Directorio de artículos
- Empuje la fórmula, haga ruedas en el sitio
- Código triturado
- Conceptos básicos de informática
- Métrico
- Modelo lineal
- Estadísticas de probabilidad
-
- Pregunta de probabilidad: A y B se turnan para comer dulces. La probabilidad de comer en cada ronda es 1/2. El que come primero gana, la probabilidad de que A gane. Hay dos caramelos, la expectativa de la cantidad de caramelos.
- La incidencia de una determinada enfermedad es 1/1000. El paciente tiene un 95% de probabilidad de ser diagnosticado con la enfermedad, y una persona sana tiene un 5% de probabilidad de ser mal diagnosticada. Si se detecta que una persona está enferma, ¿cuál es el probabilidad real de la enfermedad.
- Varias conversiones de rand elegantes
- La diferencia entre la estimación de máxima verosimilitud y la máxima probabilidad posterior
- ¿Cuál es la distribución previa conjugada?
- ¿Cómo cambia un aleatorizador con una distribución uniforme de 0 ~ 1 a un aleatorizador con un valor medio de 0 y una varianza de 1?
- La distribución uniforme produce una distribución normal
- 37% ley
Empuje la fórmula, haga ruedas en el sitio
k significa
#coding=utf-8
def distance(pt1,pt2):
m=len(pt1)
ans=0
for i in range(m):
ans+=(pt1[i]-pt2[i])**2
return ans
# 构造样本
pts=[]
for i in range(10):
for j in range(10):
pts.append([i,j])
# 初始中心
centers=[[0,2],[3,3]]
k=len(centers)
m=2
# 迭代
print(centers)
for i in range(5):
# 给每个样本分配对应的标签
labels=[]
for pt in pts:
best_i=-1
best_dis=100000
for i, center in enumerate(centers):
dis=distance(pt,center)
if dis<best_dis:
best_i=i
best_dis=dis
labels.append(best_i)
# 重新计算中心点
cts=[[] for _ in range(k)]
centers=[[0]*m for _ in range(k)]
for pt,label in zip(pts, labels):
cts[label].append(pt)
for label in range(k):
n_samples=len(cts[label])
for dim in range(m):
sm=0
for sample in range(n_samples):
sm+=cts[label][sample][dim]
sm/=n_samples
centers[label][dim]=sm
print(centers)
print(labels)
Regresión logística
Principalmente respaldar estos códigos
- Entropía cruzada
loss = -(y @ np.log(y_hat) + (1 - y) @ np.log(1 - y_hat)) / n
- y_hat cálculo
Solo sigmoide
return 1 / (1 + np.exp(-X @ self.w))
- Cálculo de gradiente
dw = (y - y_hat) @ X
dw /= n
class LR:
def __init__(self, lr=0.1, max_iter=1000, eps=1e-5):
self.eps = eps
self.max_iter = max_iter
self.lr = lr
def predict_proba(self, X):
return 1 / (1 + np.exp(-X @ self.w))
def fit(self, X: np.ndarray, y: np.ndarray):
n, m = X.shape
X = np.hstack([X, np.ones([n, 1])])
m += 1
self.w = np.zeros([m])
pre_loss = 0
for i in range(self.max_iter):
y_hat = self.predict_proba(X)
# 交叉熵
loss = -(y @ np.log(y_hat) + (1 - y) @ np.log(1 - y_hat)) / n
if abs(loss - pre_loss) < self.eps:
print('误差不再减少')
break
pre_loss = loss
print(loss)
# 计算梯度
dw = (y - y_hat) @ X
dw /= n
# 梯度下降
self.w += dw * self.lr
print(self.w)
Regresión lineal
Código triturado
挖井的问题(每个家庭都可以打井,成本为c[i],或者挖水管,i,j两家通水管成本为dp[i][j]。求所有家庭喝上水的最小成本)
Muestras de salida que cumplen los cuatro requisitos de la base de datos (los requisitos específicos se olvidan y el hash está involucrado)
Cien millones de datos de nivel son la temperatura de varios lugares de la Tierra. La matriz está ordenada y la complejidad del tiempo es O (n). El entrevistador fue muy amable, dio muchos consejos y finalmente lo escribió ... me da vergüenza
Conceptos básicos de informática
Problema de copia profunda y copia superficial de Python
Expresión regular
Tabla de picadillo
A qué estructura de la tabla hash en Python corresponde y cómo resolver los conflictos de hash
Solución al conflicto de hash
Métrico
AUC
Dadas al azar dos muestras, una positiva y otra negativa, la probabilidad de que la muestra positiva se clasifique antes que la muestra negativa (equivalente y Wilcoxon-Mann-Witney Test), por lo que cuanto mayor sea el AUC, más probable es que la muestra positiva se clasifique antes que la muestra negativa, que es decir, cuanto mayor sea el resultado de clasificación Great.
Entonces, AUC refleja la capacidad del clasificador para ordenar muestras.
Método de dibujo / cálculo
Método 1
El enfoque es que, dado que se conoce la probabilidad de cada muestra, se ordena de pequeña a grande y se utiliza como probabilidad de corte a su vez. Una predicción menor que esta probabilidad es un ejemplo negativo, y una predicción mayor que esta probabilidad es positiva. Por ejemplo, para que cada muestra tenga un Valor de predicción, puede calcular las tasas de verdaderos y falsos positivos en la muestra, dibujar puntos en el sistema de coordenadas y luego cambiar la probabilidad de corte a su vez, calcular las tasas de verdaderos y falsos positivos de diferentes grupos , el área entre la curva dibujada y el eje horizontal es el AUC
Método 2
Suponga que hay un total de (m + n) muestras, de las cuales m son muestras positivas, n son muestras negativas y hay un total de m n pares de muestras, recuento y la probabilidad de que una muestra positiva se predice como positiva. muestra es mayor que la probabilidad de una muestra negativa que se predice como muestra positiva El valor se registra como 1, el recuento se acumula y luego se divide por (m n) es el valor de AUC
import numpy as np
from sklearn.metrics import roc_auc_score
def auc(labels, probs):
n_samples = len(labels)
pos_cnt = sum(labels)
neg_cnt = n_samples - pos_cnt
total_comb = pos_cnt * neg_cnt #组合数
pos_index = np.where(labels==1)[0] #找出正例的索引
neg_index = np.where(labels==0)[0] # 找出负例的索引
cnt = 0
for pos_i in pos_index:
for neg_j in neg_index:
if probs[pos_i] > probs[neg_j]:
cnt += 1
elif probs[pos_i] == probs[neg_j]:
cnt += 0.5
else:
cnt += 0
auc = cnt / total_comb
return auc
labels = np.array([1,1,0,0,1,1,0])
probs= np.array([0.8,0.7,0.5,0.5,0.5,0.5,0.3])
print('ours:', auc(labels,probs))
print('sklearn:', roc_auc_score(labels,probs))
Método 3
Establezca el intervalo de escala del eje horizontal en 1 / N y el intervalo de escala del eje vertical en 1 / P ; luego, clasifique las muestras de acuerdo con la salida de probabilidad prevista por el modelo (de mayor a menor);
Atraviese las muestras a su vez y dibuje la curva ROC desde el punto cero. Cada vez que se encuentra una muestra positiva, se dibuja una curva con un intervalo de escala a lo largo del eje vertical y una curva con un intervalo de escala a lo largo del eje horizontal cada vez que se encuentra una muestra negativa, hasta el recorrido. Después de terminar todas las muestras, la curva finalmente se detiene en el punto (1,1) y se dibuja toda la curva ROC.
¿Por qué ROC es más robusto a las muestras desequilibradas que PR?
Sabemos que cuando dibujamos curvas ROC y PR, dibujamos líneas de puntos con (FPR, TPR) y (Precision, Recall) respectivamente.
Porque en el caso del mismo TPR, su diferencia FPR es relativamente pequeña. Pero su diferencia de curva PR es relativamente grande, porque bajo la misma situación de TPR, su diferencia de Precisión es bastante grande.
¿Cuándo elegir PR y cuándo elegir ROC?
Esencialmente, la diferencia en la primera pregunta es que ROC y PR se enfocan en puntos diferentes. ROC se enfoca en muestras positivas y negativas al mismo tiempo, mientras que PR solo se enfoca en muestras positivas. Esto no es difícil de entender, porque TPR es una medida de muestras positivas y FPR es una medida de muestras negativas. Sin embargo, tanto Precision como Recall son muestras de medición positivas.
Por ejemplo, para predecir el cáncer, preferiríamos las relaciones públicas, porque esperamos predecir la mayor cantidad posible de pacientes con cáncer y, al mismo tiempo, ser lo más precisos posible y no perder a ningún paciente con cáncer. En cuanto a FPR, en realidad no es tan importante, porque siempre se puede verificar por otros medios más.
Pero para los modelos de clasificación de imágenes de perros y gatos, preferiríamos ROC, porque nuestro objetivo es identificar con precisión tanto a los gatos como a los perros, y ROC presta atención a ambos aspectos al mismo tiempo.
Modelo lineal
Qué hacer cuando L1 no está guiado
Cuando la función de pérdida no es diferenciable y el descenso del gradiente ya no es efectivo, se puede utilizar el método de descenso del eje de coordenadas. El descenso del gradiente es actualizar los parámetros a lo largo de la dirección del gradiente negativo del punto actual, y el método de descenso del eje de coordenadas es a lo largo de la dirección del eje de coordenadas. Para el número de entidades, cuando el método de descenso del eje de coordenadas ingresa a la actualización de parámetros, el valor de m-1 se fija primero, y luego se busca la solución local óptima del otro, de modo que Evite el problema de la función de pérdida indirecta.
Utilice el algoritmo proximal para resolver L1, este método es para optimizar el resultado del límite superior de la función de pérdida # Estadísticas de probabilidad
Estadísticas de probabilidad
Pregunta de probabilidad: A y B se turnan para comer dulces. La probabilidad de comer en cada ronda es 1/2. El que come primero gana, la probabilidad de que A gane. Hay dos caramelos, la expectativa de la cantidad de caramelos.
2 3 \ frac {2} {3} 32
No esperes
La incidencia de una determinada enfermedad es 1/1000. El paciente tiene un 95% de probabilidad de ser diagnosticado con la enfermedad, y una persona sana tiene un 5% de probabilidad de ser mal diagnosticada. Si se detecta que una persona está enferma, ¿cuál es el probabilidad real de la enfermedad.
Fórmula bayesiana
Varias conversiones de rand elegantes
470. Implementar Rand10 () con Rand7 ()
class Solution {
public:
int rand10() {
int row,col,idx;
do{
row=rand7();
col=rand7();
idx=col+(row-1)*7;
}while(idx>40);
return 1+(idx-1)%10;
}
};
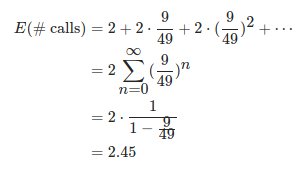
- rand5 implementa rand7
class Solution {
public:
int rand7() {
int row,col,idx;
do{
row=rand5();
col=rand5();
idx=col+(row-1)*5;
}while(idx>21);
return 1+(idx-1)%7;
}
};
suponer:
2 ⋅ 1 1 - 4 25 2 \ cdot \ frac {1} {1- \ frac {4} {25}} 2⋅1-2 541
- rand11 implementa rand7
Esto es extraño, entiendo que es equivalente a solo una línea
La diferencia entre la estimación de máxima verosimilitud y la máxima probabilidad posterior
La estimación de máxima verosimilitud proporciona un método para evaluar los parámetros del modelo dados los datos de observación, y el muestreo en la estimación de máxima verosimilitud satisface el supuesto de que todas las muestras son independientes y están distribuidas de manera idéntica.
La probabilidad posterior máxima es una estimación puntual que es difícil de observar con base en datos empíricos. La mayor diferencia con la estimación de máxima verosimilitud es que la probabilidad posterior máxima se integra en la distribución previa de la cantidad a estimar, por lo que la probabilidad posterior máxima puede considerarse como una regla Estimación de máxima verosimilitud
¿Cuál es la distribución previa conjugada?
Suponiendo que es el parámetro en la distribución general, la función de densidad previa lo es, y la función de densidad posterior calculada mediante la información de muestreo tiene la misma forma funcional, se denomina conjugada previa.
¿Cómo cambia un aleatorizador con una distribución uniforme de 0 ~ 1 a un aleatorizador con un valor medio de 0 y una varianza de 1?

La distribución uniforme produce una distribución normal
La distribución uniforme del algoritmo probabilístico produce una distribución normal
Método de función inversa
Generalmente, una distribución de probabilidad, si su función de distribución es y = F (x) y = F (x)y=F ( x ) , entonces, el rango de y es 0 ~ 1, encuentre la función inversaGGG , y luego genera un número aleatorio entre 0 y 1 como entrada, luego la salida es un número aleatorio que se ajusta a la distribución:
y = G ( x ) y= G(x) y=G ( x )
Teorema del límite central
import numpy as np
import pylab as plt
n = 12
N = 5000
x = np.zeros([N])
for j in range(N):
a = np.random.rand(n)
u = sum(a)
x[j] = u - n * 0.5
plt.hist(x)
plt.show()
Caja Muller
import numpy as np
import pylab as plt
N = 1000
x1 = np.random.rand(1, N)
x2 = np.random.rand(1, N)
y1 = np.sqrt(-2 * np.log(x1)) * np.cos(2 * np.pi * x2)
y2 = np.sqrt(-2 * np.log(x1)) * np.sin(2 * np.pi * x2)
y = np.hstack([y1, y2])
plt.hist(y)
plt.show()
37% ley
En un evento, n niñas sosteniendo rosas de diferentes longitudes en sus manos, dispuestas en una fila desordenada, un niño caminaba de principio a fin, tratando de obtener una rosa más larga, una vez que tomó una, no pudo tomar la otra Sí, si te lo pierdes, no puedes mirar atrás, pregunta la mejor estrategia?