Capacidades clave 5G
En los últimos años, 5G se ha convertido en el punto más alto de la competencia estratégica en varios países y en una tecnología clave para el futuro desarrollo social e informatización. En la actualidad, los países han acelerado la estrategia y el diseño de políticas 5G. En 2019, el Ministerio de Industria y Tecnología de la Información emitió oficialmente licencias comerciales de 5G a China Telecom, China Mobile, China Unicom y China Radio and Television. China entró oficialmente en el primer año de uso comercial de 5G, que es un año antes que el original. plan para uso comercial. El último informe muestra que, a diciembre de 2020, los tres principales operadores de mi país tienen más de 250 millones de usuarios de 5G. Con la continua popularización de la tecnología 5G y la comercialización, 5G está impregnando todos los rincones de la vida social.
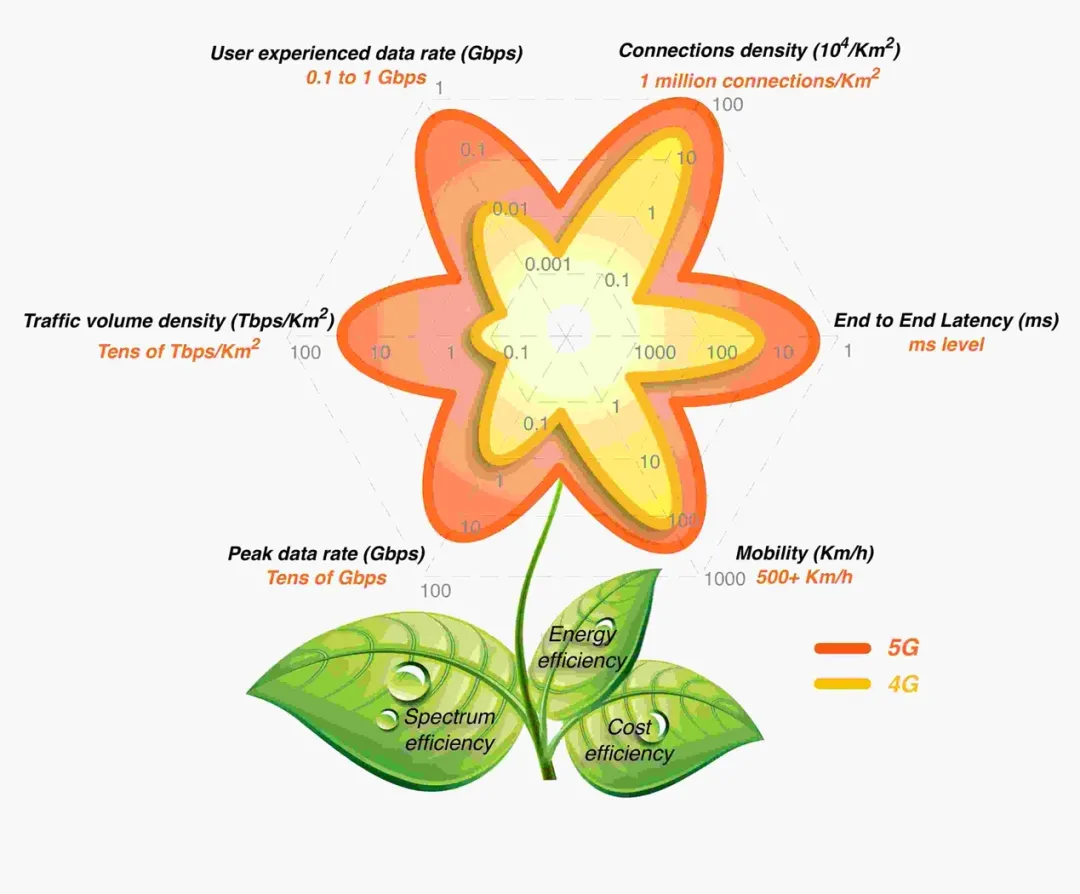
Figura 1 Capacidades 5G Flower-Key de 5G
Con respecto a la percepción actual de 5G, la atención se centra en la velocidad extrema. Pero para la visión de más capacidades 5G, todavía hay relativamente poco involucrado en esta etapa. Al comienzo del establecimiento del estándar 5G, los expertos en comunicaciones móviles dibujaron una "flor 5G" [1] para describir vívidamente las capacidades clave de 5G. Cada pétalo de la flor representa una capacidad técnica central, como se muestra en la Figura 1 .
En el escenario 5G, no solo la velocidad de la carretera es 10 veces más rápida, la carretera es 100 veces más ancha, sino que también se han mejorado significativamente el tráfico, la movilidad y las diversas eficiencias transportadas por la carretera. Mucha gente tiene una pregunta, ¿se pueden realmente realizar estas habilidades exigentes? Por ejemplo, con una latencia de un extremo a otro de 1 milisegundo, ¿cómo puede ser menor la latencia de la comunicación 5G que la de la comunicación de red fija? Es necesario aclarar aquí que el retraso de nivel de milisegundos de 5G no se refiere al retraso de la transmisión a larga distancia. Calculada a la velocidad de la luz, la información de tiempo de 1 milisegundo solo puede transmitir una distancia de 300.000 * 1/1000 = 300 kilómetros. Ya sea 5G, 6G o 7G, esta ley de la física no se puede romper. Y a través de las tecnologías de computación de borde de acceso múltiple y corte de baja latencia personalizada de la red 5G, la red central se está hundiendo a cien kilómetros del usuario final en ciudades, condados y municipios, y la latencia de nivel de milisegundos no es solo una charla vacía. .
Computación de borde de acceso múltiple (MEC)
El concepto de Edge Computing de acceso múltiple se propuso por primera vez en 2009 en la plataforma de computación cloudlet desarrollada por la Universidad Carnegie Mellon. Varias asociaciones de estándares de todo el mundo lo han incorporado gradualmente al estándar de comunicación y se ha convertido en una tecnología de comunicación móvil 5G. sistema Una de las tecnologías importantes.
Para evitar la aburrida narrativa técnica, permítanme dar un ejemplo popular primero. Supongamos que tenemos que enviar dos paquetes exprés, uno se envía de Shenzhen a Beijing y el otro se envía desde el distrito de Shenzhen Futian al distrito de Baoan en la misma ciudad. El primer mensajero se enviará desde Shenzhen a un centro de distribución de mensajería en un lugar determinado (por ejemplo, el centro de distribución de Zhengzhou), y luego a Beijing, y finalmente se entregará a los usuarios a través de puntos de mensajería gradual. No hay problema de esta manera. Sin embargo, si el segundo mensajero se entrega de esta manera, el segundo mensajero también se enviará desde el distrito de Futian al centro de distribución de Zhengzhou, y luego de regreso al distrito de Baoan, y finalmente se entregará al usuario.

Figura 2 5G y MEC
Todo el mundo pensará que este método es una locura. ¿Por qué no se envía la entrega urgente en la misma ciudad directamente en la ciudad, sino que primero se entrega a un centro de distribución a miles de kilómetros de distancia? La realidad es cruel. En las redes anteriores a 5G (incluidas las redes no independientes de 5G), los datos se procesan básicamente en la forma de red de acceso -> red portadora -> red central, y finalmente la red central decide cómo enviarlos y procesarlos. Incluso la comunicación entre dos terminales en la misma ciudad y la misma estación base debe informarse a la red central para su procesamiento antes de regresar. Esta vez, el retraso percibido por el usuario ha aumentado significativamente. La tecnología MEC puede hundir la potencia informática en el lado de la estación base, y la solicitud comercial del usuario de la terminal se puede resolver llamando a la potencia informática cercana en lugar de informarla al centro de computación central capa por capa y luego emitirla para su procesamiento, por lo tanto Reducir el retraso de transmisión de la red y reducir el tráfico de red que fluye hacia la nube central.
Servicio Edge AI basado en MEC
Después de la popularización de 5G, la mayoría de las interacciones informáticas se pueden procesar directamente en el nodo MEC. A medida que se ahorra la intervención de la red portadora y la red central, el retardo de la red se reduce en gran medida y los recursos de ancho de banda de la red se guardan en el Mismo tiempo. Se espera que el video de alta definición, VR / AR, juegos en la nube y otras aplicaciones marquen el comienzo de la próxima ola de explosiones con la popularización de 5G. Este artículo presentará una de las aplicaciones de hotspot en el escenario 5G: los servicios de inteligencia artificial de borde.
Desde el punto de vista del usuario, los servicios de IA (especialmente la fase de razonamiento) generalmente se pueden dividir en ejecución en el extremo o en la nube. La potencia de cálculo de los teléfonos móviles y otros dispositivos terminales ha aumentado gradualmente, lo que hace posible que algunos modelos simples de IA se ejecuten en el terminal. Sin embargo, el consumo limitado de energía de los dispositivos terminales es un problema que no se puede ignorar. Muchos modelos de IA que se ejecutan en terminales a menudo encuentran problemas de generación de calor, reducción de frecuencia y consumo excesivo de energía; además, un mayor número de otros dispositivos terminales, por Por ejemplo, cámaras, sensores y otros dispositivos de IoT, cuyos recursos informáticos limitados les dificulta ejecutar modelos comunes de IA en el extremo. Por otro lado, aunque el lado de la nube tiene una gran potencia informática, el modelo de IA que ejecuta está más alejado del lado final y no se puede garantizar el retraso; incluso si no es sensible al retraso, en el escenario de Internet de todo , si una gran cantidad de dispositivos finales dependen de los servicios de IA en el centro de la nube, su tráfico de ancho de banda tendrá un impacto significativo en la red existente.
Para resolver este dilema, surgieron los servicios de inteligencia artificial de borde basados en MEC. Aunque la potencia de cálculo del nodo MEC no es tan buena como la de la nube central, sigue siendo mucho mayor que la del dispositivo terminal.Algunos nodos MEC también incluyen GPU, FPGA y otro hardware de aceleración informática. El servicio de inteligencia artificial descargado al nodo de borde no solo puede ahorrar el costo de comunicación desde la terminal hasta el centro de la nube, sino que también puede proporcionar demoras en la comunicación de la red tan bajas como milisegundos.
La descarga informática es una de las funciones principales de la informática de borde. Para simplificar este escenario, solo tomamos la toma de decisiones de una sola tarea como ejemplo para el modelado y análisis. Para los usuarios finales, si se cumplen las siguientes condiciones (1), la descarga de la computación de IA desde el dispositivo final a la ejecución de borde mejorará significativamente la experiencia en el retraso de la finalización de la tarea.
C / Pd> C / Pe + D / Bc (1)
De manera similar, cuando se cumple la condición (2), descargar las tareas de computación de IA de los dispositivos finales a la ejecución de borde puede reducir el consumo de energía de computación.
C × Ed / Pd> C × Ee / Pe + D × Ec / Bc (2)
El significado de cada parámetro en la fórmula anterior es el siguiente:
Pd: velocidad de procesamiento del dispositivo final
Pe: velocidad de procesamiento del servidor en la nube del borde
C: cantidad de la tarea de cálculo
D: tamaño de la tarea a transmitir
Bc: tamaño del ancho de banda desde el dispositivo final al nodo del borde
Ed: consumo de energía de procesamiento del dispositivo final
Ee: consumo de energía de procesamiento del servidor en la nube de borde
Ec: consumo de energía de comunicación desde los dispositivos finales a los nodos de borde
Proyecto de implementación de Edge AI Astraea
Los desarrolladores y científicos de datos de modelos de inteligencia artificial generalmente no saben o no se preocupan demasiado por cómo funcionan sus modelos en el entorno de producción. Por ejemplo, al implementar modelos en el borde, se debe considerar que los modelos de IA de diferentes marcos requieren diferentes métodos de implementación, y también se requiere un servidor API para proporcionar modelos de IA a los usuarios finales. Además, los servicios de inteligencia artificial de borde también requieren capacidades de administración del ciclo de vida completo, incluidas actualizaciones de versión, lanzamientos en escala de grises, escalado automático, etc., así como capacidades de programación flexible para optimizar el equilibrio entre la experiencia del usuario, los costos de computación y los costos de tráfico.
Con este fin, el equipo de computación de borde de Alibaba Cloud propuso Astraea [2], una nueva plataforma de implementación de servicios de inteligencia artificial adecuada para escenarios de computación de borde, que simplifica la fase de implementación y aprovecha al máximo las ventajas de la computación de borde. A través del proyecto de implementación de inteligencia artificial de borde Astraea, los desarrolladores de modelos pueden completar automáticamente la implementación de servicios de inteligencia artificial en nodos de borde como MEC y convertir el proceso de inferencia de los servicios de inteligencia artificial en interfaces de API Restful para que los dispositivos terminales llamen, de modo que los dispositivos terminales puedan completar uso de 5G / El dividendo tecnológico aportado por MEC.

Figura 3 Arquitectura general de Astraea
Astraea tiene las siguientes ventajas. En primer lugar, los usuarios de Astraea solo necesitan enviar menos de 10 líneas de configuración de plantilla. Astraea puede crear la imagen en 1 minuto y completar la implementación del borde del servicio en 5 minutos. En segundo lugar, Astraea admite múltiples marcos de inteligencia artificial como Scikit learn, TensorFlow, Pythorch, ONNX, etc., que pueden generar automáticamente API Restful para servicios de inteligencia artificial con un solo clic. Con la ayuda de los servicios de nodo de borde de Astraea y Alibaba Cloud, los servicios de inteligencia artificial pueden hundirse a 10 kilómetros de los usuarios. Al mismo tiempo, Astraea realiza la automatización de la operación y el mantenimiento basándose en las capacidades de servicio de los nodos de borde de Alibaba Cloud.
Astraea puede implementar las siguientes capacidades basadas en la plataforma de servicio de nodo de borde:
Almacén de imágenes: como un almacén de almacenamiento para imágenes de AI de borde y proporcionar capacidades de aceleración de distribución de imágenes
.
Monitoreo, operación y mantenimiento: responsable del monitoreo del estado del contenedor de AI de borde y los servicios de registro relacionados

Figura 4 Paquete del modelo Astraea AI
DEMO de reconocimiento de matrículas en tiempo real
Para verificar las capacidades técnicas del servicio de inteligencia artificial basado en MEC, lo siguiente se basa en Astraea para implementar un ejemplo de servicio de reconocimiento de matrículas simple (lector de matrículas). En el experimento se utilizó un equipo de cámara terminal simulado Raspberry Pi 4. Como la Raspberry Pi actualmente no tiene un módulo de comunicación 5G, se compró además 5G WiFi en el experimento para convertir la señal 5G en una señal WiFi que se puede conectar a la Raspberry Pi para simular el enlace de comunicación 5G.

Figura 5 Hardware experimental utilizado en la verificación de prototipos
Debido a que Raspberry Pi usa CPU de arquitectura ARM, la potencia de cálculo es relativamente débil. Se mide que el programa de detección de matrículas se ejecuta directamente en Raspberry. Con un modelo previamente entrenado, se necesitan aproximadamente 13 segundos para reconocer el número de matrícula y su número en una posición de imagen. Obviamente, es imposible realizar el reconocimiento de matrículas en tiempo real utilizando la propia Raspberry Pi.
A continuación, implementaremos el servicio de inteligencia artificial de reconocimiento de matrículas en los nodos de borde. Ejecutar en el directorio del proyecto:
astraea buildEn este paso, el modelo de IA para el reconocimiento de matrículas se empaqueta en una imagen de servicio de IA, la interfaz API se expone de acuerdo con el archivo de configuración definido por el usuario y se envía al almacén de imágenes del nodo de borde.
A continuación, ejecute:
astraea deployEn este paso, Astraea programa el servicio de IA en el nodo especificado de acuerdo con el dominio de programación, las especificaciones y la información de cantidad especificada en el archivo de configuración. Por ejemplo, el servicio se puede implementar en un nodo de borde ubicado en el distrito de Baoshan, Shanghai, que puede proporcionar a los usuarios en el distrito de Baoshan, Shanghai, capacidades cercanas de reconocimiento de matrículas de baja latencia.
Astraea puede generar automáticamente Restful API de acuerdo con el método de llamada del modelo definido en la plantilla, devolver la dirección IP del servicio y el número de puerto y proporcionar una interfaz para que los usuarios llamen. En este ejemplo, el resultado del reconocimiento de la matrícula se puede obtener llamando directamente a la siguiente interfaz.
curl -g http://IP:port/predict -d 'json={"jsonData": "img_base64"}'Después de ser llamado, la API devolverá el resultado del reconocimiento del número de placa, incluida la cadena de la placa, la ubicación y la probabilidad de confianza). El servicio admite el reconocimiento de varias matrículas al mismo tiempo. Si hay varias matrículas en una imagen, el resultado se devolverá como una matriz json. Un ejemplo de un retorno de API es el siguiente:
{
"code": 0,
"request_id": "xxx-xxx-xxx",
"data": {
"msg": {},
"ndarray": [{
"confidence": 0.8996933911527906,
"rect": [120.92, 103.3, 73.57536804199219, 23.4],
"res": "\u9c81A88888"
}]
},
}Además, Astraea también proporciona funciones de monitoreo básicas. Al acceder a las siguientes interfaces, puede obtener información estadística como QPM, tiempo promedio de inferencia y número de llamadas de modelos.
curl -g http://IP:port/monitorEl valor de retorno es el siguiente:
{"AvgQPM":33.35,"AvgReqTime":"0.009s","Counter":3022}El valor de retorno indica que el servicio de IA se llama 33,35 veces por minuto en promedio, la demora de procesamiento promedio es de 9 ms y se realizan un total de 3022 llamadas.
Al encapsular aún más la interfaz API generada automáticamente por Astraea, se puede realizar la visualización y el reconocimiento de matrículas en tiempo real. Por ejemplo, la siguiente imagen es el resultado del reconocimiento de matrículas en tiempo real basado en Raspberry Pi 4. Se puede ver que, según el servicio de reconocimiento de matrículas implementado en el borde del nodo de borde, los dispositivos terminales con poca potencia informática (como Raspberry Pi, cámaras antiguas, etc.) también pueden lograr capacidades de procesamiento de IA potentes y de baja latencia. .

Figura 6 Servicio de reconocimiento de matrículas en tiempo real basado en Astraea
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.