-
El libro clásico del círculo de invitados de Kuangchuang : "Netty Zookeeper Redis High Concurrency Practical Combat" Entrevista Esencial + Entrevista Esencial + Entrevista Esencial [ Entrada general al jardín del blog ]
-
Libros clásicos de Crazy Maker Circle: "SpringCloud, Nginx High Concurrency Core Programming" Fundamentos para los principales fabricantes + Fundamentos para los principales fabricantes + Fundamentos para los principales fabricantes [ Entrada general de Blog Park ]
-
Necesario para ingresar a una gran fábrica + aumento de salario: Alta concurrencia [Combate real de mensajería instantánea con tráfico de 100 millones de niveles] Serie de combate real [Pico de SpringCloud Nginx] Serie de combate real [ Entrada general de Blog Park ]
Contenido: Sharding-JDBC desde el principio hasta el dominio
| tema | dirección de enlace |
|---|---|
| Preparación 1: instalar un clúster de máquinas virtuales en la ventana | Producción de entorno Linux de máquina virtual distribuida GO |
| Preparación 2: hay mysql en cada nodo de la máquina virtual | Notas de mysql de Centos (incluida la duplicación de mysql vagabunda) GO |
| Subbase de datos y subtabla-Sharding-JDBC- desde el nivel inicial hasta el nivel 1 | Subbase de datos Sharding-JDBC, subtabla (introducción al combate real) GO |
| Subbase de datos y subtabla-Sharding-JDBC- desde el nivel inicial hasta el nivel 2 | Conocimientos básicos de Sharding-JDBC GO |
| Sharding-JDBC de la entrada al maestro 3 | Clave primaria personalizada, clave primaria de copo de nieve distribuida, principio y combate real GO |
| Sub-base de datos y tabla-Sharding-JDBC- desde la entrada al maestro 4 | Réplica maestro-esclavo del clúster MYSQL , principio y combate real GO |
| Sharding-JDBC desde el nivel inicial hasta el nivel de suficiencia 5 | Leer y escribir separación combate real GO |
| Sharding-JDBC desde el nivel inicial hasta el nivel de suficiencia 6 | Principio de implementación de Sharding-JDBC GO |
| Código fuente para Sharding-JDBC desde la entrada hasta el maestro | dirección del almacén de git IR |
1. Acerca de Sharding-JDBC
No diré más sobre la introducción de Sharding-JDBC. Sharding-JDBC fue un marco de expansión horizontal para bases de datos relacionales desarrollado por Dangdang.com. Ahora se ha donado a Apache. Para conocer su principio, consulte el siguiente blog.
La dirección del documento de shardingsphere es: https://shardingsphere.apache.org/document/current/cn/overview/.
2 Escenario de combate real de Sharding-JDBC
Antes de obtener una comprensión más profunda, obtengamos una experiencia práctica para aumentar la impresión y despertar el interés.
En circunstancias normales, todo el mundo utilizará la tabla y la biblioteca de segmentación horizontal: una tabla se divide horizontalmente en varias tablas y también se puede colocar en varias bibliotecas . Esto involucra las reglas de fragmentación de datos, las más comunes son: tabla de módulo hash, tabla de rango numérico y tabla de algoritmo hash consistente.
1. Tabla de módulo de hash
El concepto generalmente adopta el método de segmentación de Hash modulo, por ejemplo: supongamos que 4 tablas se dividen en goods_id. (Goods_id% 4 tabla de determinación de redondeo)
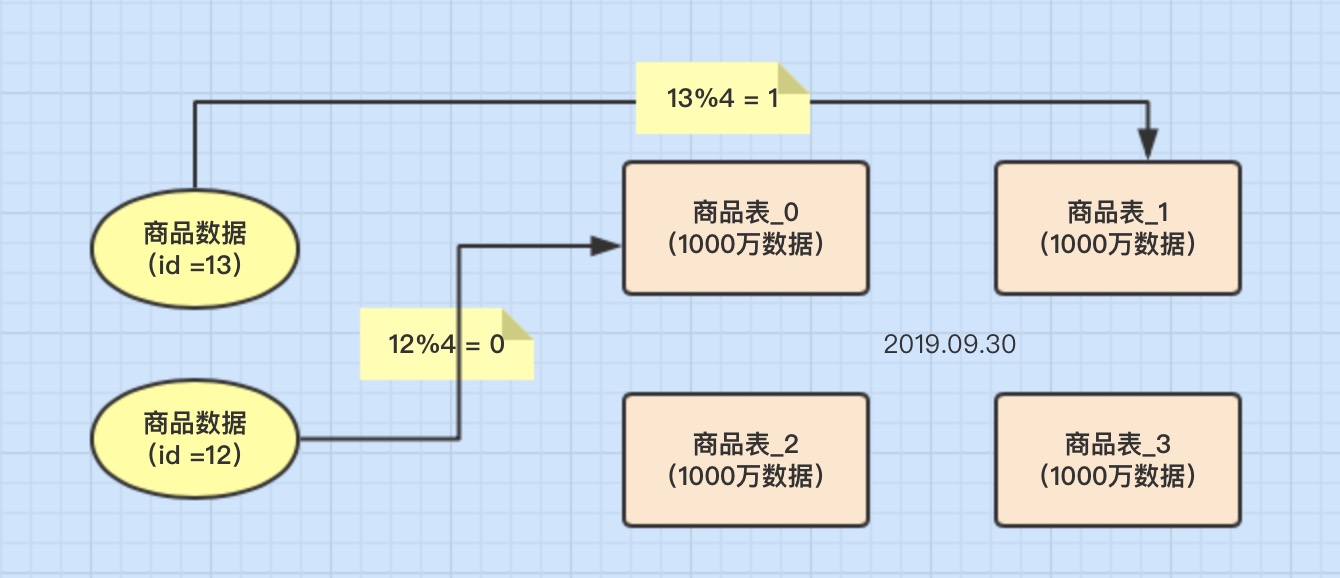
ventaja
- La fragmentación de datos es relativamente uniforme y no es propensa a puntos calientes y cuellos de botella de acceso concurrente.
Desventaja
-
Cuando el clúster fragmentado se expande más tarde, es difícil migrar datos antiguos.
-
Es fácil afrontar el complejo problema de las consultas entre fragmentos. Por ejemplo, en el ejemplo anterior, si las condiciones de consulta utilizadas con frecuencia no incluyen Goods_id, la base de datos no se podrá ubicar. Por lo tanto, es necesario iniciar una consulta en 4 bases de datos al mismo tiempo
y luego fusionar las datos en la memoria, tome el conjunto más pequeño y devuélvalo a la aplicación.
2. Subtabla de rango numérico
El concepto se divide en intervalos de tiempo o intervalos de identificación. Por ejemplo: asigne los registros con Goods_id 11000 a la primera tabla, asigne los registros con 10012000 a la segunda tabla, y así sucesivamente.
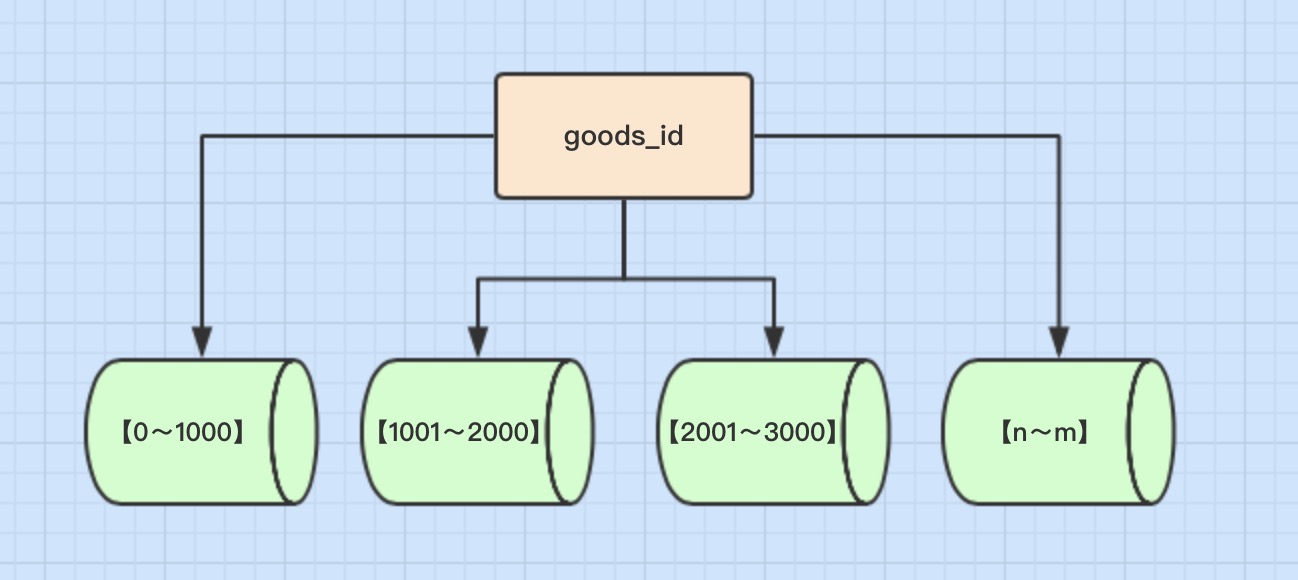
ventaja
- Tamaño de mesa única controlable
- Naturalmente, es fácil expandir horizontalmente. Si desea expandir todo el clúster de fragmentos más adelante, solo necesita agregar nodos y no es necesario migrar los datos de otros fragmentos.
- Cuando se utilizan campos de fragmentos para la búsqueda de rango, los fragmentos continuos pueden localizar fragmentos rápidamente para realizar consultas rápidas, lo que evita eficazmente el problema de la consulta entre fragmentos.
Desventaja
- Los datos calientes se convierten en un cuello de botella en el rendimiento.
Por ejemplo, fragmentación por campo de tiempo. Algunos fragmentos almacenan datos en el período de tiempo más reciente y pueden leerse y escribirse con frecuencia, mientras que los datos históricos almacenados en algunos fragmentos rara vez se consultan.
3. Algoritmo hash consistente
El algoritmo Hash consistente puede resolver el problema de la necesidad de migrar datos antiguos cuando el clúster fragmentado se expande debido al módulo Hash. En cuanto a los principios específicos, no entraré en detalles aquí.
Puede consultar un blog: Algoritmo hash consistente (subbase de datos y subtabla, equilibrio de carga, etc.)
4. Combate real: tabla de puntuación de módulo Hash simple
Suponiendo que user_id y order_id de una tabla de pedidos se distribuyen de manera relativamente uniforme, de acuerdo con el tamaño de los datos de 1000W, la siguiente subbase de datos y estructura de subtabla se pueden utilizar para guardar:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
Simplemente subbase de datos y subtabla: de acuerdo con las reglas de user_id% 2 para la subbase de datos, de acuerdo con las reglas de order_id% 2 para la subtabla
3 El diseño de la estructura de la mesa de la biblioteca:
3.1 Tabla de orden lógico
La estructura de la tabla de orden lógico es la siguiente:

3.2 Biblioteca de pedidos en el nodo 1 (cdh1)
DROP TABLE IF EXISTS `t_order_0`;
DROP TABLE IF EXISTS `t_order_1`;
DROP TABLE IF EXISTS `t_config`;
CREATE TABLE `t_order_0` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
CREATE TABLE `t_order_1` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
3.3 Biblioteca de pedidos en el nodo 2 (cdh2)
DROP TABLE IF EXISTS `t_order_0`;
DROP TABLE IF EXISTS `t_order_1`;
DROP TABLE IF EXISTS `t_config`;
CREATE TABLE `t_order_0` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
CREATE TABLE `t_order_1` (`order_id` bigInt NOT NULL, `user_id` INT NOT NULL, `status` VARCHAR(45) NULL, PRIMARY KEY (`order_id`));
En ambas bases de datos, hay dos tablas t_order_0 y t_order_1
4 Configuración de la subtabla de la subbase de datos Sharding-JDBC
- Sub-biblioteca
El ejemplo de subbase de datos en este artículo es relativamente simple. Se juzga de acuerdo con el campo user_id% 2 en la tabla de la base de datos. Si user_id% 2 == 0, use ds0, de lo contrario use ds1.
- Submesa
La submuestra es relativamente simple, juzgue de acuerdo con el campo order_id% 2 en la tabla de la base de datos, si order_id% 2 == 0, use t_order_0, de lo contrario use t_order_1.
La subbase de datos horizontal y la subtabla de la tabla de datos que se muestra en la siguiente figura se realizan en la tabla t_order, como se muestra en la siguiente figura:
(También se requiere una fragmentación horizontal similar para la tabla t_order_item, pero se omite esta parte de la configuración):
En el archivo de configuración yml, puede usar expresiones Groovy para configurar las reglas para la subbase de datos y la tabla. Las expresiones Groovy específicas son las siguientes:
表达式一: 例如 ds0.t_order_0
ds$->{0..1}.t_order_$->{0..1}
表达式一:db 维度的拆分, 例如 ds_0、ds_1
ds_${user_id % 2}
表达式一:table 维度的拆分, 例如 t_order_1
t_order_${order_id % 2}
Estas expresiones se denominan expresiones Groovy y su significado es fácil de reconocer:
1) Dividir t_order en dos dimensiones: dimensión db y dimensión de la tabla;
2) En la dimensión db, los registros de user_id% 2 == 0 caen todos a ds0, y los registros de user_id% 2 == 1 caen todos a ds1; (algunas personas llaman a este proceso sub-base de datos horizontal, de hecho, su esencia sigue siendo horizontal La tabla está dividida, pero la tabla dividida se coloca en dos instancias de base de datos de acuerdo con el user_id en la tabla).
3) En la dimensión de la tabla, todos los registros con order_id% 2 == 0 caen en t_order0, y todos los registros con order_id% 2 == 1 caen en t_order1.
4) La lectura y escritura de registros se realiza en esta dirección, la "dirección" es el método de fragmentación, que es el encaminamiento.
Con esta concisa expresión de Groovy, puede establecer la estrategia de fragmentación y el algoritmo de fragmentación. Pero el significado que se puede expresar de esta manera es limitado. Por lo tanto, el funcionario proporciona una interfaz de estrategia de fragmentación y una interfaz de algoritmo de fragmentación, lo que le permite expresar estrategias de fragmentación y algoritmos de fragmentación más complejos con código Java.
De hecho, el algoritmo de fragmentación es una parte integral de la estrategia de fragmentación, y la configuración de la estrategia de fragmentación = configuración de la clave de fragmentación + configuración del algoritmo de fragmentación. La estrategia utilizada en la configuración anterior es la estrategia de fragmentación de tipo Inline, y el algoritmo utilizado es el algoritmo de expresión de línea de tipo Inline.
La configuración específica es la siguiente:
spring:
application:
name: sharding-jdbc-provider
jpa: #配置自动建表:updata:没有表新建,有表更新操作,控制台显示建表语句
hibernate:
ddl-auto: none
dialect: org.hibernate.dialect.MySQL5InnoDBDialect
show-sql: true
freemarker:
allow-request-override: false
allow-session-override: false
cache: false
charset: UTF-8
check-template-location: true
content-type: text/html
enabled: true
expose-request-attributes: false
expose-session-attributes: false
expose-spring-macro-helpers: true
prefer-file-system-access: true
settings:
classic_compatible: true
default_encoding: UTF-8
template_update_delay: 0
suffix: .ftl
template-loader-path: classpath:/templates/
shardingsphere:
props:
sql:
show: true
# 配置真实数据源
datasource:
common:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
validationQuery: SELECT 1 FROM DUAL
names: ds0,ds1
ds0:
url: jdbc:mysql://cdh1:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
username: root
password: 123456
# 配置第 2 个数据源 org.apache.commons.dbcp2
ds1:
url: jdbc:mysql://cdh2:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
username: root
password: 123456
# 配置分片规则和分片算法
rules:
# 配置分片规则
sharding:
tables:
# 配置 t_order 表规则
t_order:
actualDataNodes: ds$->{0..1}.t_order_$->{0..1}
# 配置分库策略
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database-inline
# 配置分表策略
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table-inline
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
# 配置分片算法
bindingTables: t_order
sharding-algorithms:
database-inline:
type: INLINE
props:
algorithm-expression: ds$->{user_id % 2}
table-inline:
type: INLINE
props:
algorithm-expression: t_order_$->{order_id % 2}
keyGenerators:
snowflake:
type: SNOWFLAKE
props:
workerId: 123
5. Implementación del código
Este artículo utiliza SpringBoot2, SpringData-JPA, grupo de conexiones Druid y sharding-jdbc 5 de Dangdang.
5.1 Archivos dependientes
Cree un nuevo proyecto, agregue la dependencia sharding-jdbc-core de Dangdang y el grupo de conexiones druidas. Ver proyecto de código fuente.
5.2 Inicio
Utilice @EnableTransactionManagement para abrir la transacción,
Use la anotación @EnableConfigurationProperties para agregar la entidad de configuración, ingrese el código completo de la clase de inicio como se muestra.
package com.crazymaker.springcloud.sharding.jdbc.demo.start;
@EnableConfigurationProperties
@SpringBootApplication(scanBasePackages =
{"com.crazymaker.springcloud.sharding.jdbc.demo",
// "com.crazymaker.springcloud.base",
// "com.crazymaker.springcloud.standard"
}, exclude = {
DataSourceAutoConfiguration.class,
SecurityAutoConfiguration.class,
DruidDataSourceAutoConfigure.class})
@EnableScheduling
@EnableSwagger2
@EnableJpaRepositories(basePackages = {
"com.crazymaker.springcloud.sharding.jdbc.demo.dao.impl",
// "com.crazymaker.springcloud.base.dao"
})
@EnableTransactionManagement(proxyTargetClass = true)
@EntityScan(basePackages = {
// "com.crazymaker.springcloud.user.*.dao.po",
"com.crazymaker.springcloud.sharding.jdbc.demo.entity.jpa",
// "com.crazymaker.springcloud.standard.*.dao.po"
})
/**
* 启用 Hystrix
*/
@EnableHystrix
@EnableFeignClients(
basePackages = "com.crazymaker.springcloud.user.info.remote.client",
defaultConfiguration = FeignConfiguration.class)
@Slf4j
@EnableEurekaClient
public class ShardingJdbcDemoCloudApplication
{
public static void main(String[] args)
{
ConfigurableApplicationContext applicationContext = SpringApplication.run(ShardingJdbcDemoCloudApplication.class, args);
Environment env = applicationContext.getEnvironment();
String port = env.getProperty("server.port");
String path = env.getProperty("server.servlet.context-path");
System.out.println("\n----------------------------------------------------------\n\t" +
"Application is running! Access URLs:\n\t" +
"Local: \t\thttp://localhost:" + port + path + "/index.html\n\t" +
"swagger-ui: \thttp://localhost:" + port + path + "/swagger-ui.html\n\t" +
"----------------------------------------------------------");
}
}
5.3 Clase de entidad y capa de operación de la base de datos
Es una entidad simple y un repositorio. Para obtener más detalles, consulte el proyecto de código fuente.
/*
* Copyright 2016-2018 shardingsphere.io.
* <p>
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
* </p>
*/
package com.crazymaker.springcloud.sharding.jdbc.demo.entity.jpa;
import com.crazymaker.springcloud.sharding.jdbc.demo.entity.Order;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "t_order")
public final class OrderEntity extends Order
{
@Id
@Column(name = "order_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Override
public long getOrderId() {
return super.getOrderId();
}
@Column(name = "user_id")
@Override
public int getUserId() {
return super.getUserId();
}
@Column(name = "status")
public String getStatus() {
return super.getStatus();
}
}
5.4 Capa de servicio
Para obtener más detalles, consulte el proyecto de código fuente.
5.4 Controlador
A continuación, cree un controlador para probar. El método de guardar utiliza insertar datos y ver datos. De acuerdo con nuestras reglas, los datos se insertarán en cada biblioteca. Al mismo tiempo, también creé un método de consulta aquí para consultar todos los pedidos.
package com.crazymaker.springcloud.sharding.jdbc.demo.controller;
@RestController
@RequestMapping("/api/sharding/")
@Api(tags = "sharding jdbc 演示")
public class ShardingJdbcController
{
@Resource
JpaEntityService jpaEntityService;
@PostMapping("/order/add/v1")
@ApiOperation(value = "插入订单")
public RestOut<Order> orderAdd(@RequestBody Order dto)
{
jpaEntityService.addOrder(dto);
return RestOut.success(dto);
}
@PostMapping("/order/list/v1")
@ApiOperation(value = "查询订单")
public RestOut<List<Order>> listAll()
{
List<Order> list = jpaEntityService.selectAll();
return RestOut.success(list);
}
}
6 Realice la prueba
6.1 fanfarronería abierta
Inicie la aplicación.
Luego, visite http: // localhost: 7700 / sharding-jdbc-provider / swagger-ui.html en el navegador o en la herramienta de solicitud HTTP, como se muestra en la figura
6.2 Agregar dos datos
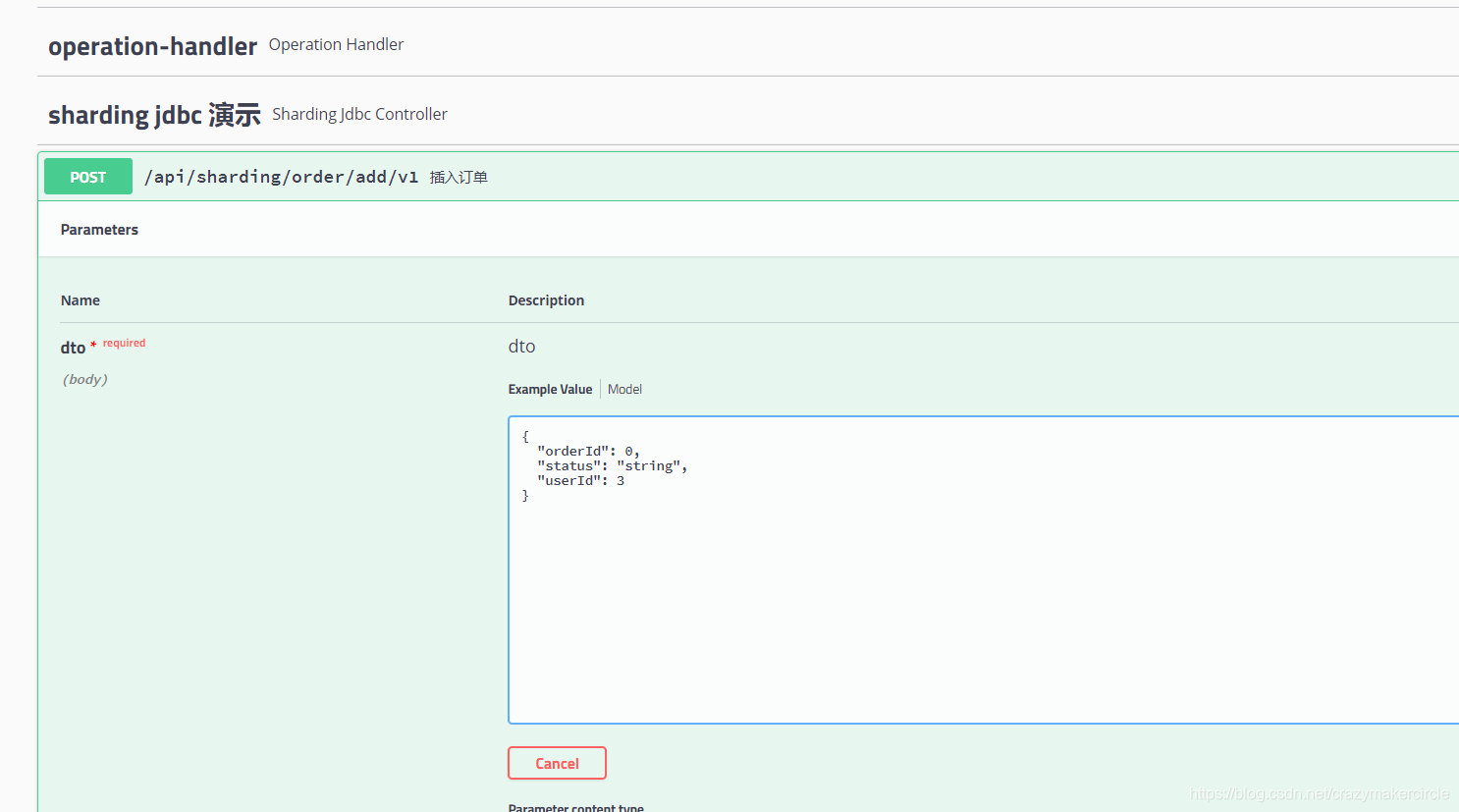
Use la interfaz para insertar un pedido, puede insertar un pedido, preste atención al ID de usuario% 2 == 0 para ingresar db1, preste atención al ID de usuario% 2 == 1 para ingresar db2, ¿en qué tabla está?
Debido a que el orderid es generado por el algoritmo de copo de nieve, si orderid% 2 == 0, ingrese t_order_0; de lo contrario, use t_order_1.
Después de insertar, puede ver los resultados a través de la base de datos. Los detalles son los siguientes:

6.3 Ver datos
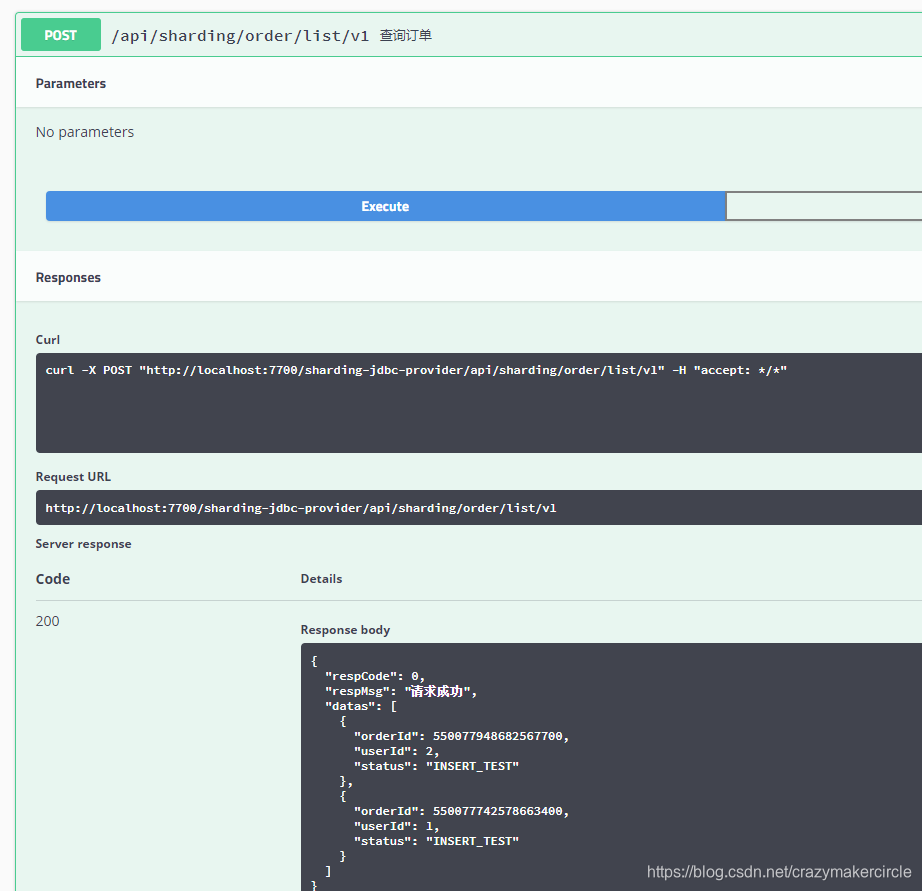
Utilice el método de consulta del programa, shardingjdbc, para averiguar todos los pedidos.
7 Resumen
Usando shardingjdbc, excepto por algunas reglas especiales para la configuración de la fuente de datos, no hay mucha diferencia entre el programa de capa de persistencia y el código JPA ordinario.
Por supuesto, si desea implementar una lógica de subtabla de subbase de datos especial, aún necesita mover el código, consulte la descomposición posterior.
Volver a ◀ Círculo de creadores de locos ▶
Comunidad de investigación de alta concurrencia de Crazy Maker Circle-Java, abre la puerta a grandes fábricas para todos