Escalado automático horizontal de pod de Kubernetes (HPA)
Charla de operación y mantenimiento para principiantes de Scofield
Introducción a HPA
HAP, el nombre completo de Horizontal Pod Autoscaler, puede escalar automáticamente la cantidad de Pods en ReplicationController, Deployment y ReplicaSet según la utilización de la CPU. Además de la utilización de la CPU, el escalado automático también se puede realizar en función de métricas personalizadas proporcionadas por otras aplicaciones. El escalado automático de pod no se aplica a los objetos que no se pueden escalar, como DaemonSet.
Los controladores y recursos de la API de Kubernetes implementan la función de escalado automático horizontal del pod. El recurso determina el comportamiento del controlador. El controlador ajusta periódicamente la cantidad de réplicas en el controlador de réplica o implementación para que el uso promedio de CPU del Pod coincida con el valor objetivo establecido por el usuario.
Diagrama esquemático del mecanismo de trabajo de Pod HAP
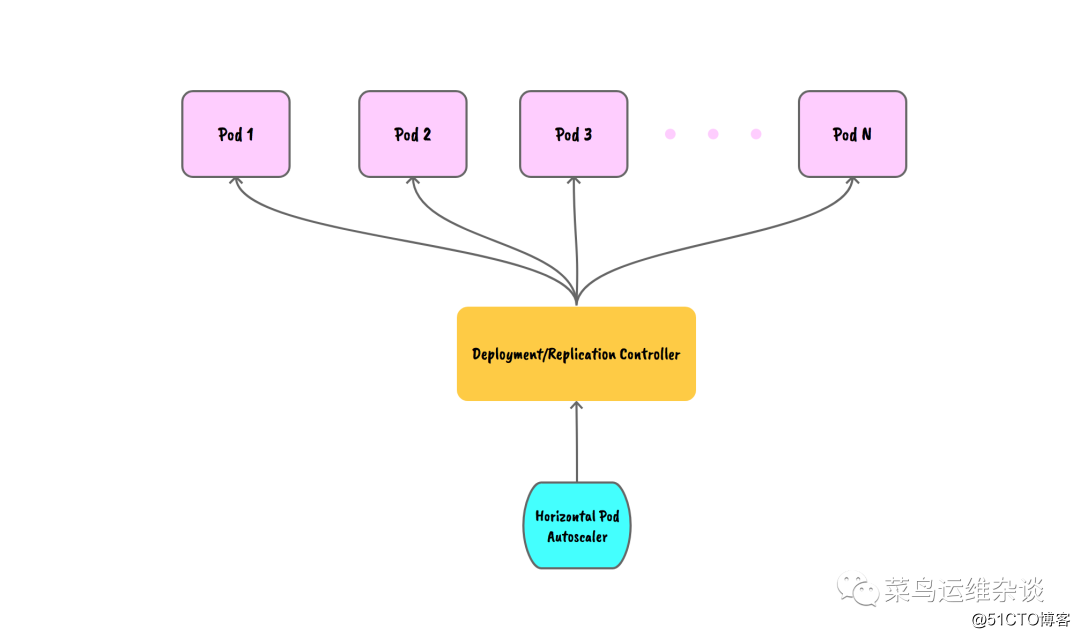
En la producción real, estos cuatro tipos de indicadores se utilizan ampliamente:
1. Métricas de recursos: indicadores de utilización de la memoria del núcleo de la CPU.
2. Métricas de pod, como la utilización de la red y el tráfico.
3. Métricas de objetos: métricas para objetos específicos, como Ingress. Los contenedores se pueden expandir según la cantidad de solicitudes por segundo.
4. Métricas personalizadas: monitoreo personalizado, como la definición del tiempo de respuesta del servicio, y se expande automáticamente cuando el tiempo de respuesta alcanza un cierto índice.
Bien, hablemos del concepto. Si quieres saber más, consulta el sitio web oficial y comienza el combate real ahora.
Ejemplo
1. Primero, implementamos un nginx, el número de copias es 2 y el recurso de CPU solicitado es 200 m. Al mismo tiempo, para realizar pruebas económicas, utilice NodePort para exponer los servicios. Espacio de nombres: hpa
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx
namespace: hpa
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 200m
memory: 100Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: hpa
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx2. Ver los resultados de la implementación
[root@k8s-node001 HPA]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
nginx-5c87768685-48b4v 1/1 Running 0 8m38s
nginx-5c87768685-kfpkq 1/1 Running 0 8m38s3. Cree HPA
brevemente: aquí, cree un HPA para controlar la implementación que creamos en el paso anterior, de modo que la cantidad de copias de pod se mantenga entre 1 y 10.
HPA aumentará o disminuirá la cantidad de copias de pods (a través de la implementación) para mantener el uso promedio de CPU de todos los pods dentro del 50%.
Ver algoritmo
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx
namespace: hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 504. Ver los resultados de la implementación
[root@k8s-node001 HPA]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/50% 1 10 2 50s5. Prueba de presión, observe el número de vaina y el cambio de HPA y
ejecute el comando de prueba de presión
[root@k8s-node001 ~]# ab -c 1000 -n 100000000 http://192.168.100.185:30792/
This is ApacheBench, Version 2.3 <$Revision: 1843412 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.100.185 (be patient)Observar cambios
[root@k8s-node001 HPA]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 303%/50% 1 10 7 12m
[root@k8s-node001 HPA]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
pod/nginx-5c87768685-6b4sl 1/1 Running 0 85s
pod/nginx-5c87768685-99mjb 1/1 Running 0 69s
pod/nginx-5c87768685-cls7r 1/1 Running 0 85s
pod/nginx-5c87768685-hhdr7 1/1 Running 0 69s
pod/nginx-5c87768685-jj744 1/1 Running 0 85s
pod/nginx-5c87768685-kfpkq 1/1 Running 0 27m
pod/nginx-5c87768685-xb94x 1/1 Running 0 69sPuede verse en el resultado anterior que hpa TARGETS ha alcanzado el 303% y debe ampliarse. La cantidad de pods se expande automáticamente a 7.
Continúe esperando el final de la prueba de presión o interrumpa la prueba de presión directamente
[root@k8s-node001 ~]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 20%/50% 1 10 7 16m
。。。N分钟后。。。
[root@k8s-node001 ~]# kubectl get hpa -n hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx Deployment/nginx 0%/50% 1 10 7 18m
。。。再过N分钟后。。。
[root@k8s-node001 ~]# kubectl get po -n hpa
NAME READY STATUS RESTARTS AGE
nginx-5c87768685-jj744 1/1 Running 0 11mEn este momento, la utilización de la CPU se redujo a 0, por lo que HPA reducirá automáticamente el número de copias a 1.
Aquí debemos prestar atención: ¿Por qué la cantidad de réplicas se reduciría a 1, en lugar de las réplicas: 2 especificadas durante la implementación?
Porque cuando se creó HPA, se especificó el rango de número de réplicas, aquí está minReplicas: 1, maxReplicas: 10. Entonces HPA se redujo a 1 al reducir el número de copias.
Sugerencias: la escala automática puede tardar varios minutos en completar el cambio del número de copias.
para resumir

PD: los artículos de seguimiento se sincronizarán con dev.kubeops.net
Nota: Las imágenes del artículo son de Internet. Si hay alguna infracción, comuníquese conmigo para eliminarla a tiempo.