Directorio de artículos
Prefacio
El almacén de datos de Hive ocupa una posición extremadamente importante en la familia ecológica Hadoop, y se utiliza mucho en los negocios reales. Se puede decir que la razón por la que Hadoop es tan popular se debe en gran parte a la existencia de Hive. Especialmente para el negocio de almacenamiento de datos fuera de línea, se basa básicamente en un diseño jerárquico de colmena, complementado con un sistema de programación, para completar la ejecución de tiempo de todo el negocio de almacenamiento de datos. Esta publicación de blog está escrita haciendo referencia a los excelentes artículos de otros bloggers y combinando mi propia comprensión y operación práctica.
1. Conceptos básicos de Hive
1.1 ¿Qué es Hive?
Hive: Facebook es de código abierto para resolver las estadísticas de datos de registros estructurados masivos. Es una herramienta de almacenamiento de datos basada en el ecosistema de big data hadoop, que puede mapear archivos de datos estructurados en una tabla y proporcionar funciones de consulta similares a SQL. Su esencia es transformar HQL en un programa MapReduce.

Como se puede ver en el diagrama, Hive es hasta cierto punto un paquete de muchos marcos "SQL-MapReduce". Puede analizar el lenguaje Sql escrito por el usuario en el programa MapReduce correspondiente, y finalmente El resultado del cálculo se forma a través del marco de cálculo de MapReduce y se envía al Cliente.
1.2 Ventajas y desventajas de Hive
Ventajas :
① La interfaz de operación adopta una sintaxis similar a SQL para proporcionar capacidades de desarrollo rápido.
② Evita escribir MapReduce y reduce el costo de aprendizaje de los desarrolladores.
③ El retraso de ejecución de Hive es relativamente alto, por lo que Hive se usa a menudo para análisis de datos y ocasiones en las que los requisitos en tiempo real no son altos.
④ La ventaja de Hive radica en el procesamiento de macrodatos, pero no tiene ninguna ventaja en el procesamiento de datos pequeños, porque Hive tiene un retraso de ejecución relativamente alto.
⑤ Hive admite funciones definidas por el usuario y los usuarios pueden implementar sus propias funciones de acuerdo con sus necesidades.
Desventajas:
① La capacidad de expresión HQL de Hive es limitada.
② Los algoritmos iterativos no se pueden expresar.
③ La eficiencia de Hive es relativamente baja
④ El trabajo MapReduce generado automáticamente por Hive no suele ser lo suficientemente inteligente.
⑤ El ajuste de Hive es difícil y la granularidad es relativamente gruesa.
1.3 Principio de la arquitectura de Hive

1. Interfaz de usuario:
CLI de cliente (hive shell), JDBC / ODBC (hive de acceso a Java), WEBUI (hive de acceso al navegador).
2. Metadatos: los
metadatos de Metastore incluyen: nombre de la tabla, base de datos a la que pertenece la tabla (el valor predeterminado es el predeterminado), propietario de la tabla, campo de columna / partición, tipo de tabla (si es una tabla externa), el directorio donde se encuentran los datos de la tabla. etc. Hive almacena la información de metadatos en la tabla en la base de datos, como derby (integrado), Mysql (configurado en el trabajo real). La información de metadatos en Hive incluye el nombre de la tabla, las columnas y particiones de la tabla, y los atributos de la tabla (ya sea una tabla externa, etc.), el directorio donde se ubican los datos de la tabla, etc. El analizador de Hive lee la información relevante en MetaStore cuando se está ejecutando. Déjame decirte por qué no usas la base de datos derby de Hive en los negocios reales y necesitas reconfigurar una nueva base de datos Mysql para ella, porque la base de datos derby tiene grandes limitaciones: la base de datos derby no permite que los usuarios la abran. puede ser compartido por varios clientes, solo un cliente puede abrirlo para operarlo, es decir, solo un usuario puede usarlo al mismo tiempo. Naturalmente, esto es muy inconveniente en el trabajo, por lo que tenemos que reabrirlo. Configurar una base de datos .
3. Hadoop
usa HDFS para almacenamiento y MapReduce para cálculos.
4. Controlador: Controlador
① Analizador (Analizador SQL): convierte cadenas SQL en AST de árbol de sintaxis abstracta, este paso generalmente se completa con una biblioteca de herramientas de terceros, como antlr; realiza un análisis gramatical en el AST, como si la tabla existe, el campo Si existe y si la semántica de SQL es incorrecta.
② Compilador (plan físico): compila AST para generar un plan de ejecución lógico.
③ Optimizer (Query Optimizer): optimiza el plan de ejecución lógica.
④ Ejecución: convierta el plan de ejecución lógica en un plan físico que se pueda ejecutar. Para Hive, es MR / Spark.
Como se puede ver en la arquitectura anterior, con la ayuda de HDFS y MapReduce y MySql de Hadoop, Hive realmente usa el analizador de Hive para analizar la declaración SQl del usuario en el programa MapReduce correspondiente, es decir, Hive es solo una herramienta de cliente, que es por qué no tuvimos distribución y pseudodistribución durante la construcción de Hive. (Hive es como Liu Bang, usando la ayuda de Zhang Liang, Han Xin y Xiao He razonablemente, ¡logrando así mucho!).
1.4 Mecanismo de funcionamiento de la colmena

El mecanismo operativo de Hive es como se muestra en la figura: después de que se crea la tabla, los usuarios solo necesitan escribir declaraciones Sql de acuerdo con los requisitos comerciales, y luego el marco de Hive analizará las declaraciones Sql en el programa MapReduce correspondiente y ejecutará el trabajo. a través del marco informático MapReduce para obtener nuestros resultados finales del análisis. Durante el funcionamiento de Hive, los usuarios solo necesitan crear tablas, importar datos y escribir declaraciones de análisis SQL. El resto del proceso lo completará automáticamente el marco Hive. Crear tablas, importar datos y escribir declaraciones de análisis SQL es en realidad el conocimiento de la base de datos., el proceso operativo de Hive también explica por qué la existencia de Hive reduce el umbral de aprendizaje de Hadoop y por qué Hive ocupa una posición tan importante en la familia Hadoop.
En segundo lugar, el funcionamiento de Hive
Después de una comprensión preliminar de los conceptos básicos de Hive, practicaremos Hive. El llamado " Siempre es superficial en el papel, y sé absolutamente que este asunto debe practicarse ". Primero cree un texto en formato txt, los datos son los siguientes:
id city name sex
1 beijing zhangli man
2 guizhou lifang woman
3 tianjin wangwei man
4 chengde wanghe woman
5 beijing lidong man
6 lanzhou wuting woman
7 beijing guona woman
8 chengde houkuo man
Las operaciones de Hive son en realidad operaciones de tabla y operaciones de base de datos para los usuarios. Lo siguiente se centrará en dos aspectos.
2.1 Tablas de Hive: creación de tablas internas, tablas externas y tablas de partición
La llamada tabla interna es una tabla normal y el formato de sintaxis de creación es:
create table tablename #内部表名
(
id int, #字段名称,字段类型
city string,
name string,
sex string
)
row format delimited #一行文本对应表中的一条记录
fields terminated by ‘\t’#指定输入文件字段的间隔符,即输入文件的字段是用什么分割开的。
Operación real (usando el modo de cliente beeline):
beeline -u jdbc:hive2://node1:10000 -n "用户名" -p "密码"


Resultado: el

formato de sintaxis para crear una tabla externa es:
create external table teblename #外部表名
(
id int,
city string,
name string,
sex string
)
row format delimited #一行文本对应一条记录
fields terminated by ‘\t’ #输入文件的字段是用什么分割开的。
location ‘hdfs://mycluster/testDir’#与hdfs中的文件建立链接。
注意:最后一行写到的是目录testDir,文件就不用写了,Hive表会自动testDir目录下读取所有的文件file。实际的操作过程当中发现,location关联到的目录下面必须都是文件,不能含有其余的文件夹,不然读取数据的时候会报错。
Operación real:
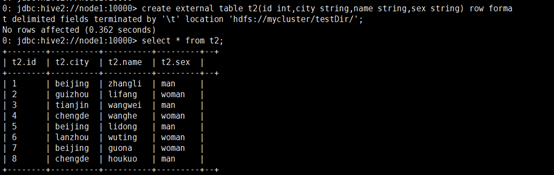
la diferencia entre tablas internas y tablas externas:
en el proceso de carga de datos de tablas internas, los datos reales se moverán al directorio del almacén de datos (hive.metastore.warehouse.dir), y luego el acceso del usuario al Los datos estarán directamente en el directorio del almacén de datos (hive.metastore.warehouse.dir). Completado en el catálogo del almacén de datos; cuando se elimina la tabla interna, la información de datos y metadatos en la tabla interna se eliminará al mismo tiempo.
Cuando la tabla externa está cargando datos, los datos reales no se moverán al directorio del almacén de datos, sino que se establece un vínculo con la tabla externa (equivalente a un acceso directo a un archivo); cuando se elimina la tabla externa, solo se elimina el vínculo . Suplemento: En mi trabajo, encontré que para las tablas externas, incluso si se elimina la tabla en la colmena, la ubicación de la tabla en HDFS todavía existe.
Tabla de particiones
El concepto de tabla de particiones: se refiere al hecho de que nuestros datos pueden ser particionados, es decir, el archivo se divide en diferentes estándares según un determinado campo. La creación de la tabla de particiones se realiza habilitando particionado por al crear el mesa.
El formato de sintaxis de la creación de la tabla de particiones es:
create table tablename #分区表名
(
id int, #字段名称 字段类型
city string,
name string,
sex string
)
partitioned by(day int) #分区表字段
row format delimited #一行文本对应一条记录
fields terminated by ‘\t’ #输入文件的字段是用什么分割开的。
注意:分区表在加载数据的过程中要指定分区字段,否则会报错,正确的加载方式如下:
load data local inpath ‘/usr/local/consumer.txt’ into table t1 partition (day=2);
其余的操作和内部表、外部表是一样的。
Operación real:

2.2 Cargue (importe) el archivo de datos en la tabla de Hive
Una vez creada la tabla en Hive, es natural importar datos a la tabla más adelante, pero al importar datos, es diferente de las bases de datos tradicionales: Hive no admite declaraciones de inserción una por una, ni admite operaciones de actualización. Los datos de la tabla de Hive se cargan en la tabla creada a modo de carga. Una vez que se importan los datos, no se pueden modificar. Elimine la tabla completa o cree una tabla nueva e importe datos nuevos. El formato gramatical de

los datos importados es: Preste atención a los siguientes puntos al importar datos:
- inpath local significa importar datos del linux local a la tabla de Hive, e inpath significa importar datos de HDFS a la tabla de Hive.
- El valor predeterminado es agregar datos a la tabla de Hive original y sobrescribir significa sobrescribir los datos originales en la tabla para su importación.
- La partición es exclusiva de la tabla de particiones y debe agregarse al importar datos; de lo contrario, se informará un error.
- La operación de carga es solo una simple operación de copiar / mover, copiar / mover el archivo de datos a la posición correspondiente de la tabla de Hive, es decir, Hive no realizará ningún cambio en los datos en sí durante el proceso de carga de datos, solo copiará o mueva el contenido de datos a la ubicación correspondiente. En la tabla.
Tres, función de colmena
3.1 Funciones integradas del sistema:
- Ver las funciones que vienen con el sistema
hive> show functions;
- Mostrar el uso de funciones integradas
desc function upper;
- Muestre el uso de las funciones integradas en detalle
desc function extended upper;
3.2 Funciones de uso común integradas en el sistema:
- Función matemática
① redondeo Función de redondeo.
② función de redondeo de techo.
③ sqrt Calcula la función raíz cuadrada.
④ abs Calcula la función de valor absoluto.
⑤ mayor Encuentra el valor máximo en un grupo de datos.
⑥ mínimo Encuentra el valor mínimo de un conjunto de datos.
⑦ cast convierte el tipo de datos y devuelve el resultado correctamente; de lo contrario, devuelve Null. - Función de cadena
① función de recorte para eliminar espacios.
② ltrim a la izquierda de la función de espacio
③ rtrim a la derecha de la función de espacio.
④ concat_ws (separador, cadena1, cadena2, ...) El primer parámetro de concat_ws es el separador de otros parámetros. La posición del separador se coloca entre las dos cadenas a conectar. El separador puede ser una cadena u Otros parámetros.
3.3 función personalizada
- Hive viene con algunas funciones, como máximo / mínimo, etc., pero el número es limitado y puede ampliarlo fácilmente a través de UDF personalizado.
- Cuando las funciones integradas proporcionadas por Hive no pueden satisfacer sus necesidades de procesamiento comercial, puede considerar el uso de funciones definidas por el usuario (UDF: funciones definidas por el usuario) en este momento.
- Según la categoría de función definida por el usuario, se divide en los tres tipos siguientes:
① UDF (función definida por el usuario) una entrada y una salida.
② Función agregada UDAF (función de agregación definida por el usuario), más entrada y salida,
similar a: count / max / min.
③ UDTF (funciones generadoras de tablas definidas por el usuario) tiene una entrada y varias salidas, como la vista lateral explore (). - Dirección del documento oficial
https://cwiki.apache.org/confluence/display/Hive/HivePlugins - Pasos de programación:
① Heredar org.apache.hadoop.hive.ql.UDF
② La función de evaluación debe implementarse; la función de evaluación admite la sobrecarga;
③ Crear una función en la ventana de línea de comandos de hive
a) Agregar jar
add jar linux_jar_path
b) Crear función
create [temporary] function [dbname.]function_name AS class_name;
④ Eliminar la función en la ventana de línea de comando de Hive
drop [temporary] function [if exists] [dbname.]function_name;
- Nota
① UDF debe tener un tipo de retorno, que puede devolver nulo, pero el tipo de retorno no puede ser nulo;
3.4 Función UDF personalizada
- Crear una colmena de proyectos de Maven
- Importar dependencias
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
- Crear una clase
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
- Escriba el paquete jar y cárguelo en el servidor /usr/local/testJar/udf.jar.
- Agregue el paquete jar a la ruta de clases de hive.
hive(default)> add jar /usr/local/testJar/udf.jar;
- Cree una función temporal para asociarla con la clase Java desarrollada
hive(default)>create temporary function mylower as "com.atguigu.hive.Lower";
- Puede utilizar la función personalizada mylower en hql
hive(default)> select ename, mylower(ename) lowername from emp;
3.5 Función de análisis
Función de análisis: número_de_fila () sobre () —— Requisitos del grupo TOPN
: es necesario consultar los dos datos más antiguos de cada género, los datos son los siguientes
1,18,a,male
2,19,b,male
3,22,c,female
4,16,d,female
5,30,e,male
6,26,f,female
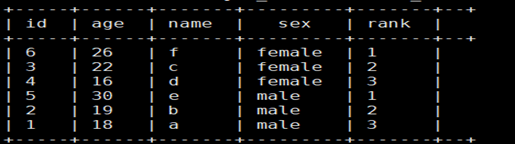
Operación real: use la función row_number para agrupar los datos en la tabla según el género, ordenar y marcar en orden inverso de edad
select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber;
Resultado:
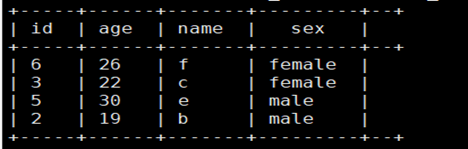
Posteriormente, utilizando los resultados anteriores, el requisito final es la consulta con rango <= 2:
select id,age,name,sex
from
(select id,age,name,sex,
row_number() over(partition by sex order by age desc) as rank
from t_rownumber) tmp
where rank<=2;
resultado:
3.6 Función de conversión
Función: explotar (). Los datos son los siguientes
1,zhangsan,化学:物理:数学:语文
2,lisi,化学:数学:生物:生理:卫生
3,wangwu,化学:语文:英语:体育:生物
1. Asignación a una tabla
create table t_stu_subject(id int,name string,subjects array<string>)
row format delimited fields terminated by ','
collection items terminated by ':';
2. Importar datos
load data local inpath '/usr/local/testJar/subject.txt' overwrite into table t_stu_subject;

3
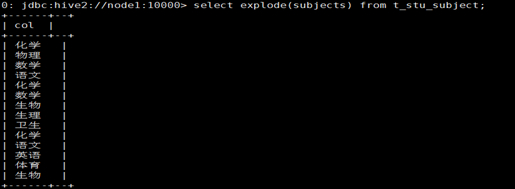
Después de " explotar " el campo de matriz con explotar () , use el resultado de esta explosión para encontrar una lección para la deduplicación:
select distinct tmp.sub
from
(select explode(subjects) as sub from t_stu_subject) tmp;
resultado:

Cuatro, caso completo
4.1 Use HQL para hacer estadísticas
Necesita usar colmena como recuento de palabras, existe el siguiente archivo de texto word.txt,
hello tom hello jim
hello rose hello tom
tom love rose rose love jim
jim love tom love is what
what is love
1. Crea una tabla
create table t_wc(sentence string);
2. Importar datos
load data local inpath '/usr/local/testJar/word.txt' overwrite into table t_wc;
3. Consulta de declaración
SELECT word
,count(1) as cnts
FROM (
SELECT explode(split(sentence, ' ')) AS word
FROM t_wc
) tmp
GROUP BY word
order by cnts desc;
Visualización de resultados

para resumir
Escribí este blog porque estaba trabajando en un proyecto de almacén de datos recientemente y expliqué Hive claramente. Espero que sea útil para todos.