Introducción
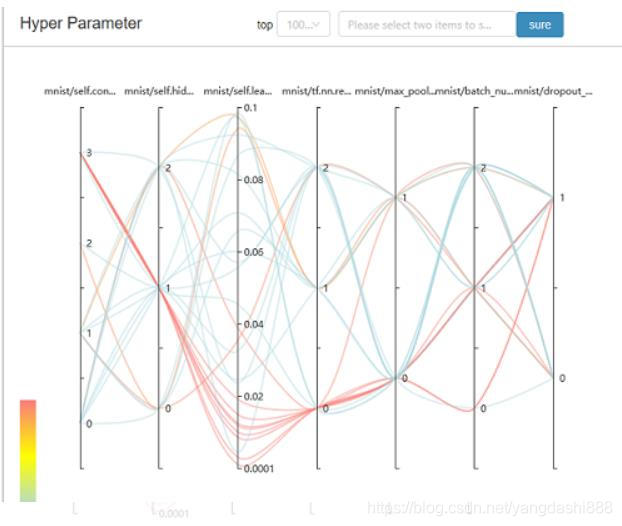
NNI es la herramienta de ajuste automático de código abierto de Microsoft. Es demasiado complicado ajustar los parámetros manualmente. Lo probé recientemente y se siente bien. Puede ayudarlo a ajustar los parámetros mientras hacen el trabajo de visualización juntos, lo cual es simple y claro. Puede ver el progreso del experimento actual, los parámetros de búsqueda y algunas de las mejores combinaciones de hiperparámetros. Por ejemplo: a
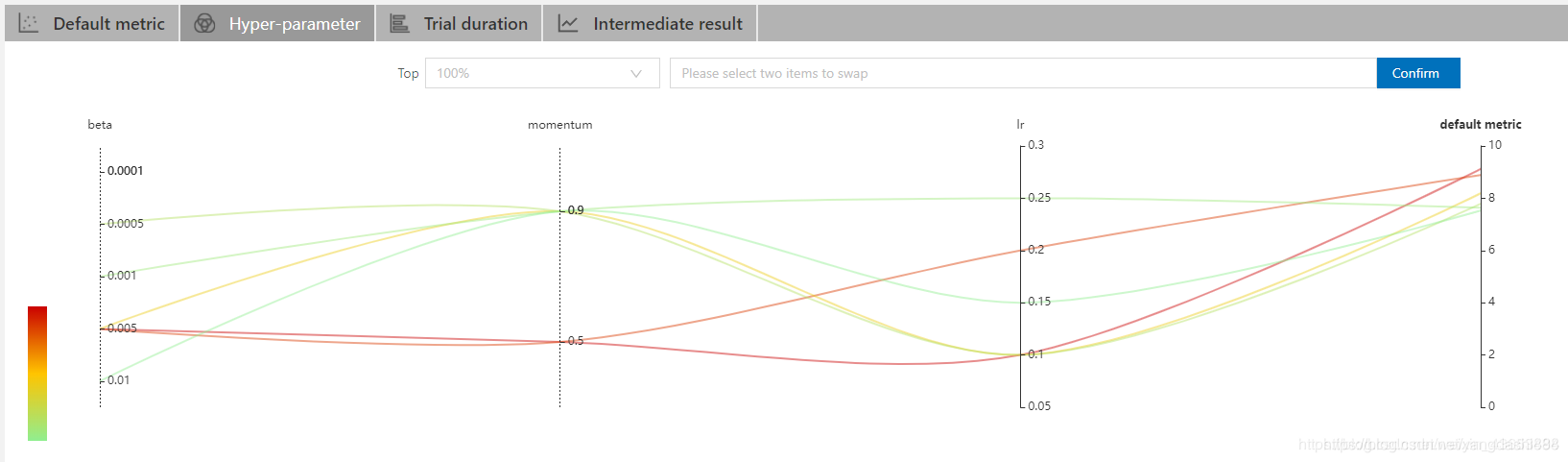
través del mapa de colores a continuación, puede ver intuitivamente la rica información expresada por las líneas rojas (es decir, la combinación de hiperparámetros de alta precisión). Tal como
- Un núcleo de convolución más grande funcionará mejor.
- Una capa grande completamente conectada no es necesariamente buena. Quizás el tiempo de entrenamiento requerido haya aumentado y la velocidad de entrenamiento sea demasiado lenta.
- La tasa de aprendizaje es menor (menos de 0.03) y el rendimiento es básicamente bueno.
- ReLU también es mucho mejor que otras funciones de activación como tanh.
- …
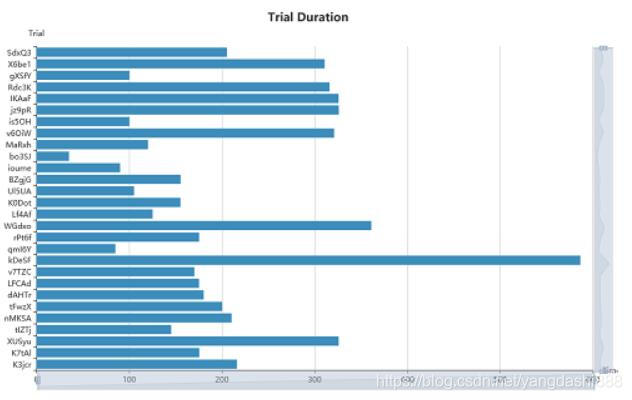
A través de la página de estado de la prueba, puede ver la duración de cada prueba y la combinación específica de hiperparámetros.
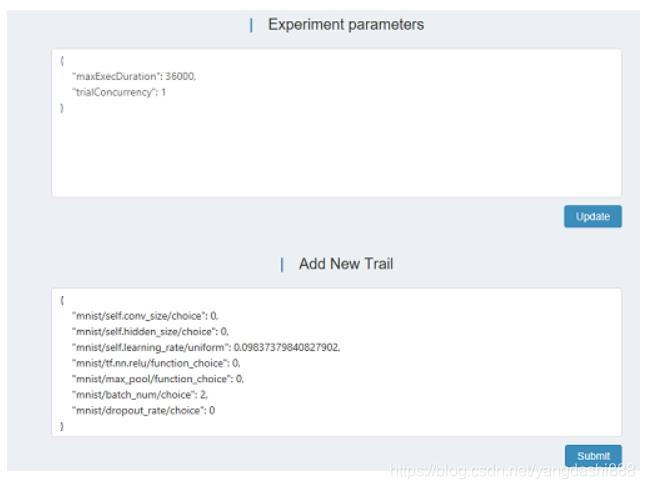
A través de la página de control, la combinación de superparámetros de la prueba se puede agregar en tiempo real, o se puede ajustar el rango del superparámetro.
Este artículo se divide en las dos partes siguientes:
- Cómo instalar y usar NNI
- Experiencia de depuración y resumen de errores
El primer paso: instalación
La instalación de nni es muy sencilla. Puede instalarlo mediante el comando pip. Y proporciona un ejemplo de referencia y aprendizaje.
Requisito previo: tensorflow, python> = 3.5,
# 安装nni
python3 -m pip install --upgrade nni
# 示例程序,用于学习
git clone https://github.com/Microsoft/nni.git
# 如果想运行这个示例程序,需要安装tensorflow
python3 -m pip install tensorflow
Paso 2: establece el rango de búsqueda de hiperparámetros
Primero, echemos un vistazo al programa de muestra de NNI
cd ./nni/examples/trials/mnist/
Puede ver que hay tres archivos en el directorio: config.yml, mnist.py y search_space.json. Estos tres archivos determinan nuestro archivo de configuración NNI, main.py y el espacio de búsqueda de hiperparámetros respectivamente.
1. Abra el archivo search_space.json.
{
"dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]},
"conv_size":{"_type":"choice","_value":[2,3,5,7]},
"hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
"batch_size": {"_type":"choice", "_value": [1, 4, 8, 16, 32]},
"learning_rate":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]}
}
Aquí puede definir nuestros hiperparámetros y rango de búsqueda, que se pueden ajustar a su antojo según sus necesidades.
Hay muchos tipos de búsqueda, los más utilizados son uniformes, de elección, etc.
Pero debido a que este ejemplo solo describe el uso de uniforme y elección, muchos otros blogs solo introducen el uso de elección y uniforme, por lo que los agregaré aquí. Para obtener más información, consulte el documento de ayuda de github de NNI
{"_type": "choice", "_value": options}
# dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]}的结果为0.5或者0.9
{"_type": "uniform", "_value": [low, high]}
# 变量是 low 和 high 之间均匀分布的值。
# 当优化时,此变量值会在两侧区间内。
{"_type": "quniform", "_value": [low, high, q]}
# 从low开始到high结束,步长为q。
# 比如{"_type": "quniform", "_value": [0, 10, 2]}的结果为0,2,4,6,8,10
{"_type": "normal", "_value": [mu, sigma]}
# 变量值为实数,且为正态分布,均值为 mu,标准方差为 sigma。 优化时,此变量不受约束。
{"_type": "randint", "_value": [lower, upper]}
# 从 lower (包含) 到 upper (不包含) 中选择一个随机整数。
Paso 2: Configure config.yaml y
abra config.yaml
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
Además de command, maxExecDuration, trialConcurrency, gpuNum, Optimize_mode deben cambiarse, los parámetros aquí generalmente no necesitan cambiarse.
El comando es el comando que se ejecutará después de que se ejecute nni.Cambie mnist.py a su main.py o train.py y otros programas principales.
maxExecDuration es el tiempo para que todo el NNI ajuste automáticamente los parámetros. Tenga en cuenta que no es el tiempo de un entrenamiento (lo entendí como el tiempo máximo requerido para un entrenamiento desde el principio). Si corre con una GPU, tiene para entrenar 10 parámetros diferentes, cada vez que el entrenamiento tarda 2 horas, este valor se establece en 20 h
trialConcurrency es la cantidad de rutas simultáneas, esto debe establecerse de acuerdo con la cantidad de GPU, no el gpuNum a continuación. ! ! Porque una ruta representa un proceso de ajuste de parámetros. Se entiende como ejecutar tu train.py con una especie de hiperparámetro y establecer el número de concurrencia en x, ¡así que hay x entrenadores en entrenamiento!
gpuNum es la cantidad de GPU requeridas por cada ruta, no la cantidad de GPU requeridas para todo el ajuste nni. Para tareas grandes, si se requieren N GPU para un solo entrenamiento, este valor se establece en N; si un solo entrenamiento es suficiente, una GPU es suficiente, establezca este valor en 1; ¿sin GPU? Quiero escribir una palabra miserable ...
Entonces, la cantidad total de GPU que necesita al final es trialConcurrency gpuNum, que es la cantidad de pistas y la cantidad de GPU necesarias para cada ruta.
Optimize_mode corresponde a la dirección de optimización. Hay dos formas de máximo y mínimo. Cómo configurarlo se menciona en el siguiente paso.
En general, la configuración aquí es suficiente.
Si necesita ajustar el algoritmo de búsqueda de cuadrícula y otras cosas más detalladas, consulte el documento de ayuda de github de NNI
El tercer paso es modificar nuestro código
# 引入nni
import nni
"""
设置参数自动更新,假设params 是我们的默认参数
注意params是**字典**类型的变量
"""
params = vars(get_params())
tuner_params= nni.get_next_parameter() # 这会获得一组搜索空间中的参数
params.update(tuner_params)
"""
向nni报告我们的结果
如果test_acc是准确率,那第二步(5)optimize_mode就选maximize。如果这里的test_acc如果是loss,
那第二步(5)optimize_mode就选minimize,也可以填其他训练的指标
另外这里的报告结果都是数字,一般选择float类型
"""
nni.report_intermediate_result(test_acc)
'''
report_intermediate_result是汇报中间结果,一般可以设置每个epoch报告一次
'''
nni.report_final_result(best_acc)
'''
report_final_result是汇报最终结果,可以是last_acc,也可以设置为报告best_acc
'''
Muchos experimentadores dicen que report_intermediate_result reporta pérdidas y report_final_result reporta precisión. Esta afirmación es incorrecta.
El contenido de estos dos informes debe tener el mismo significado (ambos son pérdida o precisión u otro), las
razones se discutirán a continuación
El cuarto paso es ejecutar las dos líneas de código directamente
cd ./YourCode_dir
nnictl create --config config.yml -p 8888
Cambie al directorio de código y ejecútelo directamente.
-p representa el número de puerto utilizado. Tenga en cuenta que si el código utiliza el entorno virtual conda, debe activar el entorno virtual conda.
El quinto paso es ver el proceso de formación.
Creo que debería ver la palabra "éxito" en este momento. No se emocione. Esto no significa que haya comenzado con éxito a sintonizar. De todos modos, no sé cuántas veces tuvo éxito.
Abra el sitio web proporcionado por la línea de comando, como se muestra a continuación, y haga clic en Trail Detial-> Intermediate result.
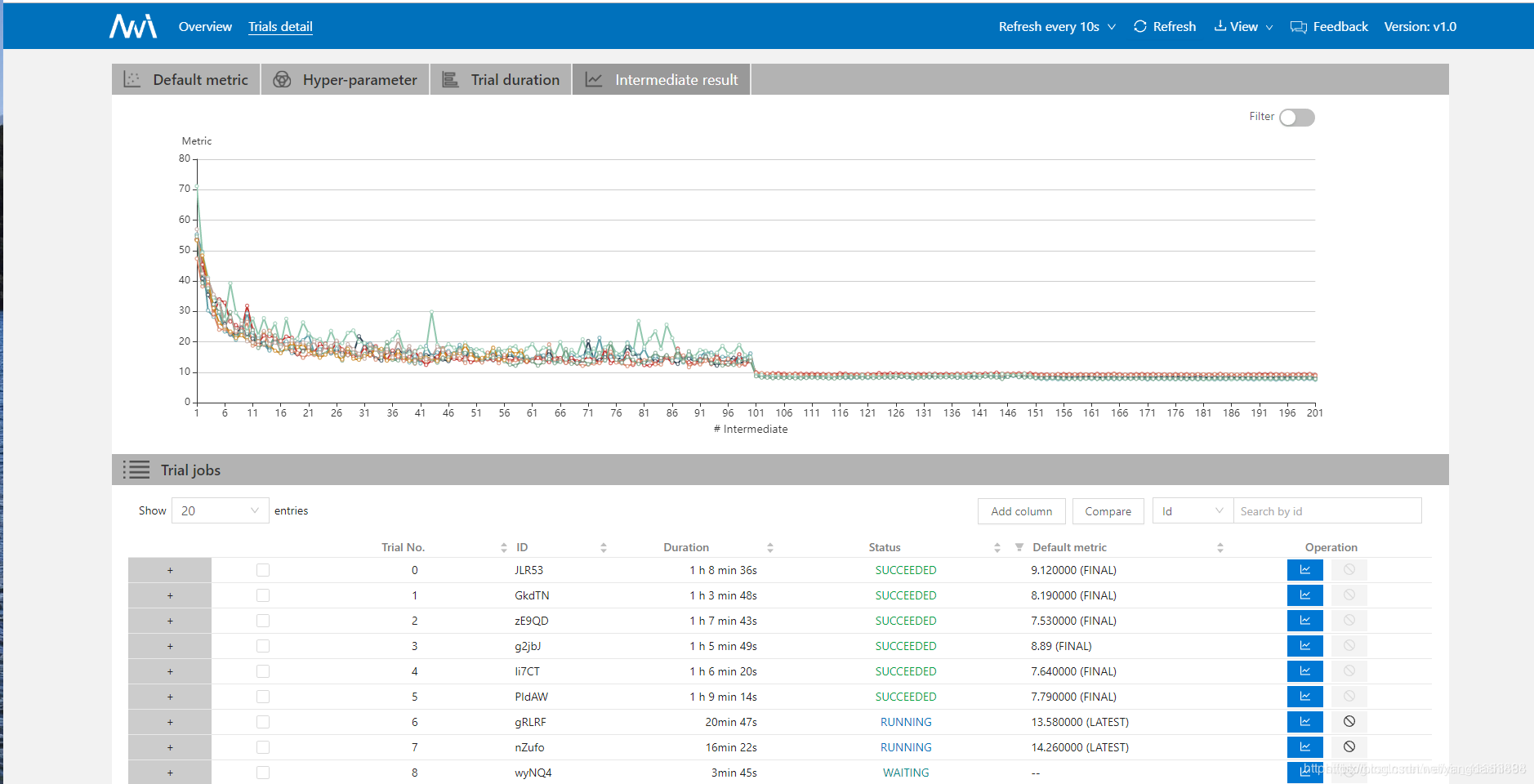
Si lo abre demasiado rápido, debería estar en estado WATING. No se preocupe, la EJECUCIÓN comenzará después de un tiempo. Si falla directamente, verifique su código.
Si report_intermediate_result es un informe para cada época, luego de ejecutar una época, verá la métrica predeterminada, seguida de un paréntesis (ÚLTIMO). En este momento, el trabajo está básicamente terminado. ¡Felicitaciones!
Si report_final_result es el informe al final del entrenamiento, habrá un valor de Métrica predeterminada (FINAL) después de que termine el entrenamiento.
Esto muestra que report_intermediate_result y report_final_result son en realidad una métrica predeterminada, que es una medida significativa, y ambas se utilizan para medir la calidad del modelo.
La siguiente figura es una curva de hiperparámetro. De hecho, se puede ver en la figura de arriba que acabo de comenzar a sintonizar y solo unos pocos rastros son EXITOSOS. ¡Pero quiero decir eso bajo estas condiciones! ! ¡Esta curva es demasiado hermosa! ! !
Paso 6 parada
Cuando no desee continuar buscando hiperparámetros, puede usar nnictl stop para detener el ajuste automático de parámetros.
Pero esto solo significa que la siguiente ruta no comenzará y la ruta que no ha terminado de correr continuará ejecutándose. Si desea terminar el rastro, puede usar nvidia-smi para encontrar el PID del proceso de entrenamiento y luego usar kill -9 PID para matar el proceso