1. Preparación de datos
Los datos de este proyecto son la recopilación de datos de comportamiento de los usuarios de los sitios web de comercio electrónico, que incluyen principalmente cuatro tipos de comportamientos de los usuarios: buscar, hacer clic, realizar un pedido y pagar.
Formato de datos
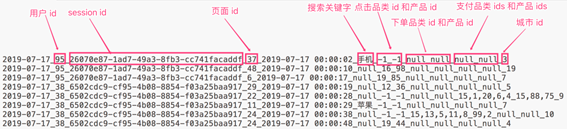
- Los datos utilizan _ campo dividido.
- Cada fila representa un comportamiento del usuario, por lo que cada fila solo puede ser uno de los cuatro comportamientos.
- Si la palabra clave de búsqueda es nula, significa que esta vez no es una búsqueda.
- Si la identificación de la categoría en la que se hizo clic y la identificación del producto son -1, significa que esta vez no es un clic.
- En términos de comportamiento de pedido, se pueden pedir varios productos a la vez, por lo que la identificación de la categoría y la identificación del producto son múltiples y la identificación está separada por una coma. Si no es un pedido, sus datos relacionados se representan con un valor nulo.
- El comportamiento de pago es similar al de realizar un pedido.
Descarga de conjunto de datos
Enlace: https://pan.baidu.com/s/1ZLhYdXz1Foi6MpeUBFGCnQ
código de extracción: 12lt
Demanda 1: Top10 categorías populares
Declaración de necesidades
La categoría se refiere a la clasificación de productos. Los sitios web de comercio electrónico grandes tienen varias categorías. En nuestro proyecto solo hay una categoría. Las diferentes empresas pueden tener diferentes definiciones de popular. Contamos las categorías populares según la cantidad de clics, pedidos y pagos de cada categoría.
Los requisitos de este proyecto se optimizan de la siguiente manera: primer rango según el número de clics y el ranking más alto; si el número de clics es el mismo, entonces compare el número de pedidos; si el número de pedidos es el mismo nuevamente, compare el número de pagos .
análisis de demanda
- Determine cuál de los tres tipos de "clic", "pedido" y "pago" es la operación.
- Combine categoría y categoría de operación en (categoría, (número de clics, número de pedidos, número de pagos)), y el metagrupo se puede ensamblar como un objeto.
- Agregue el número total de tres operaciones según la categoría clave.
- Ordena los 10 primeros.
Código:
Cree una clase de muestra para encapsular la información de los datos
// 样例类可以自动生成apply方法和unapply()方法
case class UserVisitAction(date: String, //用户点击行为的日期
user_id: Long, //用户的ID
session_id: String, //Session的ID
page_id: Long, //某个页面的ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的ID
click_product_id: Long, //某一个商品的ID
order_category_ids: String, //一次订单中所有品类的ID集合
order_product_ids: String, //一次订单中所有商品的ID集合
pay_category_ids: String, //一次支付中所有品类的ID集合
pay_product_ids: String, //一次支付中所有商品的ID集合
city_id: Long) //城市 id
// 定义样例类存储商品品类及对应的操作次数
// 样例类的属性默认使用val修饰,不可重新赋值
case class CategoryCountInfo(categoryId: String, //品类id
var clickCount: Long, //点击次数
var orderCount: Long, //订单次数
var payCount: Long) //支付次数
Código de demanda 1
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[String] = sc.textFile("D:\\学习资料\\spark\\spark\\2.资料\\spark-core数据\\user_visit_action.txt")
// 封装对象
val userActionRDD: RDD[UserVisitAction] = dataRDD.map {
line => {
val lineSplit: Array[String] = line.split("_")
// 封装对象
UserVisitAction(
lineSplit(0),
lineSplit(1).toLong,
lineSplit(2),
lineSplit(3).toLong,
lineSplit(4),
lineSplit(5),
lineSplit(6).toLong,
lineSplit(7).toLong,
lineSplit(8),
lineSplit(9),
lineSplit(10),
lineSplit(11),
lineSplit(12).toLong
)
}
}
// 转换数据格式
val cateInfoRDD: RDD[(String, CategoryCountInfo)] = userActionRDD.flatMap {
userAction => {
// 判断操作类型
if (userAction.click_category_id != -1) {
// 转换数据格式 (品类, CategoryCountInfo对象)
List((userAction.click_category_id.toString,
CategoryCountInfo(userAction.click_category_id.toString, 1, 0, 0)))
} else if (userAction.order_category_ids != "null") {
// 处理order_category_ids
val cateIds: Array[String] = userAction.order_category_ids.split(",")
// ListBuffer存储多个对象
val list = new mutable.ListBuffer[(String, CategoryCountInfo)]()
for (cateId <- cateIds) {
list.append((cateId, CategoryCountInfo(cateId, 0, 1, 0)))
}
list
} else if (userAction.pay_category_ids != "null") {
val cateIds: Array[String] = userAction.pay_category_ids.split(",")
// ListBuffer存储多个对象
val list = new mutable.ListBuffer[(String, CategoryCountInfo)]()
for (cateId <- cateIds) {
list.append((cateId, CategoryCountInfo(cateId, 0, 0, 1)))
}
list
} else {
// 返回空集合
Nil
}
}
}
// 根据key聚合数据
val reduceRDD: RDD[(String, CategoryCountInfo)] = cateInfoRDD.reduceByKey(
(cate1, cate2) => {
cate1.clickCount = cate1.clickCount + cate2.clickCount
cate1.orderCount = cate1.orderCount + cate2.orderCount
cate1.payCount = cate1.payCount + cate2.payCount
cate1
}
)
// 去掉多余的key,转换格式
val cateCountRDD: RDD[CategoryCountInfo] = reduceRDD.map {
_._2
}
// 排序取前10
val resArr: Array[CategoryCountInfo] = cateCountRDD.sortBy(
// 元组可以按照元素的顺序来依次排序
cate =>{
(cate.clickCount,cate.orderCount,cate.payCount)},
// 倒序
false
).take(10)
sc.stop()
Demanda 2: Top10 de estadísticas de sesiones activas para cada categoría en el Top10 de categorías populares
Declaración de necesidades
Para las 10 categorías principales, obtenga el sessionId de los 10 clics principales para cada categoría. (Nota: aquí solo nos enfocamos en el número de clics, no en el número de pedidos y pagos).
Para la categoría de los 10 primeros, cada uno debe obtener el sessionId que se ubica entre los 10 primeros en el número de clics. Esta función nos permite ver la categoría que más le interesa en un determinado grupo de usuarios, y el comportamiento de sesión de los usuarios más habituales en cada categoría.
análisis de demanda
- Obtenga el ID de la categoría top10 popular de la demanda 1.
- Filtre los datos, el valor conserva la identificación de la categoría popular top10 y el registro de clics correspondiente.
- Convierta el formato de datos (categoría id_session, 1).
- Agregue los datos anteriores y cuente el número de clics de sesión para cada categoría.
- Convertir formato de datos (ID de categoría, (sesión, recuento)).
- Agrupar por categoría.
- Ordene en orden inverso, tomando los 10 primeros para cada grupo.
Código
- El requisito 2 debe basarse en el resultado del requisito 1.
// =======================================上面是需求1=============================================
// 取出top10的商品id
val top10Ids: Array[String] = resArr.map(_.categoryId)
// top10Ids要发送到每个task,可以做广播变量优化
val broadcast: Broadcast[Array[String]] = sc.broadcast(top10Ids)
// 过滤数据,只保留top10 id对应的点击数据
val filterRDD: RDD[UserVisitAction] = userActionRDD.filter(
// 注意click_category_id的类型是Long类型,需要转换为String类型
datas => {
if (datas.click_category_id != -1) {
broadcast.value.contains(datas.click_category_id.toString)
} else {
false
}
}
)
// 转换格式 (品类id_session, 1)
val cateIdAndSession1: RDD[(String, Int)] = filterRDD.map(
datas => {
(datas.click_category_id + "_" + datas.session_id, 1)
}
)
// 按照相同的key聚合 (品类id_session, count)
val cateIdAndSessionCount: RDD[(String, Int)] = cateIdAndSession1.reduceByKey(_ + _)
// 转换数据格式 (品类id, (session, count))
val cateIdAndSessionCount2: RDD[(String, (String, Int))] = cateIdAndSessionCount.map {
case (idAndSession, count) => {
val split: Array[String] = idAndSession.split("_")
(split(0), (split(1), count))
}
}
// 按照品类分组
val cateGroupRDD: RDD[(String, Iterable[(String, Int)])] = cateIdAndSessionCount2.groupByKey()
// 倒序排序,取前10
val res2RDD: RDD[(String, List[(String, Int)])] = cateGroupRDD.mapValues(
datas => {
val list: List[(String, Int)] = datas.toList
// 排序
list.sortWith(_._2 > _._2)
}.take(10)
)
res2RDD.foreach(println)
sc.stop()
Requisito 3: Estadísticas de la tasa de salto de una sola página
Declaración de necesidades
Calcule la tasa de conversión de un solo salto de página, cuál es la tasa de conversión de un solo salto de página, por ejemplo, la ruta de la página 3,5,7,9,10,21 a la que accede un usuario durante una sesión, luego la página 3 salta a la página 5 y se llama una vez Salto único, 7-9 también se denomina salto único, luego la tasa de salto único es para contar la probabilidad de clics en la página.
Por ejemplo: Calcule la tasa de salto único de 3-5, primero obtenga el número de visitas (PV) de la página 3 de la sesión elegible como A, y luego obtenga el número de visitas (PV) de la sesión elegible a la página 3 y luego a la página 5 El número de veces es B, luego B / A es la tasa de salto único de página de 3-5.
análisis de demanda
- Primero puede contar el número de visitas a cada página
-> primero convierta el formato de datos: (ID de página, 1)
-> luego agregue de acuerdo con el ID de página para encontrar el número total de visitas a cada página (ID de página, contar)
-> Luego contar página A-> página B-> página C-> página D ... tiempos de salto único - Ordene el tiempo de acceso del usuario según el id de sesión y el id de la página (id de sesión-id de la página, tiempo de acceso)
- Convertir el formato de datos, agrupar por
id de sesión -> sesión1: página A-> página B-> página C
-> sesión2: -> página A-> página B-> página C - Devolver la colección Lista de la secuencia de acceso en cada grupo (la secuencia de acceso a la página de cada usuario)
-> Secuencia de acceso a la página: A -> B -> C -> D -> E
-> Hacer una cremallera con la cola de la colección : B-> C -> D -> E
-> (A, B) (B, C) (C, D) (D, E) - Calcula el número de veces que aparece cada elemento del conjunto formado por la cremallera, es decir, el número de saltos individuales para cada página ((A, B), recuento)
- Finalmente, use el número de saltos individuales por página / el número total de veces por página = tasa de salto único de página
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[*]")
val sc = new SparkContext(conf)
val dataRDD: RDD[String] = sc.textFile("D:\\学习资料\\spark\\spark\\2.资料\\spark-core数据\\user_visit_action.txt")
// 封装对象
val userVisitActionRDD: RDD[UserVisitAction] = dataRDD.map {
line => {
val lineSplit: Array[String] = line.split("_")
// 封装对象
UserVisitAction(
lineSplit(0),
lineSplit(1).toLong,
lineSplit(2),
lineSplit(3).toLong,
lineSplit(4),
lineSplit(5),
lineSplit(6).toLong,
lineSplit(7).toLong,
lineSplit(8),
lineSplit(9),
lineSplit(10),
lineSplit(11),
lineSplit(12).toLong
)
}
}
// 先统计每个页面的访问次数
// (页面id,1) -> (页面id,count)
val pageAnd1: RDD[(Long, Long)] = userVisitActionRDD.map(
action => {
(action.page_id, 1L)
}
)
// 按照pageId聚合,每个页面的访问次数, 转为map字典,方便使用
val pageAndCount: Map[Long, Long] = pageAnd1.reduceByKey(_ + _).collect().toMap
// 根据sessionid和pageid,按照时间排序
val sessionAndPage: RDD[(String, String)] = userVisitActionRDD.map(
action => {
// 转换格式 (sessionid_pageid, 时间)
(action.session_id + "_" + action.page_id, action.action_time)
}
)
// 按照sessionid分组,按照时间正序排序
// 转换格式 (sessionid, (pageid,时间))
val sessionPageTime: RDD[(String, (String, String))] = sessionAndPage.map {
case (session_page, time) => {
val split: Array[String] = session_page.split("_")
(split(0), (split(1), time))
}
}
// 按照sessionid分组,每个用户的访问页面和时间
val sessionGroup: RDD[(String, Iterable[(String, String)])] = sessionPageTime.groupByKey()
// 转换格式,舍弃sessionid Iterable(pageid,时间)
val pageTime: RDD[Iterable[(String, String)]] = sessionGroup.map(_._2)
// 按照时间正序排序 Iterable(pageid,时间)
val pageSortRDD: RDD[Iterable[(String, String)]] = pageTime.map(
data => {
data.toList.sortWith(_._2 < _._2)
}
)
//转换格式,舍弃时间 Iterable(pageid)
val pageRDD: RDD[List[String]] = pageSortRDD.map(
datas => {
datas.toList.map(_._1)
}
)
// 拉链操作,组成((A,B),1) 的形式,方便计算从A到B的跳转数
val zipRDD: RDD[((String, String), Long)] = pageRDD.flatMap(
pageList => {
pageList.zip(pageList.tail).map((_, 1L))
}
)
val breakCount: RDD[((String, String), Long)] = zipRDD.reduceByKey(_ + _)
// breakCount.take(3).foreach(println)
// 计算A到B的跳转数
// 跳转数 / 页面访问数
val resRDD: RDD[String] = breakCount.map {
case (breakPage, count) => {
val sum: Long = pageAndCount.getOrElse(breakPage._1.toLong, 1)
val res: Double = count * 1.0 / sum
breakPage + ":" + res
}
}
resRDD.foreach(println)
//breakRDD.take(3).foreach(println)
sc.stop()