Productos secos | El principio y la implementación de la monitorización de flujo de Kafka
Dean Lang Langjian habla sobre big data
Capacidad de ingeniería
Como desarrollador excelente, la confiabilidad del sistema de monitoreo y advertencia en el proceso de desarrollo del proyecto puede reflejar la capacidad de gestión de ingeniería de una persona. Un excelente sistema de monitoreo y advertencia puede ahorrar una gran cantidad de consumo de energía, como mantenimiento, predicción de fallas, notificación de fallas oportuna y precisa, localización de fallas y resolución de problemas, etc.
Puede imaginar lo terrible que es esa caja negra si no hay un sistema de monitoreo y advertencia después de que el proyecto se pone en línea.
Para proyectos de big data, los datos generalmente deben ingresar a una cola de mensajes, como kafka, y luego separar la línea y desacoplar los datos en tiempo real para el procesamiento en tiempo real y el procesamiento fuera de línea. Los beneficios de las colas de mensajes:
-
Los suscriptores de la cola de mensajes se pueden expandir en cualquier momento según sea necesario, lo que bien puede expandir los consumidores de datos.
-
La expansión horizontal de las colas de mensajes para aumentar el rendimiento sigue siendo muy simple. Sigue siendo muy problemático utilizar una base de datos y una subbase de datos y una tabla tradicionales.
- Debido a la existencia de colas de mensajes, también puede ayudarnos a resistir los picos y evitar una presión de procesamiento de back-end excesiva durante los períodos pico y todo el tiempo de inactividad del procesamiento de la empresa.
Kafka juega un papel importante en los proyectos de big data, por lo que sus alarmas de monitoreo son muy importantes. Estamos hablando principalmente de alarmas de monitoreo para el tráfico de Kafka. Su propósito también es muy obvio para ayudarnos a comprender la situación general y las fluctuaciones de los datos. Circunstancias para ajustar el backend de procesamiento, como la transmisión de chispas, el canal, etc.
Existen muchas herramientas de monitorización de kafka, las más habituales son kafka manager, KafkaOffsetMonitor, kafka eagle, kafka tools, etc. La más utilizada por Wavetip es kafka manager. También se recomienda utilizar esta herramienta, que no solo tiene funciones de monitorización sino también funciones de gestión. Para conocer los métodos de uso específicos, consulte:
Artefacto de gestión de Kafka -kafkamanager
Indicadores de seguimiento
El servidor y el cliente de indicadores de Kafka tienen ambos. Para obtener contenido de índice específico, consulte el sitio web oficial de kafka:
http://kafka.apache.org/0102/documentation.html#monitoring
La forma más fácil de ver las métricas disponibles es iniciar jconsole y apuntar a un cliente o servidor kafka en ejecución; esto permitirá examinar todas las métricas utilizando JMX.
Los amigos que están familiarizados con el administrador de Kafka deberían haber visto información relacionada con el corredor, como la cantidad de mensajes entrantes por segundo, el tamaño de los mensajes entrantes por segundo y el tamaño de los mensajes salientes.
Es muy conveniente utilizar kafka manager. Sin embargo, esto en realidad no nos permite descubrir las fluctuaciones del flujo de datos en el tiempo, o queremos dibujar una curva para comparar los flujos históricos en detalle, lo cual es imposible. Por lo tanto, tenemos que encontrar una manera de obtener estos indicadores y luego hacer nuestra propia visualización. Otro punto es la advertencia de fluctuación del tráfico.
Langjian solo hizo la interfaz de algunos indicadores en la figura:
def getBytesInPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "BytesInPerSec", topicOption)
}
def getBytesOutPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "BytesOutPerSec", topicOption)
}
def getBytesRejectedPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "BytesRejectedPerSec", topicOption)
}
def getFailedFetchRequestsPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "FailedFetchRequestsPerSec", topicOption)
}
def getFailedProduceRequestsPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "FailedProduceRequestsPerSec", topicOption)
}
def getMessagesInPerSec(kafkaVersion: KafkaVersion, mbsc: MBeanServerConnection, topicOption: Option[String] = None) = {
getBrokerTopicMeterMetrics(kafkaVersion, mbsc, "MessagesInPerSec", topicOption)
}cliente jmx
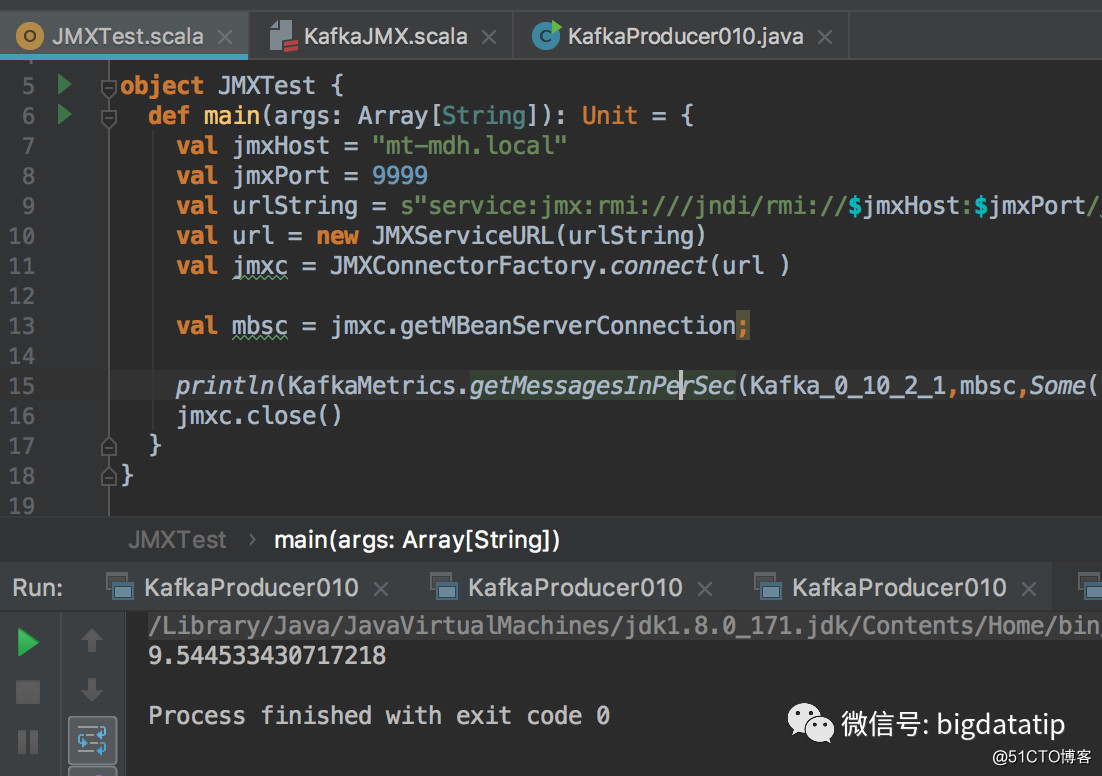
El servidor jmx puede usar jconsole, pero no puede satisfacer nuestras necesidades. Por lo tanto, usamos JMXConnectorFactory para conectarnos a jmx. Cuando se usa JMXConnectorFactory para vincular jmx, la URL del parámetro de JMXServiceURL debe conectarse usando el método service: jmx. El método específico de creación de enlaces es muy simple, solo unas pocas líneas de código, como sigue:
val jmxHost = "hostname"
val jmxPort = 9999
val urlString = s"service:jmx:rmi:///jndi/rmi://$jmxHost:$jmxPort/jmxrmi"
val url = new JMXServiceURL(urlString)
val jmxc = JMXConnectorFactory.connect(url )
val mbsc = jmxc.getMBeanServerConnection;
println(KafkaMetrics.getMessagesInPerSec(Kafka_0_10_2_1,mbsc,Some("test")).fifteenMinuteRate)
jmxc.close()Abra el puerto jmx de kafka
El servicio jmx de Kafka está desactivado por defecto. Es muy sencillo activarlo. Solo necesita agregar una línea de código al script de inicio kafka-server-start.sh del servidor kafka, con la exportación de contenido JMX_PORT = " 9999 ", y la ubicación agregada es la siguiente:
if [ "x$KAFKA_HEAP_OPTS" = "x"]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fiprueba
Mi prueba aquí es relativamente simple, principalmente para imprimir la cantidad de mensajes, puede ajustar según sus necesidades, por ejemplo, el valor promedio es mayor que el umbral para enviar alertas por SMS.
Este artículo es el segundo artículo para implementar el sistema de monitoreo de Kafka por mí mismo. El artículo anterior hablaba sobre cómo obtener la compensación presentada por el consumidor del corredor de Kafka. Para obtener más detalles, puede leer:
Cómo obtener la información del consumidor guardada por el corredor de Kafka ?
Un conjunto completo de monitoreo de Kafka, que incluye:
- El monitoreo del consumidor es principalmente para alarmas de supervivencia y alarmas de retraso de consumo.
- El monitoreo del productor es principalmente para alarmas de supervivencia y para que los productores consuman alarmas de capacidad de datos ascendentes.
- El monitoreo de agentes incluye principalmente alarmas de supervivencia, alarmas de tráfico, listas de isr, alarmas de temas anormales y alarmas de transformación de control.
Hay mucho contenido y los artículos se publicarán uno tras otro, por supuesto, todo el proyecto eventualmente se colocará en el planeta.