2021-03-29 01:10:58

Nota del editor: Hablando del maestro Li Hongyi, los lectores y amigos que están familiarizados con la IA ciertamente no serán desconocidos. Después del lanzamiento de GPT-3, el Sr. Li Hongyi explicó específicamente este modelo extraordinario, al que llamó "el modelo del Continente Oscuro del Cazador".
Con el fin de difundir el conocimiento, el "Practicante de datos" compiló las ideas del maestro Li Hongyi en un texto basado en el video explicativo, y lo eliminó y modificó según la intención original:
OpenAI ha publicado un nuevo modelo de lenguaje enorme. Antes de esto, OpenAI ha publicado GPT y el sensacional GPT-2, y ahora es GPT-3 (el artículo de GPT-3 se titula Language Models are Few-Shot Learners).
Entonces, ¿cuál es la diferencia entre GPT-3 y GPT-2? Básicamente no hay diferencia, todos son modelos de lenguaje. ¿Cuál es la parte mágica de GPT-3? La magia es que es demasiado grande.
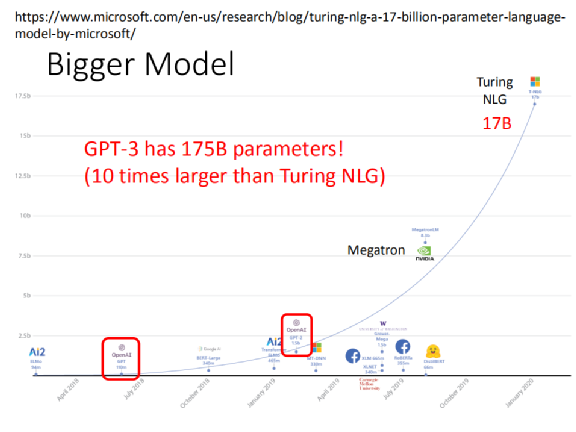 Antes, el modelo más grande era Turing NLG. Les he mostrado una tabla de comparación del tamaño del modelo antes, incluido el primer ELMo con el Turing NLG posterior. Turing NLG ya es muy grande: tiene 17 mil millones de parámetros, superando con creces el GPT-2 y el primer GPT publicado por OpenAI.
Antes, el modelo más grande era Turing NLG. Les he mostrado una tabla de comparación del tamaño del modelo antes, incluido el primer ELMo con el Turing NLG posterior. Turing NLG ya es muy grande: tiene 17 mil millones de parámetros, superando con creces el GPT-2 y el primer GPT publicado por OpenAI.
¿Y qué tamaño tiene el GPT de tercera generación? Es 10 veces mayor que el de Turing NLG. Tiene 175 mil millones de parámetros, que son 175 mil millones de parámetros. No se puede dibujar en esta imagen en absoluto.

Suponiendo que usamos la longitud para representar la cantidad de parámetro, la cantidad de parámetro de ELMO es una regla de 30 cm de largo, entonces GPT-3 es aproximadamente 2000 veces la de ELMO. ¿Cuánto es 30 cm × 2000? Es más alto que Taipei 101.

Si todas las cosas grandes son del Continente Oscuro, GPT-3 es como un modelo del Continente Oscuro.
1Explicar los objetivos de la serie GPT en detalle.
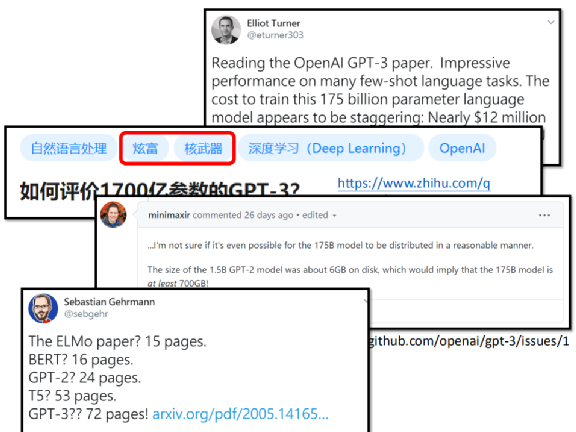
Hay varias discusiones en Internet. Alguien preguntó, ¿cuánto cuesta entrenar un GPT-3 en una plataforma comercial de computación en la nube? Costará 12 millones de dólares estadounidenses, que son unos 400 millones de dólares taiwaneses. La discusión sobre GPT-3 en Zhihu arriba incluso ha sido etiquetada como una muestra de riqueza y armas nucleares.
Además, GPT-2 tiene 1.5 mil millones de parámetros, que son solo 6GB, y 175 mil millones de parámetros son aproximadamente 700GB, que incluso pueden ser difíciles de descargar.
El documento GPT-3 también es muy largo: ELMO tiene 15 páginas, BERT tiene 16 páginas, GPT-2 tiene 24 páginas, T5 tiene 53 páginas y GPT-3 tiene 72 páginas.
Entonces, ¿qué quiere lograr esta serie de trabajos de GPT?
Lo que quiere hacer es cerrar el aprendizaje.
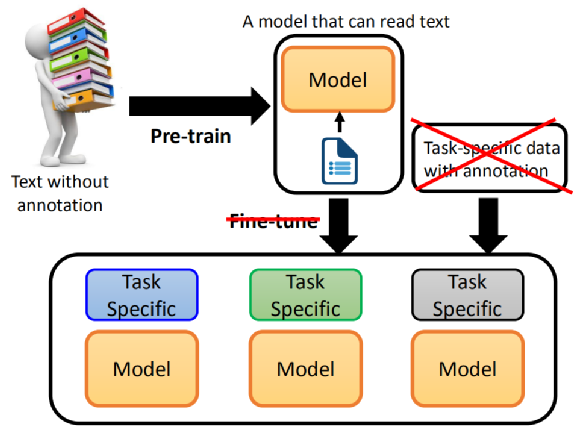
En el pasado, cuando usábamos el modelo de preentrenamiento BERT +, primero preparábamos el modelo de preentrenamiento, y luego preparábamos la información relacionada con estas tareas para cada tarea, y realizamos un ajuste fino basado en la información profesional de estas tareas. .modelo.
Por lo tanto, si desea utilizar BERT para resolver tareas, aún debe recopilar algunos datos. BERT no tiene forma de resolver estas tareas directamente, incluidas las tareas de control de calidad o las tareas de NLI.
El trabajo de la serie GPT es preguntar: ¿podemos eliminar el paso de ajuste fino, podemos entrenar previamente un modelo, este modelo puede resolver directamente las tareas posteriores, incluso no se necesita un ajuste fino?

Este puede ser el objetivo final de la serie GPT.
Al realizar el examen de dominio del inglés, ¿cómo les decimos a los candidatos cómo responder las preguntas del examen? De hecho, solo se necesita una descripción del tipo de pregunta.
Por ejemplo, dígale al examinado que elija la palabra o palabra que mejor se adapte al significado de la pregunta, y luego tal vez dé un ejemplo adicional para decirle al examinado cómo resolver la pregunta si realmente quiere ser resuelta, y se acabó. Los candidatos solo leen la descripción de los tipos de preguntas y algunos ejemplos para saber cómo responder las siguientes preguntas. La serie GPT quiere hacer algo similar.

Para ser más específicos, lo que hace GPT es así: tiene tres posibilidades: aprendizaje de pocas oportunidades, aprendizaje de una sola vez y aprendizaje de cero oportunidades.
En el caso de Few-shot Learning, primero muestre al modelo GPT una oración, que es una descripción de la tarea. Si es una traducción, la descripción de la tarea es traducir del inglés al francés, y espero que la máquina pueda entender el significado de la oración. Luego dale algunos ejemplos y dile que la nutria marina se traduce en esto, y Plush girafe se traduce en esto.
A continuación, inicie el examen y pregúntele en qué se debe traducir el queso. Este es el aprendizaje de pocas tomas, es decir, la parte de ejemplo puede proporcionar más de un ejemplo.
Si es One-shot Learning, puede estar muy cerca de la situación de los seres humanos en la prueba de dominio del inglés. Solo te daré una descripción del tipo de pregunta, te daré otro ejemplo y luego responderé las preguntas tú mismo.
Lo más loco es Zero-shot Learning, que proporciona directamente una descripción de un tema y luego responde la pregunta. No sé si es posible que un modelo de idioma lo haga. Confiesa que traduce del inglés al francés. Sin formación adicional, sabe lo que significa traducir al francés. A continuación, dale una oración en inglés y automáticamente sabrá producir en francés, lo que obviamente es un gran desafío.
Quizás One-shot Learning esté más cerca de lo que se puede lograr en la realidad. La máquina ha visto al menos un ejemplo, One-shot Learning todavía tiene una mejor oportunidad.
Necesito recordar aquí que en GPT-3, su Aprendizaje de pocos disparos es diferente del llamado Aprendizaje de pocos disparos. Generalmente, el llamado Aprendizaje de pocos disparos consiste en proporcionar a la máquina una pequeña cantidad de datos de entrenamiento y utilizar una pequeña cantidad de datos de entrenamiento para ajustar el modelo. Pero no existe el ajuste fino en GPT-3. El llamado Aprendizaje de pocos disparos, el llamado ejemplo pequeño, se usa directamente como entrada del modelo GPT. Después de leer estas oraciones en GPT, sabrá automáticamente cómo resolver el siguiente problema.
En este proceso, el modelo no se ajusta en absoluto y no existe el llamado descenso de gradiente en absoluto. Ingrese directamente el texto como instrucciones, y estos textos le permitirán saber qué hacer a continuación, y esperará que vea las explicaciones y ejemplos de estos tipos de preguntas, y será cierto. Responda la pregunta.
En el documento GPT-3, llamaron a este método de aprendizaje "aprendizaje en contexto".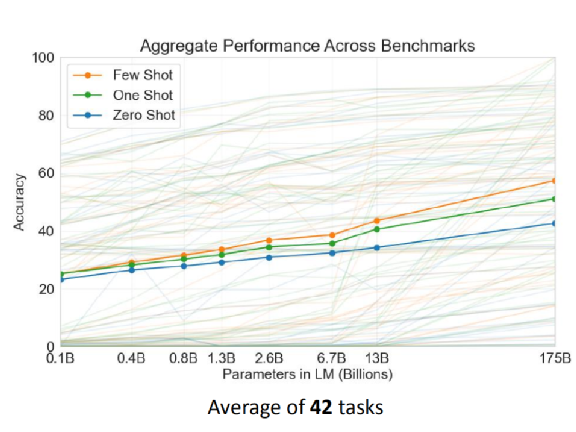
La magia de 2GPT-3
Entonces, ¿cómo funciona el papel GPT-3? ¿Cómo funciona el gigantesco GPT-3?
La figura anterior es el promedio de 42 tareas utilizadas en el documento. El número es exactamente 42, que es un número muy coincidente. Sabemos que 42 es el significado de la vida (la computadora de "La guía del autoestopista galáctico" tardó mucho en obtener el resultado). No sé si las 42 tareas aquí son deliberadas.
El eje vertical de la figura anterior es la tasa correcta, y el eje horizontal es el tamaño del modelo, que va desde 0,1 mil millones a 175 mil millones. El azul es Zero Shot, el verde es One Shot y el naranja es Few Shot. Se puede ver que a medida que el modelo se hace cada vez más grande, ya sea en el aprendizaje de pocos intentos, el aprendizaje de un solo paso o el aprendizaje de cero, la tasa de precisión es cada vez mayor.
Por supuesto, algunas personas pueden preguntarse si vale la pena usar aproximadamente 10 veces la cantidad de parámetros para aumentar la tasa de precisión en un poquito. Al menos esta figura muestra que un modelo más grande es realmente beneficioso. En cuanto a un modelo 10 veces más grande, es una cuestión de si es aceptable o rentable aumentar la tasa de precisión. Esto es una cuestión de opinión.
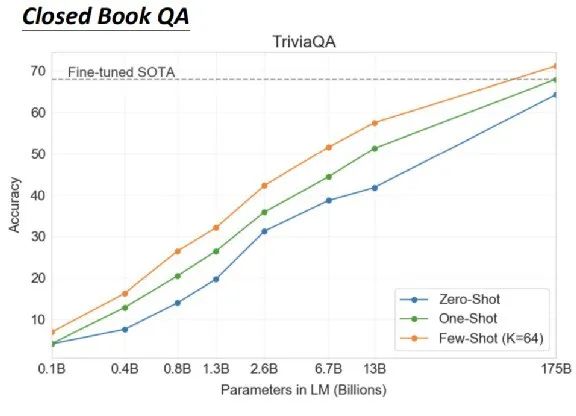
A continuación, hablaré sobre algunos aspectos mágicos de GPT-3. En primer lugar, puede realizar un control de calidad a libro cerrado. En la respuesta a la pregunta, hay una fuente de conocimiento, hay una pregunta, y luego se encuentra la respuesta. Si la máquina puede leer la fuente de conocimiento al responder la pregunta, es un control de calidad de libro abierto, mientras que el control de calidad de libro cerrado no tiene una fuente de conocimiento. Simplemente haga una pregunta para ver si puede obtener la respuesta. Por ejemplo, pregúntale directamente qué tan alto es el Himalaya, y mira si hay información sobre la altura del Himalaya en los parámetros de la máquina, y si no necesitas leer ningún artículo, sabrá que la altura del Himalaya es 8848 metros.
El rendimiento de GPT-3 es así, la línea azul es Zero Shot, la línea verde es One Shot y la línea naranja es Few Shot. Lo mágico es que Few-shot Learning en realidad supera al mejor modelo de ajuste fino de SOTA en TriviaQA.
Entonces, aquí, el enorme modelo muestra un milagro. Si son solo 13 mil millones, no hay forma de superar a SOTA, pero es aproximadamente 10 veces más grande, llegando a 175 mil millones, lo que puede superar a SOTA.
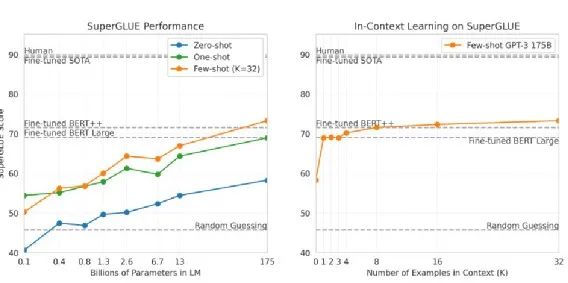
La imagen de arriba es parte de SuperGLUE, que también muestra el rendimiento de Aprendizaje de disparo cero, Aprendizaje de disparo único y Aprendizaje de disparo reducido. Quien tenga más y más parámetros tendrá un mejor rendimiento. Si observa el modelo más grande, puede superar al modelo BERT Large afinado.
La imagen de la derecha muestra el impacto del ejemplo de entrenamiento en el rendimiento cuando se realiza el aprendizaje de pocas tomas.
Si no se da ningún ejemplo, es decir, Aprendizaje Zero-shot, por supuesto que es un poco malo. Pero con más y más ejemplos, si solo se dan 1, 2, 3, 4, el rendimiento de Fine-tuned BERT es similar; si se dan 32, puede superar a Fine-tuned BERT.
GPT-3 es un modelo de lenguaje, por lo que puede generar texto. En los artículos GPT-3, los autores también usan GPT-3 para generar artículos. Dan los titulares de las noticias de GPT-3 y luego esperan que GPT-3 escriban las noticias ellos mismos.
Hay un pequeño descubrimiento mágico: si no le das a GPT-3 ningún ejemplo, simplemente dale un titular de noticias, pensará que el titular de noticias es una oración de Twitter, y luego lo recordará por sí solo. Imagina.
Entonces, al generar el texto, GPT-3 no será Zero-shot. Debe darle algunos ejemplos, decirle que tiene un título y luego se seguirá un artículo de noticias, y luego darle un título, espero Se puede elaborar en base a este título. 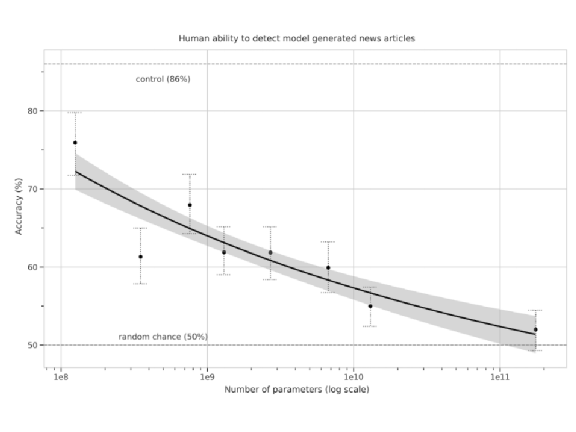 En la figura anterior, el eje vertical representa la noticia generada por GPT-3 y la noticia real ¿Puede la gente juzgar si esta noticia es cierta o no? Si la tasa correcta de personas es solo del 50%, significa que las noticias generadas por GPT-3 son demasiado reales, tan reales que los humanos no pueden juzgar si son verdaderas o falsas. Descubriremos que a medida que aumenta el número de parámetros, GPT-3 puede engañar a los humanos cada vez más. El GPT-3 más grande casi puede engañar a los humanos. Los humanos casi no tienen forma de distinguir las noticias generadas por GPT-3 de las la verdad La diferencia entre las noticias.
En la figura anterior, el eje vertical representa la noticia generada por GPT-3 y la noticia real ¿Puede la gente juzgar si esta noticia es cierta o no? Si la tasa correcta de personas es solo del 50%, significa que las noticias generadas por GPT-3 son demasiado reales, tan reales que los humanos no pueden juzgar si son verdaderas o falsas. Descubriremos que a medida que aumenta el número de parámetros, GPT-3 puede engañar a los humanos cada vez más. El GPT-3 más grande casi puede engañar a los humanos. Los humanos casi no tienen forma de distinguir las noticias generadas por GPT-3 de las la verdad La diferencia entre las noticias.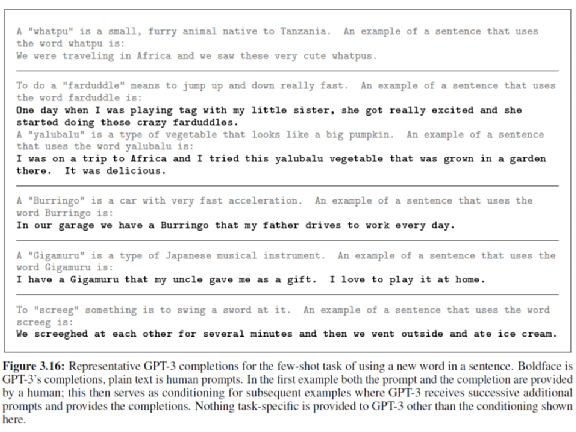
GPT-3 también aprendió a formar oraciones. En la imagen de arriba, el texto gris claro es entrada humana y el texto negro es salida GPT-3.
Primero le dice a GPT-3 cómo hacer una oración, de qué se trata la oración, primero dé una definición de un vocabulario. Por ejemplo, hay una cosa llamada "whatpu", que es "whatpu" y "whatpu" es un pequeño animal peludo. A continuación, haga una oración con "whatpu" como vocabulario. Si viajamos a África, vemos un montón de whatpu lindo.
Permítanme darles otro vocabulario que se creó al azar. Este vocabulario se llama "Burringo", que es un automóvil que corre rápido. Pídale a GPT-3 que use "Burringo" para hacer una oración, y luego GPT-3 dijo que hay un Burringo en nuestro garaje, y mi papá conduce Burringo hacia y desde el trabajo todos los días. Sabe que Burringo es algo que se puede abrir.
Para otro ejemplo, hay algo llamado "Gigamuru", que es un instrumento musical japonés. Entonces deje que GPT-3 use "Gigamuru" para hacer una oración. GPT-3 dijo, tengo un Gigamuru, que es un regalo de mi tío, y me gusta tocarlo en casa. Sabe que Gigamuru es algo que se puede jugar.
O hay un verbo "screeg", que significa blandir una espada. En este momento, la oración creada por GPT-3 es un poco extraña. Dice que nos gritamos (sabe agregar ed), es decir, nos balanceamos las espadas y luego comemos helado. A primera vista , parece un poco incorrecto., Balancear sus espadas entre sí se siente como si fueran enemigos, así que ¿por qué comer helado a continuación?
Pero si piensas en screeg como un juego de niños, aunque es un golpe de espada, sigue siendo un juego de niños. Después de que los niños se golpean con sus espadas, luego comen helado, suena razonable.
Veamos si GPT-3 puede aprender a resolver problemas matemáticos. ¿Cómo hacer que resuelva problemas de matemáticas? Simplemente pregunta "¿Cuánto es 17 menos 14?", Y luego da "A:", automáticamente responde "3". En realidad, cuenta como matemáticas.
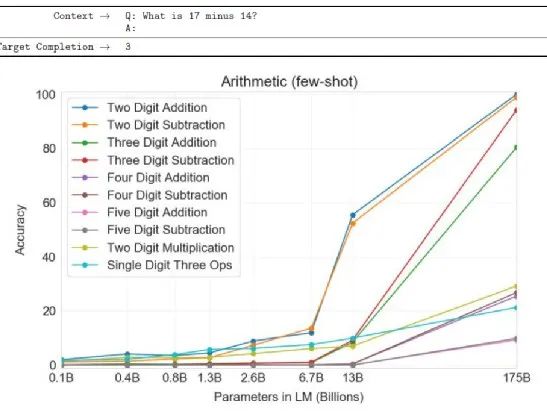
¿Hasta qué punto se puede alcanzar el nivel de matemáticas de GPT-3? El eje horizontal de la figura anterior representa la cantidad de parámetro del modelo utilizado y el eje vertical representa la tasa correcta. Si observa el modelo con el mayor número de estos parámetros, encontrará que básicamente en la suma de dos dígitos y la resta de dos dígitos, puede obtener una buena tasa de casi el 100% de precisión. La resta de tres dígitos también se hace bien, y no sé por qué la suma de tres dígitos es un poco peor.
Otros problemas más difíciles: la suma de 4 dígitos y 5 dígitos es más difícil para él, pero al menos ha aprendido la suma y resta de dos dígitos y tres dígitos (tres dígitos no se aprenden completamente).
Lo "no mágico" de 3GPT-3
Arriba hablamos principalmente sobre la magia de GPT-3. Además de la magia, también hay lugares donde no funciona.
A juzgar por el artículo, GPT-3 no es muy bueno cuando se trata de problemas de NLI.
El llamado problema NLI es darle a la máquina dos oraciones y pedirle a la máquina que juzgue si las dos oraciones son contradictorias, se contienen entre sí o tienen una relación neutra.
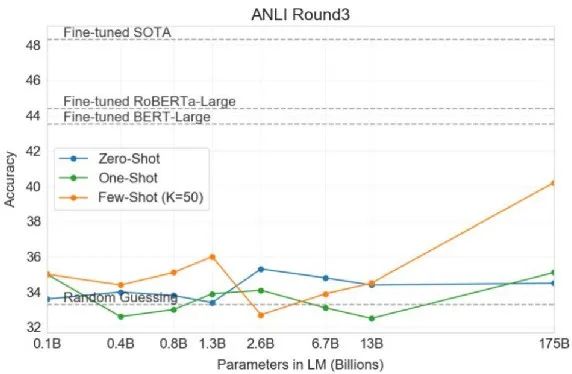
En este momento, encontrará que si usa un modelo GPT-3, a medida que el modelo se vuelve más y más grande, Zero-Shot y One-Shot básicamente funcionan mal.
Esta línea de puntos gris representa Adivinación aleatoria. Incluso los modelos más grandes, en Zero-Shot y One-Shot, son básicamente miserables. El Aprendizaje de Pocos Disparos, cuando se dan 50 ejemplos al modelo, parece tener algo de esperanza, solo en esta situación muestra algunos signos de vida.
Por lo tanto, el problema de NLI sigue siendo algo difícil para GPT-3.
Sin embargo, GPT-3 es un modelo de lenguaje enorme, nunca ha visto ningún problema de NLI durante el proceso de aprendizaje y solo conoce el siguiente vocabulario.
Quizás porque al hacer la tarea NLI, las dos oraciones que juntamos son a menudo oraciones extrañas y contradictorias. Cuando se juntan dos oraciones contradictorias, esta situación en sí aparece muy raramente en palabras humanas. Por lo tanto, la serie GPT se sentirá un poco confusa cuando viendo este tipo de frases concatenadas pero contradictorias.
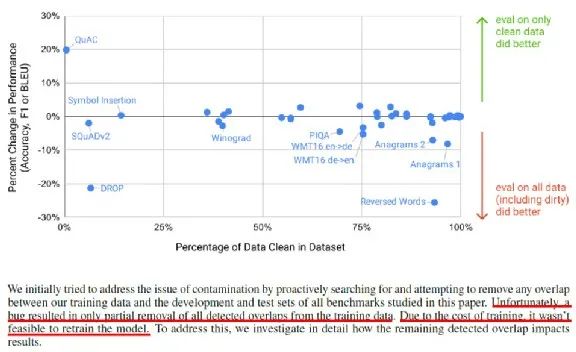
A continuación sucedió algo interesante. Hoy, cuando estamos entrenando este enorme modelo, los datos a menudo provienen de la red, y los datos que descienden de la red pueden contener nuestros datos de prueba actuales.
Esto es posible. Originalmente, cuando OpenAI estaba haciendo este experimento, querían evitar que los datos de entrenamiento se mezclaran con datos de tareas posteriores. Pero tenían un error en el momento de escribir este artículo, por lo que no lo lograron. Pero este error es demasiado grave para imaginar al investigador que se ha equivocado, cuánta presión psicológica tiene.
Y "Por el costo de la capacitación, no fue factible reentrenar el modelo", porque GPT-3 es demasiado grande, aunque hay un error, no hay forma de reentrenar, es solo eso.
Aunque no hay forma de reentrenamiento, cambiemos los datos de la prueba. Por lo tanto, dividen los datos de tareas posteriores en datos limpios y datos sucios.
Limpiar datos, es decir, datos que no fueron tocados por GPT-3 durante el entrenamiento. Los datos sucios son los datos que GPT-3 tocó durante el entrenamiento. Si estos puntos están por debajo de esta línea horizontal, significa que el rendimiento de los datos sucios es mejor. Por encima de la línea horizontal, significa que GPT-3 solo analiza el rendimiento de los datos limpios. Es decir, hay algunos materiales mixtos que no lo aprovechan. Es decir, si los datos de entrenamiento están contaminados o mezclados con datos de tareas posteriores puede que no tenga un gran impacto en GPT-3, así que si hay un error, olvídelo.
4¿Cuál es el nivel de idioma del modelo a gran escala?
Ahora que tenemos tantos modelos enormes, ¿hasta qué punto pueden entender el lenguaje humano?
Hay una competencia llamada Turing Advice Challenge. No tiene nada que ver directamente con GPT-3. Solo creo que hay tantos modelos enormes que parecen entender los lenguajes humanos. ¿Pueden saber cómo usar estos lenguajes como lo hacen los humanos? La competencia Turing Advice Challenge requiere que las máquinas den opiniones humanas sobre reddit. Habrá muchos puntos en reddit, por ejemplo, alguien dará algunos problemas emocionales. Este punto es un ejemplo incluido en el documento Desafío de consejos de Turing.
 Una persona dijo que su novio había estado saliendo con ella durante 8 meses, y luego un día su novio quiso darle un regalo de cumpleaños y su novio encontraría a todos sus amigos juntos, y luego le mostró la espalda, la espalda Hay un tatuaje en la cara de su novia, y esta chica sentirá que no es bueno, preguntará qué hacer y esperará algunas sugerencias de los internautas.
Una persona dijo que su novio había estado saliendo con ella durante 8 meses, y luego un día su novio quiso darle un regalo de cumpleaños y su novio encontraría a todos sus amigos juntos, y luego le mostró la espalda, la espalda Hay un tatuaje en la cara de su novia, y esta chica sentirá que no es bueno, preguntará qué hacer y esperará algunas sugerencias de los internautas.
Sobre este tema, GPT recomienda romper.

Para las máquinas, no es fácil dar consejos decentes.
Para dar otro ejemplo, alguien hizo una pregunta, diciendo que iba a tomar una clase de anatomía en la escuela secundaria, pero le tienen mucho miedo a los animales muertos, ¿qué debo hacer? Una persona dio una sugerencia, sugirió que se puede omitir el informe y la persona que hizo la pregunta encontró útil esta sugerencia. En realidad, no estoy seguro de si esta sugerencia es útil, pero al menos la persona que hizo la pregunta la encuentra útil.
Entonces, ¿cómo aprende la máquina a dar consejos? Entrena un modelo, este modelo "come" un punto en reddit, y luego encontrará una manera de imitar la respuesta debajo del punto.
Esta competencia proporciona 600k datos de entrenamiento, es decir, 600k puntos en reddit y respuestas debajo de los puntos, y se espera que la máquina pueda aprender la respuesta correcta.
Aquí tomo T5 como ejemplo, no había GPT-3 en ese momento. La respuesta a T5 es esta: ve y dile a tu maestro que quieres un proyecto, y luego este proyecto puede ver animales muertos.
Esta respuesta es obviamente incomprensible, parece una oración razonable, parece que se está diciendo algo, pero en realidad no tiene ningún efecto. Hoy en día, estos enormes modelos de lenguaje a menudo pueden comportarse tal como son.
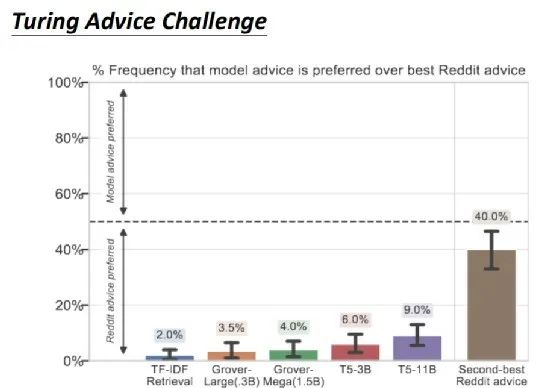
La imagen de arriba muestra algunos resultados experimentales reales. En el Turing Advice Challenge, se incluyen varios modelos como Grover y T5. El resultado es que incluso en T5, las personas solo sienten que las sugerencias hechas por T5 son más efectivas que las hechas por otros en el 9% de los casos.
Si compara la recomendación con la calificación más alta en reddit y la recomendación con la segunda calificación más alta, de hecho, la recomendación con la segunda calificación más alta sigue siendo que el 40% de las personas lo encuentra útil, pero solo el 9% de las personas T5 lo encuentra útil. .
Esto muestra que el texto producido por este enorme modelo de lenguaje para ayudar a la máquina aún está lejos de la capacidad de los humanos para usar el lenguaje.