Varias cosas que a menudo pasamos por alto al implementar aplicaciones en Kubernetes
Charla de operación y mantenimiento para principiantes de Scofield
En mi experiencia, la mayoría de las personas (que usan Helm o yaml manual) implementan aplicaciones en Kubernetes y luego piensan que siempre pueden ejecutarse de manera estable.
Sin embargo, este no es el caso. El proceso de uso real todavía encontró algunas "trampas". Espero enumerar estas "trampas" aquí para ayudarlo a comprender algunos problemas a los que debe prestar atención antes de iniciar una aplicación en Kubernetes.
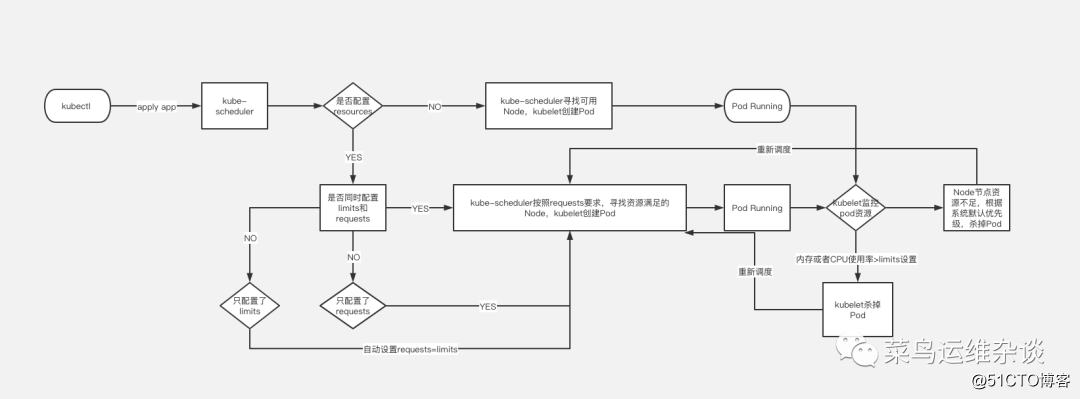
Introducción a la programación de Kubernetes
El programador utiliza el mecanismo de observación de kubernetes para descubrir los pods recién creados en el clúster que aún no se han programado en Node. El programador programará cada Pod no programado encontrado en un Nodo apropiado para que se ejecute. Como programador predeterminado del clúster, kube-Scheduler seleccionará un Nodo óptimo para ejecutar el Pod para cada Pod recién creado o Pod no programado. Sin embargo, cada contenedor en el Pod tiene diferentes requisitos de recursos, y el Pod en sí también tiene diferentes requisitos de recursos. Por lo tanto, antes de programar el pod en el nodo, es necesario filtrar los nodos del clúster de acuerdo con estos requisitos específicos de programación de recursos.
En un clúster, todos los nodos que satisfacen una solicitud de programación de Pod se denominan nodos programables. Si ningún nodo puede satisfacer la solicitud de recursos del pod, el pod permanecerá en el estado no programado hasta que el programador pueda encontrar un nodo adecuado.
Los factores que deben tenerse en cuenta al tomar decisiones de programación incluyen: solicitudes de recursos individuales y generales, restricciones de hardware / software / políticas, requisitos de afinidad y antiafinidad, ubicación de los datos, interferencia entre cargas, etc. Consulte el sitio web oficial para obtener más información sobre la programación.
Solicitudes y límites de pod
Veamos un ejemplo simple, aquí solo intercepta parte de la información de yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
resources:
limits:
memory: "100Mi"
cpu: 100m
requests:
memory: "1000Mi"
cpu: 100mDe forma predeterminada, creamos un archivo de implementación de servicios. Si no escribe el campo de recursos, el clúster de Kubernetes usará la política predeterminada y no impondrá restricciones de recursos en el Pod, lo que significa que el Pod puede usar los recursos de memoria y CPU del nodo Nodo a voluntad. Pero esto causará un problema: la contención de recursos.
Por ejemplo: un nodo Node tiene memoria 8G y hay dos Pods ejecutándose en él.
Al comienzo de la operación, ambos Pods solo necesitan memoria 2G para ejecutarse. No hay ningún problema en este momento, pero si uno de los Pods aumenta repentinamente a 7G debido a una fuga de memoria o el proceso aumenta repentinamente, la memoria 8G del Nodo es obviamente no es suficiente en este momento. Esto resultará en servicios extremadamente lentos o no disponibles.
Por lo tanto, en circunstancias normales, cuando implementamos servicios, debemos limitar los recursos del pod para evitar problemas similares.
Como se muestra en el archivo de muestra, es necesario agregar recursos;
requests: 表示运行服务所需要的最少资源,本例为需要内存100Mi,CPU 100m
limits: 表示服务能使用的最大资源,本例最大资源限制在内存1000Mi,CPU 100m¿Qué significa eso? Una imagen vale mas que mil palabras.
PD: @@@ 画图 Realmente hice mi mejor esfuerzo @@@
Sondas de vitalidad y preparación
Otro tema candente que a menudo se discute en la comunidad de Kubernetes. Dominar las sondas de disponibilidad y disponibilidad es muy importante porque proporcionan un mecanismo para ejecutar software tolerante a fallas y minimizar el tiempo de inactividad. Sin embargo, si la configuración no es correcta, pueden tener un impacto grave en el rendimiento de su aplicación. Aquí hay un resumen de estas dos sondas y cómo razonar sobre ellas:
Liveness Probe: detecta si el contenedor se está ejecutando. Si la sonda de actividad falla, el kubelet matará al contenedor y el contenedor aceptará su estrategia de reinicio. Si el "contenedor" no proporciona una sonda de actividad, el estado predeterminado es "éxito".
Debido a que la sonda Liveness se ejecuta con más frecuencia, la configuración es lo más simple posible. Por ejemplo, si la configura para que se ejecute una vez por segundo, se agregará una solicitud adicional por segundo, por lo que debe considerar los recursos adicionales necesarios para esto petición. Por lo general, proporcionamos una interfaz de verificación de estado para Liveness, que devuelve un código de respuesta de 200 para indicar que su proceso ha comenzado y puede manejar solicitudes.
Sondeo de preparación: detecta si el contenedor está listo para procesar la solicitud. Si la sonda preparada falla, el punto final eliminará la dirección IP del pod de los puntos finales de todos los servicios que coincidan con el pod.
Los requisitos de inspección de la sonda de preparación son relativamente altos, ya que indica que toda la aplicación se está ejecutando y está lista para recibir solicitudes. Para algunas aplicaciones, la solicitud solo se aceptará después de que el registro se devuelva de la base de datos. Mediante el uso de sondas de preparación bien pensadas, podemos lograr niveles más altos de disponibilidad y una implementación sin tiempo de inactividad.
Los métodos de detección de las sondas de vivacidad y preparación son los mismos, hay tres
- Defina el comando de supervivencia:
si el comando se ejecuta con éxito y el valor de retorno es cero, Kubernetes considera que esta detección es exitosa; si el valor de retorno del comando es distinto de cero, esta detección de Liveness falla. - Defina una interfaz de solicitud HTTP en vivo;
envíe una solicitud HTTP y devuelva cualquier código de retorno mayor o igual a 200 y menor que 400 para indicar éxito, y otros códigos de retorno indican falla. - Defina la detección de supervivencia de TCP
para enviar una solicitud tcpSocket al puerto de ejecución, si se puede conectar, significa éxito, de lo contrario falla.
Veamos un ejemplo, aquí está la detección de supervivencia de TCP común como ejemplo
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10livenessProbe 部分定义如何执行 Liveness 探测:
1. 探测的方法是:通过tcpSocket连接nginx的80端口。如果执行成功,返回值为零,Kubernetes 则认为本次 Liveness 探测成功;如果命令返回值非零,本次 Liveness 探测失败。
2. initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 探测,一般会根据应用启动的准备时间来设置。比如应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
3. periodSeconds: 10 指定每 10 秒执行一次 Liveness 探测。Kubernetes 如果连续执行 3 次 Liveness 探测均失败,则会杀掉并重启容器。
readinessProbe 探测一样,但是 readiness 的 READY 状态会经历了如下变化:
1. 刚被创建时,READY 状态为不可用。
2. 20 秒后(initialDelaySeconds + periodSeconds),第一次进行 Readiness 探测并成功返回,设置 READY 为可用。
3. 如果Kubernetes连续 3 次 Readiness 探测均失败后,READY 被设置为不可用。Establecer la política de red predeterminada para Pod
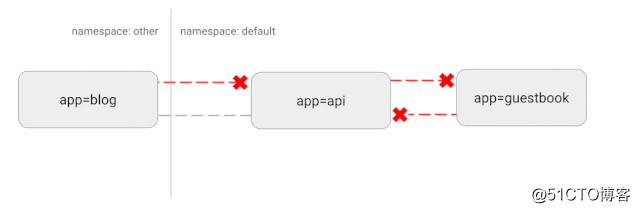
Kubernetes usa una topología de red "plana". De forma predeterminada, todos los pods pueden comunicarse directamente entre sí. Pero en algunos casos no queremos esto, o incluso innecesario. Habrá algunos riesgos de seguridad potenciales. Por ejemplo, si se utiliza una aplicación vulnerable, puede proporcionar al pirata informático acceso completo para enviar tráfico a todos los pods de la red. Como en muchas áreas de seguridad, la política de acceso mínimo también se aplica a esto. Idealmente, se creará una política de red para especificar claramente qué conexiones de contenedor a contenedor están permitidas.
Por ejemplo, la siguiente es una estrategia simple que denegará todo el tráfico de entrada en un espacio de nombres específico
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-ingress-flow
spec:
podSelector: {}
policyTypes:
- IngressDiagrama esquemático de esta configuración
Comportamiento personalizado a través de Hooks y contenedores init
Uno de nuestros principales objetivos al utilizar el sistema Kubernetes es intentar proporcionar a los desarrolladores estándar una implementación con el menor tiempo de inactividad posible. Esto es difícil debido a las diversas formas en que una aplicación se apaga y limpia los recursos usados. Una aplicación que nos resultó particularmente difícil fue Nginx. Notamos que cuando comenzamos la implementación continua de estos pods, las conexiones activas se interrumpieron antes de que se terminaran con éxito. Después de una extensa investigación en línea, resulta que Kubernetes no está esperando a que Nginx agote sus conexiones antes de terminar el Pod. Utilizando el gancho de parada previa, pudimos inyectar esta función y logramos un tiempo de inactividad cero con este cambio.
Normalmente, por ejemplo, queremos realizar una actualización progresiva a Nginx, pero Kubernetes no espera a que Nginx termine la conexión antes de detener el Pod. Esto hará que el nginx detenido no cierre correctamente todas las conexiones, lo cual no es razonable. Por lo tanto, necesitamos usar ganchos antes de detenernos para resolver este tipo de problemas.
Podemos agregar ciclo de vida al archivo de implementación
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
nginx-killer.sh
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
doneDe esta manera, Kubernetes ejecutará el script nginx-killer.sh antes de cerrar el Pod para cerrar nginx en la forma que definimos
Otra situación es usar el contenedor init.
Init Container es el contenedor utilizado para la inicialización. Puede ser uno o más. Si hay más de uno, estos contenedores se ejecutarán en un orden definido. Solo después de que se hayan ejecutado todos los Init Containers. , Se iniciará el contenedor principal.
Por ejemplo:
initContainers:
- name: init
image: busybox
command: ["chmod","777","-R","/var/www/html"]
imagePullPolicy: Always
volumeMounts:
- name: volume
mountPath: /var/www/html
containers:
- name: nginx-demo
image: nginx
ports:
- containerPort: 80
name: port
volumeMounts:
- name: volume
mountPath: /var/www/htmlMontamos un disco de datos en / var / www / html de nginx. Antes de que se ejecutara el contenedor principal, cambiamos el permiso de / var / www / html a 777 para que no hubiera problemas de permisos cuando se usaba el contenedor principal.
Por supuesto, esto es solo un poco de castaña. Init Container tiene funciones más poderosas, como la configuración inicial. . .
Kernel Tuning (optimización de parámetros del kernel)
Finalmente, dejando las tecnologías más avanzadas para el final, jaja
Kubernetes es una plataforma muy flexible diseñada para permitirle ejecutar servicios de la manera que mejor le parezca. Por lo general, si tenemos servicios de alto rendimiento y tenemos requisitos de recursos estrictos, como redis comunes, se mostrarán las siguientes indicaciones después del inicio
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.Esto requiere que modifiquemos los parámetros del kernel del sistema. Afortunadamente, Kubernetes nos permite ejecutar un contenedor privilegiado que puede modificar los parámetros del kernel que solo son aplicables a Pods específicos en ejecución. El siguiente es un ejemplo que usamos para modificar el parámetro / proc / sys / net / core / somaxconn.
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "echo 511 > /proc/sys/net/core/somaxconn"]para resumir
Aunque Kubernetes proporciona una solución lista para usar, también requiere que tome algunos pasos clave para garantizar el funcionamiento estable del programa. Antes de que el programa entre en funcionamiento, asegúrese de realizar varias pruebas, observar los indicadores clave y realizar ajustes en tiempo real.
Antes de implementar el servicio en el clúster de Kubernetes, podemos hacernos algunas preguntas:
- ¿Cuántos recursos necesita nuestro programa, como memoria, CPU, etc.?
- ¿Cuál es el tráfico promedio del servicio y cuál es el tráfico pico?
- ¿Cuánto tiempo queremos que se expanda el servicio y cuánto tardarán los nuevos pods en aceptar tráfico?
- ¿Nuestro Pod se detiene normalmente? ¿Cómo hacerlo sin afectar los servicios en línea?
- ¿Cómo podemos asegurarnos de que los problemas con nuestros servicios no afectarán a otros servicios y no causarán un tiempo de inactividad del servicio a gran escala?
- ¿Es nuestra autoridad demasiado grande? ¿es seguro?
Finalmente terminado, woo woo woo~ Es tan dificil~
Imagen
PD: los artículos de seguimiento se sincronizarán con dev.kubeops.net
Nota: Las imágenes del artículo son de Internet. Si hay alguna infracción, comuníquese conmigo para eliminarla a tiempo.