En la nota de tormenta: aplicación Trident , hablé del uso de Trident, aquí hablé de los cambios en el estado de Trident y el uso de la API correspondiente.
El contenido de este artículo proviene de Trident State , y parte del contenido se modifica en función de las condiciones reales.
Trident tiene herramientas abstractas de primera clase para leer y escribir datos de estado. El estado se puede almacenar dentro de la topología, como en el contenido y almacenado por HDFS, o almacenado en la base de datos a través de almacenamiento externo (como Memcached o Cassandra). Para la API de Trident, no hay diferencia entre estos dos mecanismos.
Trident administra el estado de manera tolerante a fallas, de modo que las actualizaciones de estado en caso de reintento o falla sean idempotentes. En el procesamiento de big data, la idempotencia del procesamiento de datos es un indicador muy importante, que puede garantizar que incluso si cada mensaje se procesa varias veces, el resultado es como si se procesara solo una vez.
Es posible que se requieran varios niveles de tolerancia a fallas al realizar actualizaciones de estado. Antes de eso, veamos un ejemplo para ilustrar las habilidades necesarias para lograr la semántica "exactamente una vez". Por ejemplo, los datos de la secuencia se cuentan y se agregan, y cada vez que se procesa una nueva tupla, el resultado del recuento en ejecución se almacenará en la base de datos.
Si ocurre una falla, la tupla volverá a ejecutar la operación de conteo. Esto causará problemas al realizar una actualización de estado, porque en este momento no se sabe si se ha actualizado el estado de la tupla. Quizás los datos de la tupla aún no se hayan procesado y el recuento deba aumentarse en este momento. Quizás la tupla se haya procesado y el recuento se haya aumentado correctamente, pero hay un problema en el siguiente paso. En este caso, no se debe aumentar el recuento. También es posible que el procesamiento de tuplas sea normal y el recuento de actualizaciones sea anormal. En este momento, es necesario actualizar el recuento.
Por lo tanto, si simplemente almacena la información del recuento en la base de datos, no sabe si la tupla se ha procesado. Por lo tanto, se necesita más información como ayuda. Trident proporciona las siguientes tres propiedades para lograr un procesamiento "exactamente una vez":
- Las tuplas se procesan en pequeños lotes.
- A cada lote de tuplas se le dará un ID único llamado ID de transacción (txid). Si el lote se procesa repetidamente, el txid será el mismo.
- La operación de actualización de estado se realiza en el orden de lotes de tuplas. En otras palabras, el estado del lote 3 no se actualizará hasta que el estado del lote 2 se actualice correctamente.
De acuerdo con estas características, es posible verificar si el lote de la tupla ha sido procesado y tomar las acciones adecuadas para actualizar el estado de acuerdo con el resultado de la detección. La acción específica que se tome depende del tipo de boquilla. Hay tres tipos de Spout: "no transaccional", "transaccional" y "transaccional opaco". La tolerancia a fallos correspondiente también es de tres tipos: "no transaccional", "transacción" y "transacción opaca". Echemos un vistazo a los distintos tipos de Spout y la tolerancia a fallas correspondiente.
Spout transaccional
Trident envía tuplas en lotes para su procesamiento, y cada lote de tuplas recibe un ID de transacción único. Las características de Spout se determinan en función del mecanismo de garantía de tolerancia a fallos que proporcionan, y este mecanismo también afectará a cada lote. Transactional Spout tiene las siguientes características:
- El txid de cada lote no cambia. Para un txid específico, cuando se repite la ejecución, los datos de tupla que contiene son exactamente los mismos que la primera vez.
- Las tuplas solo aparecerán en un lote y no se repetirán (una tupla solo aparecerá en un lote y no aparecerá en varios lotes).
- Cada tupla aparecerá una vez (no se perderán datos de tupla)
Este es el tipo Spout más simple y fácil de entender. El flujo de datos se divide en lotes fijos. Hay una extensión de Spout transaccional integrado con Kafka en Storm, y el código está aquí .
Dado que Spout transaccional es tan simple y fácil de entender, ¿por qué no utilizar Spout transaccional completamente en Trident? De hecho, radica en su tolerancia a fallos. Por ejemplo, TransactionalTridentKafkaSpoutel método de trabajo es que el lote del mismo txid contendrá las tuplas de todas las particiones de Kafka. Una vez que se emite un lote, se produce una excepción y debe volver a emitirse, y se requiere exactamente el mismo conjunto de tuplas para cumplir con la semántica requerida por Spout transaccional. Pero en este momento, si un cierto nodo en Kafka es anormal (el nodo está inactivo o la partición no está disponible), no se puede obtener exactamente el mismo lote de tuplas, y toda la topología debe detenerse para la tercera semántica (ejecución por lotes en secuencia).
Esta es la razón del Spout de "tipo de transacción opaca", que puede tolerar la pérdida del nodo de la fuente de datos y puede garantizar que los datos se utilicen exactamente una vez.
Nota: Aquellos que estén familiarizados con Kafka deben pensar que si un tema admite la replicación, incluso si un nodo no está disponible, habrá otros nodos de replicación en la parte superior, entonces TransactionalTridentKafkaSpout también puede evitar los problemas anteriores.
Sigamos para ver cómo diseñar una implementación de estado que admita la semántica de Spout "transaccional" (en resumen, los datos de tupla por lotes correspondientes al mismo txid son exactamente los mismos) que admita exactamente una característica. Este estado se llama "estado transaccional".
Por ejemplo, ahora hay una topología de recuento de palabras y el recuento de palabras debe almacenarse en la base de datos de clave / valor. La clave es una palabra y el valor contiene el número de palabras. Además, para determinar si se ha ejecutado el mismo lote de tuplas, el txid debe almacenarse en el valor. De esta forma, cuando sea necesario actualizar el número de palabras, primero compare si el txid es el mismo y, si son iguales, omita la actualización. Si son diferentes, actualice el recuento.
Considere este ejemplo de por qué funciona. Suponga que está procesando txid 3 que consta de las siguientes tuplas de lote:
Por ejemplo, para procesar un lote de tuplas cuyo txid es 3:
["man"]
["man"]
["dog"]Los datos almacenados actualmente en la base de datos son:
man => [count=3, txid=1]
dog => [count=4, txid=3]
apple => [count=10, txid=2]En este momento, se encuentra que el txid correspondiente a "man" es 1, y el txid actual es 3, y se puede actualizar. Entonces, el txid correspondiente a "perro" es 3, lo que indica que se ha enviado el mismo lote de datos de tupla y no es necesario actualizarlo. A partir de este punto, se puede ver que las tuplas de lote con un txid de 3. Después de actualizar el número de "perro" y antes de actualizar el número de "hombre", ocurrió un error. El resultado final es:
man => [count=5, txid=3]
dog => [count=4, txid=3]
apple => [count=10, txid=2]Pico transaccional opaco
Como se mencionó anteriormente, el Spout transaccional opaco no puede garantizar que los datos de tupla en el lote correspondiente al mismo txid sean completamente consistentes. Sus características son las siguientes:
- Cada tupla se procesará correctamente en un solo lote.
[OpaqueTridentKafkaSpout](http://github.com/apache/storm/tree/v1.1.0/external/storm-kafka/src/jvm/org/apache/storm/kafka/trident/OpaqueTridentKafkaSpout.java)Con esta función, también es muy tolerante a las anomalías del nodo kafka. OpaqueTridentKafkaSpoutAl enviar un lote de tuplas, se enviará desde la posición posterior al último éxito, para garantizar que las tuplas no se pierdan ni se retransmitan.
Con base en las características anteriores, el Spout transaccional opaco es diferente de txid para determinar directamente si se puede omitir la actualización de estado, porque las tuplas en los lotes con el mismo txid pueden haber cambiado.
Esto requiere almacenar más información de estado, no solo un resultado y un txid, sino también el valor del resultado anterior.
Por ejemplo, el recuento de lotes actual es 2 y se requiere una actualización de estado. Los datos en la base de datos son los siguientes:
{
"value": 4,
"prevValue": 1,
"txid": 2
}Si el txid actual es 3, es diferente de la base de datos. En este caso, el prevValuevalor es el valuevalor valuedel valor aumentado de 2, se actualiza txida 3, el resultado final es:
{
"value": 6,
"prevValue": 4,
"txid": 3
}Si el txid actual es 2, es igual al txid en la base de datos. Debido a que el txid es el mismo, significa que el procesamiento por lotes con el txid de 2 falló la última vez, pero la tupla de este tiempo puede ser diferente de la última vez. En este momento, es necesario utilizar estos datos para sobrescribir el último resultado de procesamiento. Es decir, el prevValuevalor no cambia, valueel valor se cambia para prevValueaumentar en 2, txidsin cambios, y el resultado final es el siguiente:
{
"value": 3,
"prevValue": 1,
"txid": 2
}La viabilidad de este enfoque depende de la fuerte secuencia de Trident. En otras palabras, una vez que se procesa un nuevo lote, el lote anterior no se repetirá. El Spout transaccional opaco asegura que no haya duplicación entre diferentes lotes, es decir, cada tupla solo se procesará con éxito en un lote, por lo que puede usar de manera segura el valor anterior y el valor actual para sobrescribir los datos existentes.
Spout no transaccional
Spout no transaccional no puede ofrecer ninguna garantía para los lotes. Por lo tanto, puede haber un procesamiento "al menos una vez", es decir, falla durante un procesamiento por lotes, pero no se volverá a procesar; también puede proporcionar un procesamiento "al menos una vez", es decir, puede haber varios lotes para procesar. un determinado lote por separado Tuplas. Es decir, no hay forma de lograr la semántica de "exactamente una vez".
Resumen de diferentes tipos de picos y estados
Lo siguiente es si diferentes combinaciones de canalización / estado admiten la semántica de procesamiento "exactamente una vez":
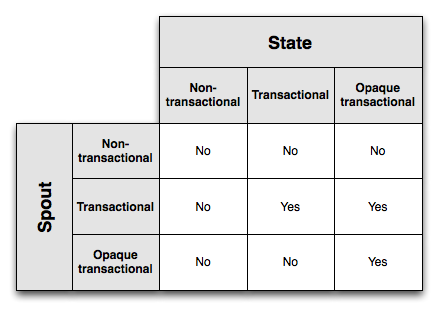
El estado de transacción opaco tiene la tolerancia a fallas más fuerte, pero debido a que almacenar txid y dos resultados trae una mayor sobrecarga. El estado transaccional solo necesita almacenar un resultado de estado, pero solo es válido para Spout transaccional. El estado no transaccional requiere que se almacenen menos datos, pero no puede lograr la semántica de procesamiento "exactamente una vez".
Por lo tanto, al elegir la tolerancia a fallas y el espacio de almacenamiento, debe elegir una combinación adecuada de acuerdo con sus necesidades específicas.
API de estado
Desde el punto de vista anterior, el principio de la semántica "exactamente una vez" es un poco complicado, pero como usuario, no es necesario que comprenda estas comparaciones txid y el almacenamiento de valores múltiples, porque Trident ha encapsulado todos los valores tolerantes a fallas. procesamiento de la lógica en el estado, solo hay que pensar en ello y llevar el código servirá:
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(MemcachedState.opaque(serverLocations), new Count(), new Fields("count"))
.parallelismHint(6);En él se ha encapsulado toda la lógica de estado de transacción opaca MemcachedState.opaque. Además, las actualizaciones de estado se ajustarán automáticamente a las operaciones por lotes, lo que puede reducir el desperdicio de recursos causado por interacciones repetidas con la base de datos.
La Stateinterfaz básica tiene solo dos métodos:
public interface State {
void beginCommit(Long txid); // 对于像DRPC流发生的partitionPersist这样的事情,可以是null
void commit(Long txid);
}Como se mencionó anteriormente, el txid se obtendrá al principio y al final de la actualización de estado. A Trident no le importa cómo se opera el estado, qué método se usa para actualizar y qué método se usa para leer.
Si tiene una base de datos personalizada que contiene información sobre la dirección del usuario, debe usar Trident para interactuar con la base de datos. La Stateclase extendida contiene métodos getter y setter para la información del usuario:
public class LocationDB implements State {
public void beginCommit(Long txid) {
}
public void commit(Long txid) {
}
public void setLocation(long userId, String location) {
// 向数据库设置地址信息
}
public String getLocation(long userId) {
// 从数据库中获取地址信息
}
}Entonces necesitas uno StateFactorypara crear los Stateobjetos que LocationDBnecesita Trident . La StateFactoryestructura general requerida es la siguiente:
public class LocationDBFactory implements StateFactory {
public State makeState(Map conf, int partitionIndex, int numPartitions) {
return new LocationDB();
}
}Trident proporciona una QueryFunctioninterfaz para consultar la fuente de estado y una interfaz para actualizar la fuente de estado StateUpdater. Por ejemplo, la LocationDBinformación del usuario en la consulta QueryLocation:
TridentTopology topology = new TridentTopology();
TridentState locations = topology.newStaticState(new LocationDBFactory());
topology.newStream("myspout", spout)
.stateQuery(locations, new Fields("userid"), new QueryLocation(), new Fields("location"));QueryLocationEl código es el siguiente:
public class QueryLocation extends BaseQueryFunction<LocationDB, String> {
public List<String> batchRetrieve(LocationDB state, List<TridentTuple> inputs) {
List<String> ret = new ArrayList();
for (TridentTuple input : inputs) {
ret.add(state.getLocation(input.getLong(0)));
}
return ret;
}
public void execute(TridentTuple tuple, String location, TridentCollector collector) {
collector.emit(new Values(location));
}
}QueryFunctionLa operación se divide en dos pasos: Primero, Trident coloca los datos recopilados en un lote y los envía al batchRetrievemétodo. En este ejemplo, el batchRetrievemétodo recibió alguna identificación de usuario. batchRetrieveDevolverá un conjunto de resultados con la misma longitud que la tupla de entrada. Los elementos de la tupla de entrada y el resultado de salida se corresponden entre sí.
Desde este punto de vista, la LocationDBclase anterior no aprovecha el procesamiento por lotes de Trident, por lo que debe modificarse con todos los esfuerzos:
public class LocationDB implements State {
public void beginCommit(Long txid) {
}
public void commit(Long txid) {
}
public void setLocationsBulk(List<Long> userIds, List<String> locations) {
// set locations in bulk
}
public List<String> bulkGetLocations(List<Long> userIds) {
// get locations in bulk
}
}Las QueryLocationclases correspondientes son las siguientes:
public class QueryLocation extends BaseQueryFunction<LocationDB, String> {
public List<String> batchRetrieve(LocationDB state, List<TridentTuple> inputs) {
List<Long> userIds = new ArrayList<Long>();
for (TridentTuple input : inputs) {
userIds.add(input.getLong(0));
}
return state.bulkGetLocations(userIds);
}
public void execute(TridentTuple tuple, String location, TridentCollector collector) {
collector.emit(new Values(location));
}
}Este código reduce en gran medida las operaciones de la base de datos.
Para el estado de actualización, se puede utilizar la StateUpdaterinterfaz. Por ejemplo, la siguiente operación de actualización:
public class LocationUpdater extends BaseStateUpdater<LocationDB> {
public void updateState(LocationDB state, List<TridentTuple> tuples, TridentCollector collector) {
List<Long> ids = new ArrayList<Long>();
List<String> locations = new ArrayList<String>();
for (TridentTuple t : tuples) {
ids.add(t.getLong(0));
locations.add(t.getString(1));
}
state.setLocationsBulk(ids, locations);
}
}La topología de la operación de actualización correspondiente puede ser así:
TridentTopology topology = new TridentTopology();
TridentState locations =
topology.newStream("locations", locationsSpout)
.partitionPersist(new LocationDBFactory(), new Fields("userid", "location"), new LocationUpdater());partitionPersistEl método actualiza el estado y la StateUpdaterinterfaz recibe un lote de tuplas e información de estado, y luego actualiza el estado. La LocationUpdaterclase anterior simplemente toma la identificación del usuario y la información de la dirección de la tupla, y luego realiza el procesamiento por lotes en el estado. Luego, partitionPersistse devolverá un TridentStateobjeto que representa el estado actualizado . Luego, puede usar el stateQuerymétodo para consultar el estado en cualquier otro lugar de la topología .
Hay un parámetro en StateUpdaterel updateStatemétodo TridentCollector, este objeto puede enviar las tuplas enviadas a un nuevo flujo de datos. No se utiliza en este ejemplo. Si necesita realizar operaciones posteriores, como actualizar el valor de recuento en la base de datos, puede TridentState#newValuesStreamobtener nuevos datos de flujo de datos a través de métodos.
persistentAggregate
Trident usa un persistentAggregatemétodo llamado estado de actualización. Ha aparecido antes, así que escríbalo de nuevo aquí:
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));partitionPersistEs un método que recibe el agregador Trident como parámetro y actualiza los datos de estado, persistentAggregatees partitionPersistuna abstracción de programación construida en la capa superior. En este ejemplo, al groupBydevolver un paquete de datos, Trident necesita un MapStateobjeto que implemente la interfaz. El campo de agrupación es la clave del estado y el resultado de la agregación es el valor del estado. MapStateLa interfaz es la siguiente:
public interface MapState<T> extends State {
List<T> multiGet(List<List<Object>> keys);
List<T> multiUpdate(List<List<Object>> keys, List<ValueUpdater> updaters);
void multiPut(List<List<Object>> keys, List<T> vals);
}Si necesita realizar operaciones de agregación en flujos de datos no agrupados, Trident necesita un Snapshottableobjeto que implemente la interfaz:
public interface Snapshottable<T> extends State {
T get();
T update(ValueUpdater updater);
void set(T o);
}Tanto MemoryMapState como MemcachedState implementan estas interfaces.
Implementar la interfaz MapState
Implementar la MapStateinterfaz es muy simple, Trident ha hecho casi todo. OpaqueMap, TransactionalMapE NonTransactionalMapimplementar su propia semántica tolerante a fallas respectivamente. Solo es necesario proporcionar una implementación para la adquisición y modificación por lotes de diferentes claves / valores para estas clases IBackingMap. IBackingMapLa interfaz es la siguiente:
public interface IBackingMap<T> {
List<T> multiGet(List<List<Object>> keys);
void multiPut(List<List<Object>> keys, List<T> vals);
}OpaqueMapEl método se llamará utilizando OpaqueValue como parámetro vals multiPut; TransactionalValueTransactionalMap se utilizará como parámetro; y el objeto de topología se pasará directamente.NonTransactionalMaps
Trident también proporciona la clase CachedMap para realizar la operación automática de almacenamiento en caché de LRU de clave / valor.
Finalmente, Trident también proporciona la clase SnapshottableMap , que convierte MapStateobjetos en Snapshottableobjetos almacenando los resultados de la agregación global en una clave fija .
Puede consultar la implementación de MemcachedState para aprender cómo combinar estas herramientas para proporcionar una MapStateimplementación de alto rendimiento . MemcachedStateAdmite semánticas opacas de transacciones, transacciones y no transacciones.
Página de inicio personal: http://www.howardliu.cn
Publicación de blog personal: notas de tormenta: estado de tridente
Página de inicio de CSDN: http://blog.csdn.net/liuxinghao
Publicación de blog de CSDN: notas de tormenta: estado de tridente