Conceptos básicos de gráficos
Un gráfico se puede considerar como un conjunto que consta de puntos y bordes. El conjunto de puntos no debe estar vacío, pero el conjunto de bordes no es necesariamente no vacío. El número de puntos está representado por el orden del gráfico.
Algunos conceptos que no son demasiado difíciles de entender se colocan directamente debajo


. Los gráficos dirigidos y los gráficos no dirigidos son los dos vectores más comúnmente probados en el gráfico. La principal diferencia es el problema de la dirección. La diferencia se basa en si el borde está dirigido. Gráficos dirigidos y no dirigidos.

Gráfico simple y gráfico múltiple son un par de conceptos relativos. La diferencia es si hay múltiples aristas en un par de puntos. Generalmente, los gráficos múltiples no se consideran en las preguntas del examen de posgrado.

Es decir, hay un borde entre dos puntos cualesquiera en un gráfico no dirigido, y dos puntos cualesquiera en un gráfico dirigido tienen dos bordes hacia adelante y hacia atrás.


Debe ser optimista sobre el concepto de subgrafos. No solo puede tomar subconjuntos para obtener subgrafos, sino que también puede producir una estructura que no sea un gráfico simplemente tomando subconjuntos.

La conectividad es un concepto muy importante. Se puede alcanzar la conectividad. Este concepto se usa principalmente en gráficos no dirigidos. Un punto puede llegar a otro punto a través de cualquier ruta está conectada. Si todos los puntos en un gráfico están conectados, el gráfico está conectado. El subgrafo máximo conectado es el componente conectado La representación más vívida es que en el gráfico dibujado, los dos componentes conectados se pueden separar completamente en dos partes del gráfico. Además, la relación entre el número de puntos de gráficos conectados y el número de aristas que se mencionan aquí se utiliza a menudo como método para construir el gráfico desconectado más pequeño.
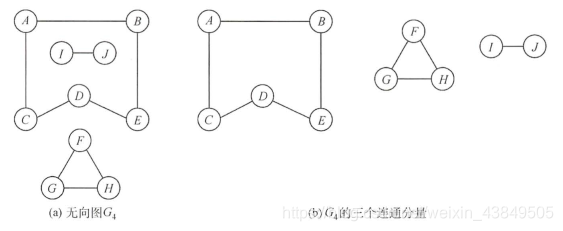

Como correspondencia de la conectividad, un grafo dirigido considera la conectividad fuerte, es decir, un punto puede ir a otro punto y luego volver al punto de partida desde este punto. Con referencia a la definición de conectividad, se pueden entender de manera similar conceptos como fuerte componentes conectados.




Cuatro métodos de almacenamiento de gráficos
Los métodos de representación principales son la matriz de adyacencia y el método de lista de adyacencia, y también hay listas reticuladas y múltiples listas adjuntas que no se utilizan con mucha frecuencia.
1. Matriz de
adyacencia La matriz de adyacencia generalmente comprende las matemáticas discretas. La posición correspondiente de un borde en un gráfico no dirigido es 1; de lo contrario, es 0. En un gráfico dirigido, qué posición es 1 se determina de acuerdo con los puntos inicial y final. la posición es 0. Si es un gráfico ponderado, también puede cambiar 1 al peso del borde.
En la práctica, generalmente se implementa con una matriz bidimensional. Dado que la matriz bidimensional está marcada por puntos, cuando hay pocos bordes en el gráfico, la mayoría de los elementos de la matriz se inicializan a 0 y la tasa de utilización es muy baja, por lo que la matriz de adyacencia se usa generalmente para almacenar gráficos densos. La complejidad espacial de la representación de la matriz de adyacencia es O (n2).
El uso de la matriz de adyacencia tiene las siguientes características: En

segundo lugar, el método de lista de adyacencia es
como una matriz y una lista vinculada. El método de lista de adyacencia tiene la ventaja de ser flexible y asigna espacio de acuerdo con la demanda, por lo que es adecuado para almacenar gráficos dispersos.
La tabla de adyacencia se compone de dos partes, una tabla de vértices y una tabla de bordes. La tabla de vértices se utiliza para registrar los vértices. La tabla de bordes está conectada detrás del vértice para indicar el borde de este punto. El nodo de la tabla de vértice está compuesto por el campo de vértice y el puntero al primer borde adyacente El nodo de la tabla de borde está compuesto por el campo de punto adyacente y el campo de puntero al siguiente borde adyacente. Generalmente, la tabla de vértices se almacena en orden y la tabla de bordes se almacena en cadena.
Debe dibujar la lista de adyacencia de acuerdo con el significado del título. Al dibujar la lista de adyacencia, debe prestar atención a la conexión directa de los vértices y la conexión entre los bordes. Solo recuerda un ejemplo.
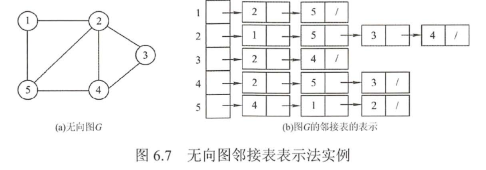
Además, me gusta usar el almacenamiento de la tabla de adyacencia en las preguntas de código. La plantilla para el recorrido de la tabla de adyacencia es la siguiente:
for(int i=1;i<=n;i++)
{
now=head[i];
for(int j=head[i]->next;j!=NULL;j=j->next)
{
}
}
El uso de la lista de adyacencia tiene las siguientes características: En

tercer lugar, la lista reticulada La
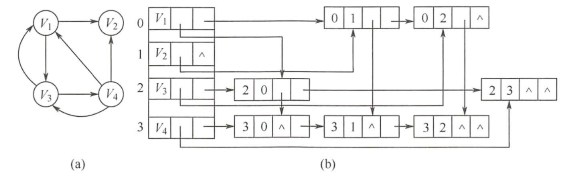
lista reticulada es una estructura de almacenamiento en cadena del gráfico dirigido . En la lista reticulada, hay un nodo correspondiente a cada arco en el gráfico dirigido, y también hay un nodo correspondiente a cada vértice. En la lista reticulada, es fácil encontrar el arco solo para la cola y el arco solo para la cabeza, por lo que es fácil encontrar la salida y en grados de los vértices. La lista de enlaces cruzados de un gráfico no es única, pero una lista de enlaces cruzados indica que un gráfico está determinado.

Para explicar brevemente, el nodo de arco se usa para registrar el borde, donde el campo de la cola y el campo de la cabeza representan los dos puntos finales y el punto de inicio de este borde, hlink apunta al siguiente borde del mismo punto de inicio y tlink puntos en la parte inferior del mismo punto final. Un borde, info se utiliza para almacenar información sobre este borde, como los pesos. Solo hay tres partes en el nodo de vértice, los datos almacenan datos, firstin apunta al primer borde comenzando desde este vértice, y firstout apunta al primer borde centrándose en este.
4. Múltiples tablas adyacentes Múltiples tablas
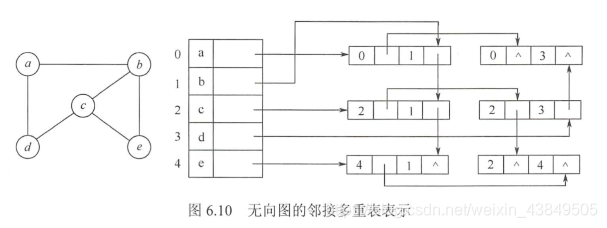
adyacentes es otra estructura de almacenamiento en cadena de gráficos no dirigidos . De manera similar a la lista reticulada, en la lista múltiple de adyacencia, cada borde está representado por un nodo.

Entre ellos, mark representa una marca, que se utiliza para distinguir si se ha experimentado este borde, ivex y jvex representan respectivamente el inicio y el final de este borde, ilink representa el siguiente borde del mismo punto de inicio, jlink representa el siguiente borde del mismo end, info Se utiliza para almacenar información relacionada, como pesos.
Cada vértice también está representado por un nodo:

solo hay dos cantidades en total, los datos de almacenamiento y el primer borde con el nodo como vértice.
En la lista múltiple de adyacencia, todos los bordes adjuntos al mismo vértice están conectados en serie en la misma lista vinculada. Dado que cada borde está adjunto a dos vértices, cada nodo de borde está vinculado en dos listas vinculadas al mismo tiempo. Para gráficos no dirigidos, la diferencia entre la tabla de adyacencia y la tabla de adyacencia es solo que el mismo borde está representado por dos nodos en la tabla de adyacencia, mientras que solo hay un nodo en la tabla de adyacencia.
Recorrido del gráfico
El recorrido del gráfico aquí habla principalmente sobre los dos métodos de búsqueda requeridos por Blue Bridge: primero la amplitud y primero la profundidad.
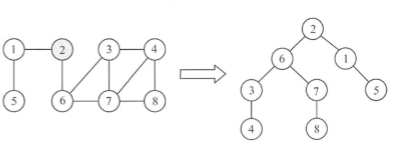
La búsqueda primero en amplitud es similar al algoritmo de recorrido de secuencia de un árbol binario. La idea básica es comenzar desde un punto y poner en cola todos los puntos no visitados a su alrededor, lo que equivale a crear un círculo circundante para envolver este punto de partida, y luego tomarlo de Punto, para poner en cola todos los puntos no visitados circundantes, parece que se expande capa por capa. El proceso de búsqueda en amplitud de atravesar el gráfico se basa en v como punto de partida, de cerca a lejos para visitar los vértices que tienen una ruta hacia ν y la longitud de la ruta es 1, 2,….
La búsqueda en amplitud es un proceso de búsqueda jerárquica. Cada paso hacia adelante puede visitar un lote de vértices. A diferencia de la búsqueda en profundidad, no hay retroceso, por lo que no es un algoritmo recursivo. Para lograr el acceso capa por capa, el algoritmo debe utilizar una cola auxiliar para memorizar la siguiente capa de vértices a los que se accede.
En el proceso de búsqueda amplia, se necesita una matriz para registrar si se ha visitado, y también se necesita una cola para almacenar los nodos. Todos los nodos se pondrán en cola una vez. En el peor de los casos, la complejidad del espacio es O (| V | ). Cuando se utiliza el método de almacenamiento de lista de adyacencia, cada vértice debe buscarse una vez (o ponerse en cola una vez), por lo que la complejidad del tiempo es O (| V |). Cuando se busca el punto vecino de cualquier vértice, cada borde se visita al menos una vez Por lo tanto, la complejidad de tiempo es 0 (| E |) y la complejidad de tiempo total del algoritmo es 0 (| V | + IEI). Cuando se adopta el método de almacenamiento de la matriz de adyacencia, el tiempo necesario para encontrar el punto adyacente de cada vértice es O (| V |), por lo que la complejidad de tiempo total del algoritmo es O (| V | 2).
En el proceso de recorrido de amplitud, podemos obtener un árbol transversal, llamado árbol de expansión primero en amplitud. Cabe señalar que la representación de almacenamiento de la matriz de adyacencia de un gráfico dado es única, por lo que su árbol de expansión primero en amplitud también es único, pero debido a que la representación de almacenamiento de la lista de adyacencia no es única, su árbol de expansión primero en amplitud tampoco lo es. Es decir, el árbol de expansión de ancho primero del gráfico almacenado en la matriz de adyacencia es único, y el árbol de búsqueda de ancho primero del gráfico almacenado en la tabla de adyacencia no es único.
La plantilla de código de Guangsou es la siguiente:
void bfs()
{
初试状态入队列
while(!q.empty())
{
p=q.front();
q.pop();
for(当前状态的所有可达状态)
{
if(未访问)
{
q.push(未访问状态);
visit[未访问状态]=1;
}
}
}
}
La búsqueda en profundidad es similar al recorrido de un árbol antes de ordenarlo. Para decirlo sin rodeos, es violencia, un camino hacia el negro. Su idea básica es comenzar desde un punto, moverse a un punto adyacente no visitado y luego continuar visitando el punto adyacente no visitado del punto adyacente después de moverse, y regresar a la capa anterior para continuar visitando otros puntos adyacentes no visitados después de la visita. completado, y repita este Movimiento hasta que no haya puntos para visitar.
De acuerdo con las características de DFS, generalmente se usa la recursividad para implementar el código:
void dfs(int x,int y)
{
for(所有可达的点)
{
int tx=x+dir[i][0];
int ty=y+dir[i][1];
移动到新的点
if(可访问且未访问)
{
vis[tx][ty]=1;
dfs(tx,ty);
}
}
}
De manera similar, para el mismo gráfico, la secuencia DFS y la secuencia BFS obtenidas por el recorrido según la matriz de adyacencia son únicas, y la secuencia DFS y la secuencia BFS obtenidas por el recorrido según la lista de adyacencia no son únicas.

El algoritmo DFS es un algoritmo recursivo que requiere una pila de trabajo recursiva, por lo que su complejidad de espacio es O (| V |). El proceso de atravesar el gráfico es esencialmente un proceso de encontrar sus puntos vecinos para cada punto, y el tiempo que lleva depende de la estructura de almacenamiento utilizada. Cuando se representa mediante una matriz de adyacencia, la complejidad de tiempo total es O (| V | 2). Cuando se representa mediante una lista de adyacencia, la complejidad de tiempo total es O (| V | + | E |).
Al igual que la búsqueda en amplitud, la búsqueda en profundidad también produce árboles de búsqueda en profundidad. Por supuesto, esto es condicional, es decir, llamar a DFS en el gráfico conectado puede generar un árbol de expansión en profundidad, de lo contrario se generará el árbol de expansión en profundidad.
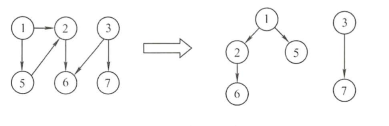
De acuerdo con las características de DFS, no es difícil encontrar que cada proceso DFS visite un componente conectado de un gráfico completamente una vez. En base a esto, el gráfico se puede usar para determinar el componente conectado. Si el DFS es una vez, el gráfico se puede atravesar. Para cada nodo de, significa que el gráfico tiene sólo un componente conectado, es decir, el gráfico es un gráfico conectado, de lo contrario es un gráfico no conectado.
Aplicación gráfica
Esta parte de la aplicación involucra principalmente cinco conocimientos, árbol de expansión mínimo, ruta más corta, gráfico acíclico dirigido, clasificación topológica y ruta crítica.
1. El árbol de expansión mínimo
En resumen, el árbol de expansión mínimo es el que tiene el menor peso entre todos los árboles de expansión en un gráfico. Puede que no sea único. Cuando todos los pesos de los bordes no son iguales, el árbol de expansión mínimo es el único uno. Aunque el árbol de expansión mínimo a veces no es único, la suma de pesos es única.
El punto de prueba del árbol de expansión mínimo es principalmente simular manualmente dos algoritmos para encontrar el árbol de expansión mínimo: el algoritmo de Prim y el algoritmo de Kruskal.
El algoritmo de Prim es similar al algoritmo de Dijkstra. La idea principal es sumar continuamente los puntos más cercanos al conjunto al conjunto de puntos determinados. Elija un punto para unirse al conjunto en el primer intento, y luego vea cuál de los puntos que puede alcanzar este conjunto es el más cercano, elija el punto más cercano para unirse al conjunto y repita este proceso hasta que todos los puntos se agreguen al conjunto. colocar.
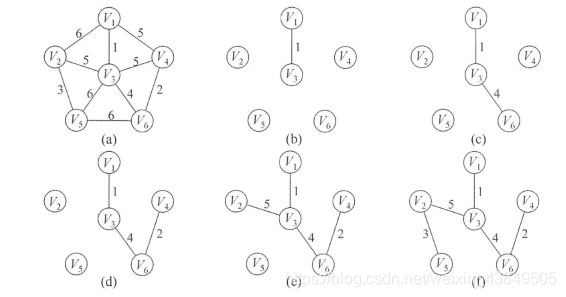
La complejidad de tiempo del algoritmo de Prim es O (| V | 2), por lo que es adecuado para resolver árboles de expansión mínima con bordes densos. Aunque otros métodos pueden mejorar la complejidad temporal del algoritmo de Prim, aumentan la complejidad de la implementación. Principalmente, escribiré a mano el proceso de agregar y seleccionar puntos.
El algoritmo de Kruskal es un método para comenzar desde el borde. En el estado inicial, solo hay puntos sin bordes. Cada vez que se agrega al gráfico un borde con el menor peso. Si no hay bucle, el borde se mantendrá en el Repita este proceso hasta que el gráfico se convierta en un gráfico conectado.
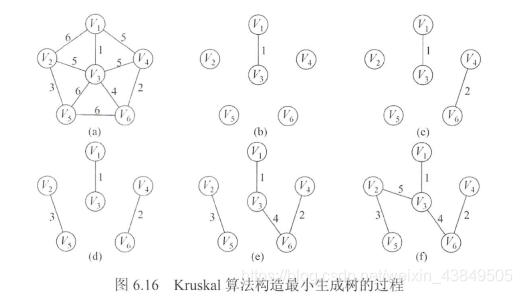
La complejidad de tiempo del algoritmo de Kruskal es O (| E | log | E |), que es adecuado para gráficos con bordes dispersos y muchos puntos.
2. El problema de la ruta más corta.
Cuando la gráfica es una gráfica ponderada, defina la suma de los pesos en los bordes de una ruta (quizás más de uno) desde un vértice Vo a cualquier otro vértice V en la gráfica como la banda de la ruta Longitud de ruta ponderada, la ruta con la longitud de ruta ponderada más corta se denomina ruta más corta. Generalmente, el problema de la ruta más corta se divide en dos categorías, la ruta más corta de una sola fuente (de un punto a los otros puntos) y la ruta más corta entre cada par de vértices, correspondientes al algoritmo de Dijkstra y al algoritmo de Freud, respectivamente.
El algoritmo de Dijkstra también se usa en la red informática para encontrar el protocolo OSPF. Durante la operación del algoritmo, se necesitan dos matrices para registrar el proceso. Dist se usa para registrar la distancia más corta al origen, y la ruta se usa para registrar la precursor, que es conveniente para el algoritmo. Encuentre la ruta completa al final. El primer paso del algoritmo es la inicialización. Si el punto de partida es V0, entonces los puntos alcanzables por V0 se inicializan a la distancia correspondiente en la matriz dist, y los puntos inalcanzables se inicializan al infinito, y el borde más corto en la matriz dist. se selecciona cada vez. Agregue los puntos al conjunto y luego actualice la matriz de dist. Si la distancia desde el punto recién agregado a otro punto es menor que la distancia directa desde el origen a otro punto, actualice la dist a la nueva distancia mínima y repetir esta operación hasta que todos los puntos hayan entrado en la colección.
El punto más importante del algoritmo de Dijkstra es que dibujará un diagrama de todo el proceso, incluida la actualización de la matriz dist y el proceso de selección de bordes.
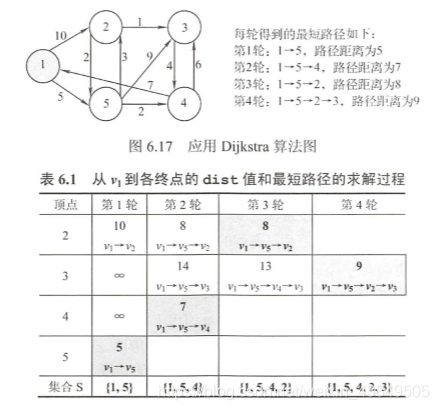
El algoritmo de Dijkstra se basa en la idea de codicia.Cada vez que se selecciona la solución óptima actual, ya sea almacenada en una lista de adyacencia o en una matriz de adyacencia, la complejidad temporal del algoritmo de Dijkstra es O (| V | 2). Cabe señalar que el algoritmo de Dijkstra no se puede utilizar cuando el peso del borde es negativo.
El algoritmo de Freud es otro algoritmo para encontrar el problema de la ruta más corta. Comparado con el algoritmo de Dijkstra, el algoritmo de Freud es más avanzado y más abstracto de entender.

En pocas palabras, iterar continuamente desde el estado inicial. El estado inicial es la matriz de adyacencia del gráfico. En este momento, significa que los dos puntos están conectados directamente sin transitar por otros puntos. La iteración subsiguiente significa tránsito continuo. Si la distancia de tránsito es mayor Corta, luego tome la distancia más corta como la distancia real.
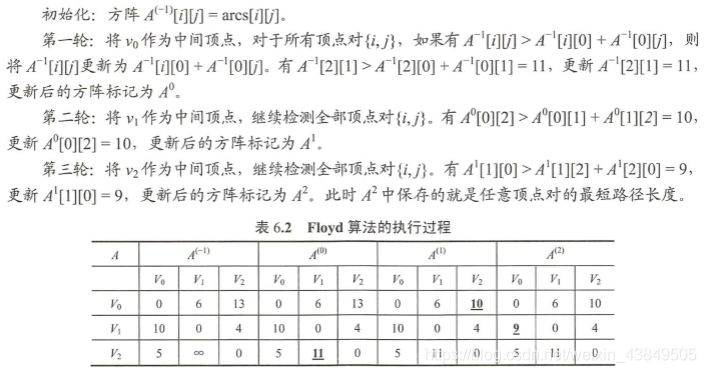
La complejidad temporal del algoritmo de Floyd es O (| V | 3). Sin embargo, debido a que el código es muy compacto y no contiene otras estructuras de datos complejas, el coeficiente constante implícito es muy pequeño, incluso para una entrada de mediana escala, sigue siendo bastante efectivo. El algoritmo de Freud puede resolver la situación en la que el peso del borde es negativo, pero aún no puede manejar la situación en la que hay bucles.
3. Representación de gráficos dirigidos acíclicos No
hay dificultad en esta parte, que consiste en utilizar gráficos acíclicos dirigidos para realizar el intercambio de subtipos repetidos, reduciendo así el espacio de almacenamiento.
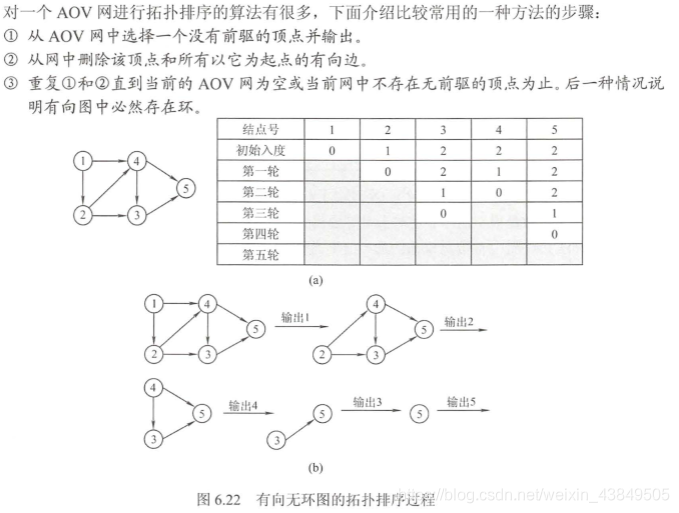
Cuarto, clasificación topológica En

pocas palabras, un gráfico se considera como un proceso para completar una cosa. Este proceso incluye muchas actividades. La clasificación topológica consiste en encontrar un orden que se pueda completar de acuerdo con este orden sin conflicto. La clasificación topológica no es única, lo importante es determinar el algoritmo de clasificación topológica. Al mismo tiempo, en algunos casos, se utiliza la clasificación topológica inversa, siempre que se invierta el siguiente proceso de clasificación topológica.
5. Ruta
crítica La ruta crítica es la más problemática de estas cinco aplicaciones, requiere muchos datos para calcular, pero el proceso no es difícil.
En un grafo dirigido ponderado, los eventos están representados por vértices, las actividades están representadas por bordes dirigidos y el costo de completar las actividades (tiempo requerido para completar las actividades) está representado por los pesos de los bordes. Esto se llama una red con bordes que representan actividades. Denominado AOE Net. Tanto las redes AOE como las redes AOV son gráficos acíclicos dirigidos. La diferencia es que sus bordes y vértices representan significados diferentes. Los bordes en la red AOE tienen pesos; mientras que los bordes en las redes AOV no tienen pesos, solo representa el contexto entre vértices. El punto donde el grado de entrada es 0 es el punto de inicio, también llamado punto de origen, y el punto donde el grado de salida es 0, es el punto final, también llamado punto de hundimiento. Las actividades en el diagrama de red AOE se pueden llevar a cabo en paralelo, y solo cuando se completan todas las actividades, el proyecto se puede considerar completo. El tiempo más corto para completar todo el proyecto es la longitud de la ruta crítica, es decir, el costo total de cada actividad en la ruta crítica. Esto se debe a que las actividades clave afectan el tiempo de todo el proyecto, es decir, si las actividades clave no se pueden completar a tiempo, el tiempo de finalización de todo el proyecto se prolongará. Por lo tanto, siempre que se encuentre la actividad clave, se encontrará la ruta crítica y se puede derivar el tiempo de finalización más corto.
Al calcular la ruta crítica, se calculan cuatro cantidades principales, la hora de ocurrencia más temprana y más reciente de un evento, y la hora de ocurrencia más temprana y más tardía de un evento. En el cálculo real, primero dibuje el diagrama AOE para ordenar la secuencia, luego comience desde el punto de partida, primero calcule el tiempo de ocurrencia más temprano del evento, el tiempo de ocurrencia más temprano del punto de origen es 0, y luego puede usar topológico ordenar para ver todos los precursores de cada nodo, encontrar el tiempo de ocurrencia más temprano del precursor más el tiempo de actividad más largo como su tiempo de ocurrencia más temprano, completar el tiempo de ocurrencia más temprano de todos los eventos y luego calcular el tiempo de ocurrencia más reciente, comenzando desde la reunión punto, tome la última hora de ocurrencia de todos los eventos posteriores. Reste el tiempo mínimo de actividad. Luego, calcula la hora de inicio más temprana y más tardía de la actividad. La hora de inicio más temprana de la actividad es la hora de inicio más temprana del evento representado por el punto de inicio del arco, y la hora de inicio más tardía es la diferencia entre el evento representado por el final del arco y la hora de la actividad. La diferencia entre la hora de inicio más temprana y la más tardía representa el tiempo flexible de esta actividad. Si los dos son iguales, significa que esta actividad no puede esperar. Si espera, las siguientes actividades se pospondrán, es decir , las actividades en la


ruta crítica de la actividad clave son todas. Para las actividades clave, el tiempo de estas actividades se puede reducir para reducir el tiempo total, pero no se puede reducir demasiado. Si se reduce demasiado, puede cambiar el ruta crítica y así cambiar las actividades clave. La ruta crítica en la red AOE no es única, y para una red con varias rutas críticas, solo aumentar la velocidad de las actividades clave en una ruta crítica no puede acortar el período de construcción de todo el proyecto, solo acelera las actividades clave incluidas en todas. caminos críticos Para lograr el propósito de acortar el período de construcción, es decir, la intersección de los caminos críticos.
Preguntas típicas

La clave de la pregunta es que en cualquier caso es diferente del caso mínimo. El caso mínimo se puede completar con solo 6 aristas, pero no lo es en ningún caso. El método utilizado aquí es tomar 6 puntos primero, y el gráfico completo de 6 puntos necesita 5+ 4 + 3 + 2 + 1 = 15 bordes En este momento, agregue el séptimo punto y agregue un borde para convertirlo en 16 bordes, luego debe estar conectado.

El doble de aristas en un gráfico no dirigido es igual a la suma de los grados de los vértices, por lo que en esta pregunta, la suma de los grados es 16 2 = 32, menos 4 3 + 3 4 + 2 x + 1 * y , la pregunta pregunta al menos cuántos vértices, por lo que y = 0, en este momento, x = 4 se puede resolver, y el número total de nodos es 4 + 4 + 3 = 11. De la misma manera, si pregunta cuántos vértices hay como máximo, entonces x = 0, y = 8, y el número total de puntos es 4 + 3 + 8 = 15.

El tema es un poco confuso. Primero, un árbol con n nodos tiene n-1 bordes. Suponiendo que hay x árboles, luego conectar el bosque en un árbol aumentará x-1 bordes. Luego, la ecuación e + (x-1) +1 se puede enumerar = n , entonces x = ne.
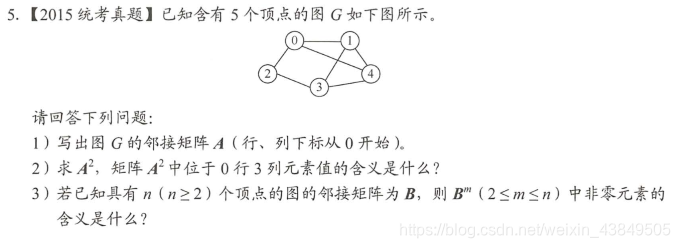
Cuando vi esta pregunta, me sentí obligado. Esta no es una prueba de multiplicación de matrices de álgebra lineal. La pregunta es realmente un poco abstracta y no está claro cómo resolverla. Personalmente, siento que depende completamente de encontrar el ley. Primero escribe el orden inferior de una matriz. En el caso del cuadrado, mira el valor específico para adivinar el significado del valor del elemento.


Usando el recorrido de profundidad primero, si comienza desde un vértice u en el gráfico dirigido, aparece un borde desde el vértice v hasta u antes del final de DFS (u). Dado que v es un descendiente de u en el árbol de expansión, la razón debe ser Hay bucles que contienen uyv, por lo que la búsqueda en profundidad puede detectar si un gráfico dirigido tiene un bucle.
En la ordenación topológica, la secuencia solo se puede agregar cuando un vértice no es la cabeza de ningún borde. Cuando hay un bucle, el vértice en el bucle es siempre la cabeza de un cierto borde y no se puede agregar a la secuencia topológica. En otras palabras, si todavía no hay ningún vértice que se pueda agregar a la secuencia topológica, significa que el gráfico tiene un bucle.
El camino más corto en sí mismo permite bucles, por lo que no se puede utilizar para determinar si hay bucles.
La ruta crítica es un poco inverosímil. Cuando se busca una ruta crítica, generalmente es necesario utilizar la clasificación topológica para obtener una secuencia y calcular el tiempo más temprano y más tardío de acuerdo con esta secuencia, de modo que pueda juzgar si hay un bucle. .

Los vértices no están en la secuencia topológica, lo que significa que estos vértices son siempre las cabezas de ciertos bordes, estos puntos se juntan para formar un bucle y estos bucles son solo un componente fuerte conectado.

