. , aquí solo nos enfocamos en la implementación del almacenamiento central, la función de estos archivos o directorios adicionales y los escenarios de uso pueden luego navegar por los documentos por sí mismos, aquí solo presentamos algunos de los archivos principales.
directorio de ganchos
El directorio de ganchos almacena principalmente ganchos de Git. Los ganchos de Git se pueden activar después o antes de que ocurran muchos eventos, lo que nos puede proporcionar una forma muy flexible de usarlos. De forma predeterminada, todos tienen el sufijo .sample. Necesita eliminar este sufijo y Dar permisos ejecutables para que surtan efecto. A continuación, se muestran algunos ganchos de uso común y sus usos comunes:
Gancho del cliente:
- compromiso previo: se activa antes del envío, como verificar si la información enviada está estandarizada, si la prueba se completó y si el formato del código cumple con los requisitos
- post-commit: por el contrario, esto se activa después de que se completa todo el envío y se puede usar para enviar notificaciones
Gancho del servidor:
- pre-recibir: el script que se llama primero cuando el servidor recibe la solicitud de inserción y puede detectar si estas referencias de inserción cumplen con los requisitos
- actualización: similar a la pre-recepción, pero la pre-recepción solo se ejecutará una vez, y la actualización se ejecutará una vez para cada rama empujada
- post-recepción: se activa después de que se completa todo el proceso de envío, se puede utilizar para enviar notificaciones, activar el sistema de compilación, etc.
directorio de objetos
Como mencionamos en la sección anterior, Git almacena todos los archivos de objetos de generación de contenido recibidos en este directorio. Generamos un objeto a través de git hash-object y lo escribimos en el almacén de Git. El valor clave de este objeto es
9f4d96d5b00d98959ea9960f069585ce42b1349a, esto Cuando miramos en la estructura del directorio de objetos:
➜ Zoker git:(master) ✗ git hash-object testfile -w
9f4d96d5b00d98959ea9960f069585ce42b1349a
➜ Zoker git:(master) ✗ tree .git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── info
└── pack
Puede ver que el directorio de objetos tiene contenido nuevo. Hay una carpeta 9f adicional y archivos en él. Este archivo es el archivo de objeto insertado en el repositorio de Git. Git toma las dos primeras letras de su valor clave como la carpeta, y almacena las siguientes letras como el nombre de archivo del archivo de objeto. Los objetos almacenados aquí (es decir, objetos / [0-9a-f] [0-9a-f]) generalmente se denominan objetos sueltos u objetos desempaquetados. objeto.
Además de la carpeta de almacenamiento de objetos, los estudiantes cuidadosos deberían haber notado la existencia de la carpeta objetos / paquete, que corresponde a los archivos empaquetados. Para ahorrar espacio y mejorar la eficiencia, cuando hay demasiados archivos de objetos sueltos o al ejecutar manualmente el comando git gc, o durante el proceso de transferencia de empujar y tirar, Git empaquetará estos archivos de objetos sueltos en archivos de paquete para mejorar la eficiencia. Aquí están estos archivos empaquetados:
➜ objects git:(master) git gc
...
Compressing objects: 100% (75/75), done.
...
➜ objects git:(master) tree
.
├─ pack
├── pack-fe24a22b0313342a6732cff4759bedb25c2ea55d.idx
└── pack-fe24a22b0313342a6732cff4759bedb25c2ea55d.pack
└── ...
Puede ver que no hay objetos sueltos en el directorio de objetos. En su lugar, hay dos archivos en el directorio del paquete. Uno es el archivo empaquetado y el otro es el archivo idx que indexa el contenido empaquetado. Es conveniente consultar si un El objeto está en este En el paquete correspondiente.
Cabe señalar que si GC se realiza en un almacén de un objeto blob que acabamos de crear manualmente, no producirá ningún efecto, porque en este momento, todo el almacén de Git no tiene ninguna referencia a este objeto. que este objeto es libre, vamos a introducir el directorio donde se almacena la referencia.
directorio de referencias
El directorio refs almacena nuestras referencias. La referencia se puede considerar como un alias a un número de versión. De hecho, almacena el valor SHA de una determinada confirmación. El almacén que usamos para las pruebas anteriores no tiene ninguna confirmación, por lo que solo hay una. estructura de directorios.
└── refs
├── heads
└── tags
Encontramos aleatoriamente un repositorio que contiene confirmaciones para ver su maestro de rama predeterminado.
➜ .git git:(master) cat refs/heads/master
87e917616712189ecac8c4890fe7d2dc2d554ac6
Puede ver que la referencia maestra solo almacena un valor Commit SHA. La ventaja, por supuesto, es que no necesitamos recordar la cadena larga de valores SHA. Solo necesitamos usar el alias maestro para obtener esta versión. El mismo directorio de etiquetas almacena nuestras etiquetas. A diferencia de las ramas, los valores de referencia registrados de las etiquetas generalmente no cambian, pero las ramas pueden cambiar con nuestra versión. Además, también puede ver directorios como refs / remotes refs / fetch, que almacenan referencias a espacios de nombres específicos.
Existe otra situación, que es el mecanismo de GC que mencionamos anteriormente. Si un almacén ejecuta GC, no solo se empaquetarán los objetos sueltos en el directorio de objetos, sino que también se empaquetarán las referencias bajo refs, pero se almacenarán en el almacén desnudo. El directorio raíz de .git / pack-refs
➜ .git git:(master) cat packed-refs
# pack-refs with: peeled fully-peeled sorted
87e917616712189ecac8c4890fe7d2dc2d554ac6 refs/heads/master
Cuando necesitemos acceder al maestro de rama, Git primero buscará en refs / heads. Si no puede encontrarlo, irá a .git / pack-refs para buscar. Empaquetar todas las referencias en un archivo sin duda mejorará mucho eficiencia. Cabe señalar que si actualizamos algunas confirmaciones en la rama maestra en este momento, Git no modificará directamente el archivo .git / pack-refs en este momento, sino que recreará directamente una referencia maestra en refs / heads /. Contiene el Valor SHA de la última confirmación. De acuerdo con el mecanismo de Git que acabamos de presentar, Git primero buscará en refs / heads / y luego irá a .git / pack-refs si no se puede encontrar.
Entonces, ¿a qué se refiere el valor SHA del Commit almacenado en la referencia? Podemos usar el comando cat-file para ver el contenido del objeto blob para ver:
➜ .git git:(master) git cat-file -p 87e917616712189ecac8c4890fe7d2dc2d554ac6
tree aab1a9217aa6896ef46d3e1a90bc64e8178e1662 // 指向的 tree 对象
parent 7d000309cb780fa27898b4d103afcfa95a8c04db // 父提交
author Zoker <[email protected]> 1607958804 +0800 // 作者信息
committer Zoker <[email protected]> 1607958804 +0800 // 提交者信息
test ssh // 提交信息
Es un objeto de tipo de confirmación, los atributos principales son el objeto de árbol al que apunta, su confirmación principal (si es la primera confirmación, luego 0000000 ...), el autor y la información de confirmación.
Entonces, ¿cuál es el objeto de confirmación? ¿Cuál es el objeto de árbol al que apunta? ¿Cuál es la diferencia con el objeto blob que creamos manualmente antes? A continuación, hablemos de los objetos de almacenamiento de Git.
Objetos de almacenamiento de Git
En el mundo Git, hay cuatro tipos de objetos de almacenamiento: archivo (blob), árbol (árbol), compromiso (compromiso), etiqueta (etiqueta), aquí discutimos principalmente los primeros tres tipos, porque estos tres son los Git más básicos metadatos, y el objeto de etiqueta es solo una etiqueta que contiene información de atributo adicional, es decir, una etiqueta anotada, por lo que no introduciré demasiado aquí.
Introducción a las etiquetas ligeras y anotadas:
https://git-scm.com/book/zh/v2 ...% 25BE
Objeto blob
Al introducir la esencia de Git, para demostrar que Git es una base de datos KV basada en el direccionamiento de contenido, insertamos el contenido de un archivo en el repositorio de Git:
➜ Zoker git:(master) ✗ cat testfile
Hello Git
➜ Zoker git:(master) ✗ git hash-object testfile -w
9f4d96d5b00d98959ea9960f069585ce42b1349a
El
objeto Git cuya clave es 9f4d96d5b00d98959ea9960f069585ce42b1349a es en realidad un objeto Blob, que almacena el valor del archivo de prueba. Podemos usar el comando cat-file para ver:
➜ Zoker git:(master) ✗ git cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git
Cada vez que modificamos un archivo, Git guardará una instantánea completa del archivo en lugar de registrar las diferencias, por lo que si modificamos el contenido del archivo de prueba y lo guardamos en el repositorio de Git nuevamente, Git lo generará en base a la última versión actual. content Its Key, cabe señalar que cuando el contenido no cambia, su valor de Key es fijo Después de todo, como dijimos antes, Git es una base de datos KV basada en direccionamiento de contenido.
Además, el objeto Blob almacena aquí contenido de texto, también puede ser contenido binario, pero no se recomienda usar Git para administrar la versión del archivo binario. El problema más común que encuentra nuestra plataforma Gitee en el proceso de operación diaria es que el almacén del usuario es demasiado grande. Esta situación generalmente se debe a que el usuario envía un archivo binario grande, porque cada cambio de archivo se registra como una instantánea, por lo que este binario file Si los cambios son frecuentes, el espacio que ocupa se duplica. Y para los blobs de contenido de texto, Git solo guardará las diferencias de archivo entre los dos envíos durante el proceso de GC, lo que puede ahorrar espacio, pero para los blobs de contenido binario, no se puede manejar como blobs de contenido de texto. contenido binario en el repositorio de Git. Puede usar LFS para almacenarlo. Si ya tiene una gran cantidad de archivos binarios, puede usar filter-branch para perder peso. Los nuevos colegas definitivamente lo apreciarán cuando clonen el almacén por primera vez.
El uso de LFS:
https://gitee.com/help/articles/4235, el adelgazamiento del gran almacén: https://gitee.com/help/articles/4232, la rama de filtro: https: // github .com / git / git / blo ... h.txt
¿Crees que algo anda mal cuando llegas aquí? Así es, este objeto Blob solo almacena el contenido de este archivo, pero no registra el nombre del archivo, entonces, ¿cómo sabemos a qué archivo pertenece este contenido? La respuesta es otro objeto importante de Git: el objeto Tree.
Objeto de árbol
En Git, la función principal del objeto Tree es organizar múltiples Blobs o objetos Tree secundarios juntos, y todo el contenido se almacena mediante objetos de tipo Tree y Blob. Un objeto de árbol contiene una o más entradas de árbol (registros de objeto de árbol), y cada registro de objeto de árbol contiene un puntero al valor de Blob o subárbol SHA, así como sus correspondientes nombres de archivo y otra información, que de hecho se puede entender Para indexar la relación entre inodo y bloque en el sistema de archivos, si se muestra un objeto Tree, como se muestra a continuación:
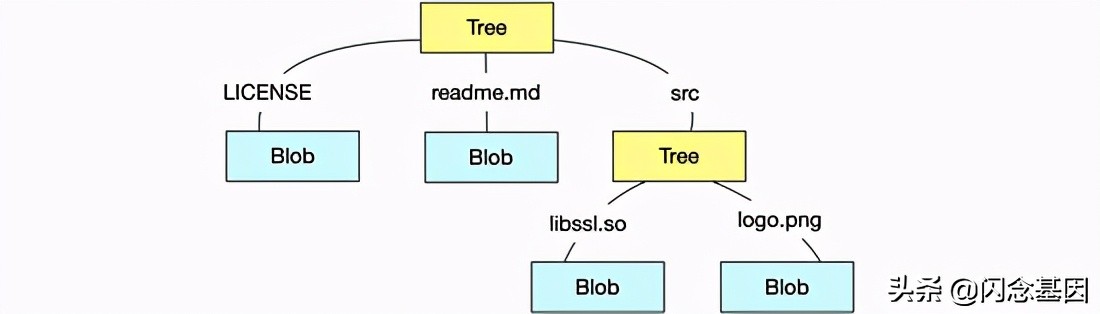
La estructura de directorios correspondiente a este objeto Árbol es la siguiente:
.
├── LICENSE
├── readme.md
└── src
├── libssl.so
└── logo.png
De esta manera, podemos almacenar el contenido de nuestro almacén de una manera estructurada como la forma de organizar directorios en Linux, considerar Tree como una estructura de directorio y Blob como contenido de archivo específico.
Entonces, ¿cómo crear un objeto de árbol? En Git, el objeto Tree correspondiente se crea de acuerdo con el estado del área de preparación. El área de preparación aquí es en realidad el área de preparación (En etapas) que entendemos en el proceso diario de uso de Git. Generalmente, usamos el comando git add para agregar Algunos archivos se agregan al área de preparación para ser enviados. En un almacén vacío sin ningún envío, el estado de esta área de preparación son los archivos que agregó a través de git add, como:
➜ Zoker git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: LICENSE
new file: readme.md
Untracked files:
(use "git add <file>..." to include in what will be committed)
src/
El estado actual del área de ensayo aquí es que hay dos archivos en el directorio raíz. El estado del área de ensayo se guarda en el archivo .git / index. Usemos el comando de archivo para ver qué es:
➜ Zoker git:(master) ✗ file .git/index
.git/index: Git index, version 2, 2 entries
Puede encontrar que hay dos entradas en el archivo de índice, es decir, los dos archivos LICENCIA y readme.md en el directorio raíz. Para un almacén que se ha enviado, si no hay contenido en el área de almacenamiento temporal, este índice representa la versión actual del estado del árbol de directorios. Si los archivos se modifican o eliminan y se agrega el área de almacenamiento temporal, el índice cambiar, el puntero del archivo relacionado apunta al valor SHA del nuevo objeto Blob del archivo.
Entonces, si queremos crear un objeto Tree, necesitamos poner algo en el área de preparación. Además de usar git add, también podemos usar el comando subyacente update-index para crear un área de preparación. A continuación, creamos un objeto de árbol basado en el archivo testfile que se ha creado anteriormente. El primero es agregar el archivo testfile al área de almacenamiento temporal:
➜ Zoker git:(master) ✗ git update-index --add testfile // 与 git add testfile 一样
➜ Zoker git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: testfile
En este proceso, Git inserta principalmente el contenido del archivo de prueba en el almacén de Git en forma de Blob y luego registra el valor SHA del Blob devuelto en el índice, indicándole al área de almacenamiento temporal qué contenido del archivo se encuentra actualmente.
➜ Zoker git:(master) ✗ tree .git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── info
└── pack
3 directories, 1 file
➜ Zoker git:(master) ✗ git cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git
Cuando Git ejecuta el comando update-index, almacena el contenido del archivo especificado como un objeto Blob y lo registra en el estado del archivo de índice. Dado que hemos insertado el contenido de este archivo a través del comando git hash-object anteriormente, y podemos encontrar que debido a que el contenido no ha cambiado, el valor SHA del objeto Blob generado también es el mismo, si ya lo hemos insertado como nosotros. Los siguientes comandos son equivalentes:
git update-index --add --cacheinfo 9f4d96d5b00d98959ea9960f069585ce42b1349a testfile
Este comando realmente coloca el objeto Blob generado previamente en el área de almacenamiento temporal y especifica su nombre de archivo como archivo de prueba. Dado que nuestra área de ensayo ya tiene un archivo de prueba, podemos usar el comando git write-tree para crear un objeto de árbol basado en el estado actual del área de ensayo:
➜ Zoker git:(master) ✗ git write-tree
aa406ee8804971cf8edfd8c89ff431b0462e250c
➜ Zoker git:(master) ✗ tree .git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── aa
│ └── 406ee8804971cf8edfd8c89ff431b0462e250c
├── info
└── pack
Después de ejecutar el comando, Git generará un
objeto Tree con un valor SHA de aa406ee8804971cf8edfd8c89ff431b0462e250c en función del estado del área de ensayo actual y almacenará este objeto Tree en el directorio .git / objects como un objeto Blob.
➜ Zoker git:(master) ✗ git cat-file -p aa406ee8804971cf8edfd8c89ff431b0462e250c
100644 blob 9f4d96d5b00d98959ea9960f069585ce42b1349a testfile
Use el comando cat-file para ver este objeto de árbol, puede ver que solo hay un archivo bajo este objeto, llamado testfile.

Continuamos creando el segundo objeto Árbol. Necesitamos el archivo de prueba modificado debajo del segundo objeto Árbol, el nuevo archivo testfile2 y el primer objeto Árbol como directorio duplicado del segundo objeto Árbol. Primero, primero agregamos el archivo de prueba modificado y el archivo testfile2 recién agregado al área de almacenamiento temporal:
➜ Zoker git:(master) ✗ git update-index testfile
➜ Zoker git:(master) ✗ git update-index --add testfile2
➜ Zoker git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: testfile
new file: testfile2
Luego necesitamos colgar el primer objeto Tree en el directorio duplicado, podemos usar el comando read-tree para lograr:
➜ Zoker git:(master) ✗ git read-tree --prefix=duplicate aa406ee8804971cf8edfd8c89ff431b0462e250c
➜ Zoker git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: duplicate/testfile
new file: testfile
new file: testfile2
Luego ejecutamos write-tree y vemos el segundo objeto Tree a través de cat-file:
➜ Zoker git:(master) ✗ git write-tree
64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
➜ Zoker git:(master) ✗ git cat-file -p 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
040000 tree aa406ee8804971cf8edfd8c89ff431b0462e250c duplicate
100644 blob 106287c47fd25ad9a0874670a0d5c6eacf1bfe4e testfile
100644 blob 098ffe6f84559f4899edf119c25d276dc70607cf testfile2
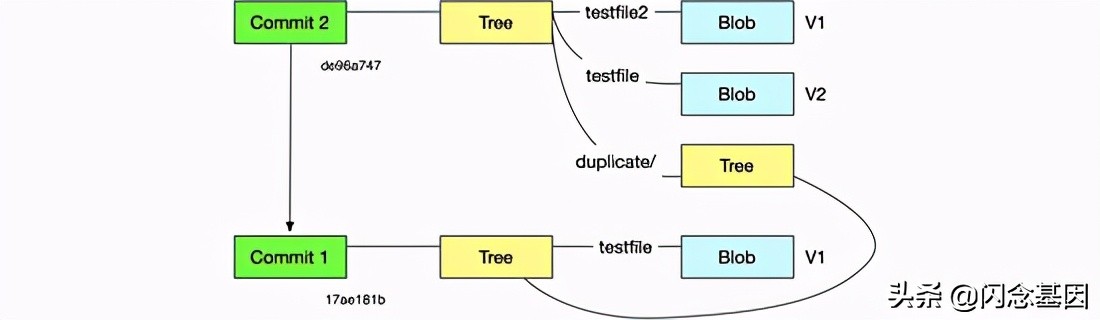
Completado con éxito, no solo modificamos el contenido del archivo de prueba, sino que también agregamos un nuevo archivo testfile2, y también tratamos el primer objeto Árbol como el directorio duplicado del segundo objeto Árbol. En este momento, el objeto Árbol se ve así de:

Hasta ahora, sabemos cómo crear manualmente un objeto de árbol, pero ¿qué pasa si necesito instantáneas de estos dos árboles diferentes más adelante? ¿No recuerdas los valores SHA de estos tres objetos Tree? Así es, se necesita mucho esfuerzo para recordar. La clave es que no sabemos quién creó esta instantánea en qué momento y para qué, y el objeto Commit (objeto de confirmación) puede ayudarnos a resolver este problema.
Confirmar objeto
El objeto Commit es principalmente para registrar información adicional de la instantánea y mantener la relación lineal entre las instantáneas. Podemos crear una confirmación a través del comando git commit-tree. Este comando significa literalmente que es un comando que se usa para enviar un objeto Tree como un objeto Commit:
➜ Zoker git:(master) ✗ git commit-tree -h
usage: git commit-tree [(-p <parent>)...] [-S[<keyid>]] [(-m <message>)...] [(-F <file>)...] <tree>
-p <parent> id of a parent commit object
-m <message> commit message
-F <file> read commit log message from file
-S, --gpg-sign[=<key-id>]
GPG sign commit
Los dos parámetros clave son -p y -m. -P especifica el envío principal de este envío. Si es el primer envío inicial, puede ignorarse aquí; -m especifica la información de este envío, que se utiliza principalmente para describir el motivo de la presentación. Usemos el primer objeto Tree como nuestro compromiso inicial:
➜ Zoker git:(master) ✗ git commit-tree -m "init commit" aa406ee8804971cf8edfd8c89ff431b0462e250c
17ae181bd6c3e703df7851c0f7ea01d9e33a675b
Utilice cat-file para ver este envío:
tree aa406ee8804971cf8edfd8c89ff431b0462e250c
author Zoker <[email protected]> 1613225370 +0800
committer Zoker <[email protected]> 1613225370 +0800
init commit
El contenido almacenado por Commit es un objeto de árbol y registra el confirmador, el tiempo de compromiso y la información de compromiso. Nos referimos al segundo objeto Árbol en función de este compromiso:
➜ Zoker git:(master) ✗ git commit-tree -p 17ae181bd -m "add dir" 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
de96a74725dd72c10693c4896cb74e8967859e58
➜ Zoker git:(master) ✗ git cat-file -p de96a74725dd72c10693c4896cb74e8967859e58
tree 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
parent 17ae181bd6c3e703df7851c0f7ea01d9e33a675b
author Zoker <[email protected]> 1613225850 +0800
committer Zoker <[email protected]> 1613225850 +0800
add dir
Podemos usar git log para ver estas dos confirmaciones, aquí agregue el parámetro --stat para ver el registro de cambio de archivo:
commit de96a74725dd72c10693c4896cb74e8967859e58
Author: Zoker <[email protected]>
Date: Sun Feb 13 22:17:30 2021 +0800
add dir
duplicate/testfile | 1 +
testfile | 2 +-
testfile2 | 1 +
3 files changed, 3 insertions(+), 1 deletion(-)
commit 17ae181bd6c3e703df7851c0f7ea01d9e33a675b
Author: Zoker <[email protected]>
Date: Sun Feb 13 22:09:30 2021 +0800
init commit
testfile | 1 +
1 file changed, 1 insertion(+)
En este momento, la estructura de todo el objeto es la siguiente:
Ejercicio: use comandos de bajo nivel para crear una confirmación
Solo use los comandos de bajo nivel como hash-object write-tree read-tree commit-tree que mencionamos anteriormente para crear una confirmación, y piense qué proceso es equivalente a git add git commit.
Método de almacenamiento de objetos
A través de la introducción anterior, sabemos que Git resume datos en diferentes tipos de objetos y calcula un valor SHA basado en el contenido que se utilizará como direccionamiento. Entonces, ¿cómo se calcula? Tomando el objeto Blob como ejemplo, Git realiza principalmente los siguientes pasos:
- Identifique el tipo de objeto, construya la información del encabezado, use el tipo + bytes de contenido + bytes nulos como información del encabezado, como blob 151 \ u0000
- Empalme la información del encabezado con el contenido y calcule la suma de comprobación SHA-1
- Comprimir contenido a través de zlib
- Pon su contenido en el directorio de objetos correspondiente por valor SHA
Estas cosas se hacen en todo el proceso. El objeto Tree y el objeto Commit son similares, excepto que el tipo de cabeza es diferente. No entraré en detalles aquí. "Pro Git 2" presenta cómo usar Ruby para lograr lo mismo en el capítulo sobre principios internos de Git. Lógica, los interesados pueden leerlo por sí mismos.
Principio interno de Git:
https://git-scm.com/book/zh/v2 ...% 25A1
Referencias de Git
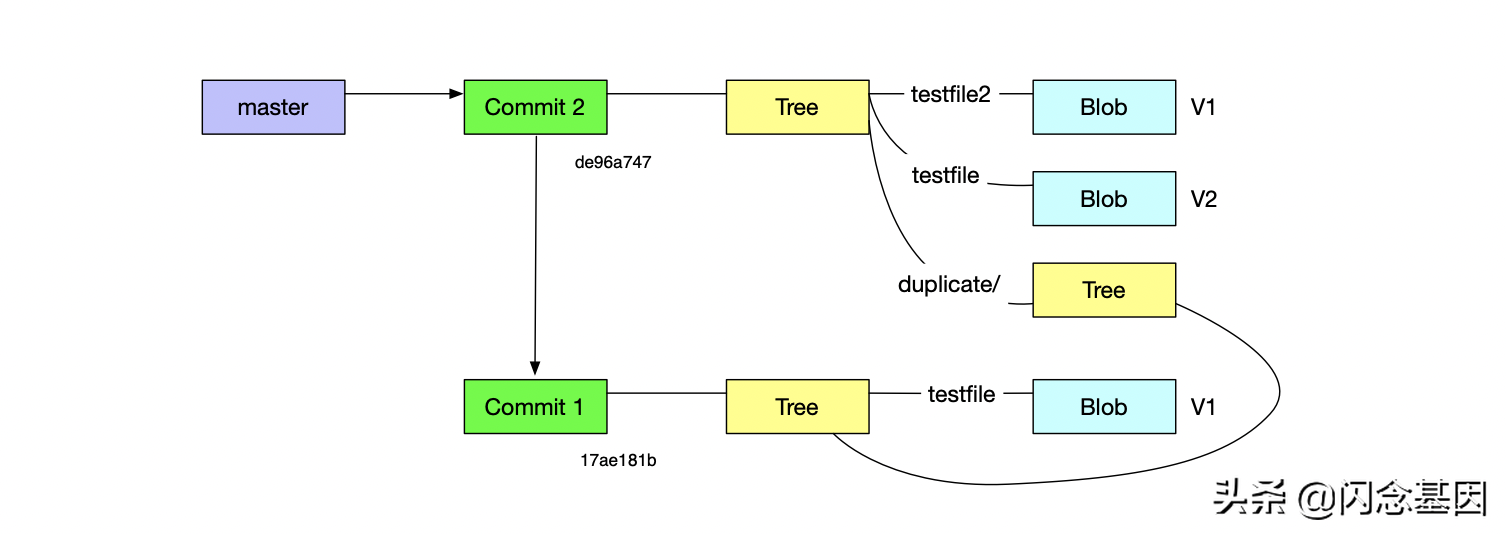
Podemos ver la información relevante de la primera versión a través de git log --stat 17ae181b anterior, y podemos obtener el contenido de esta instantánea a través de esta cadena de valores SHA, pero sigue siendo muy problemático, porque tenemos que recordar que la cadena es Sin sentido En este momento, la referencia de Git es útil. En el capítulo de estructura de directorios de Git, hemos introducido el directorio refs. Sabemos que el valor clave del objeto Commit se almacena en la referencia, que es el valor SHA del objeto De esta manera, le daremos a nuestra versión actual un nombre significativo, y generalmente usaremos master como la referencia de rama predeterminada:
➜ Zoker git:(master) ✗ echo "17ae181bd6c3e703df7851c0f7ea01d9e33a675b" >> .git/refs/heads/master
➜ Zoker git:(master) ✗ tree .git/refs
.git/refs
├── heads
│ └── master
└── tags
En este momento, el valor SHA de nuestra primera confirmación se almacena en el maestro y podemos usar el maestro para reemplazar la cadena sin sentido de 17ae181b.
➜ Zoker git:(master) ✗ git cat-file -p master
tree aa406ee8804971cf8edfd8c89ff431b0462e250c
author Zoker <[email protected]> 1613916447 +0800
committer Zoker <[email protected]> 1613916447 +0800
init commit
Sin embargo, esta no es nuestra última versión. Nuestra última versión es el segundo envío
de96a74725dd72c10693c4896cb74e8967859e58. De manera similar, podemos cambiar el contenido de refs / heads / master al valor SHA de este envío, pero aquí usamos un comando de bajo nivel. Carry afuera.
➜ Zoker git:(master) ✗ git update-ref refs/heads/master de96a74725dd72c10693c4896cb74e8967859e58
➜ Zoker git:(master) ✗ cat .git/refs/heads/master
de96a74725dd72c10693c4896cb74e8967859e58
En este momento, el maestro de la sucursal apunta a nuestra última versión.
para resumir
Lo anterior analiza principalmente los principios básicos de almacenamiento y algunas implementaciones de Git, así como algunos como el empaquetado de paquetes, el mecanismo de negociación de transmisión y el formato de almacenamiento. Debido a limitaciones de espacio, no hablaremos de ellos. Los discutiremos más adelante en base a algunos escenarios.
Autor: Zoker
https://zoker.io/blog/talk-about-git-internals