-
El libro clásico del círculo de invitados de Kuangchuang : "Netty Zookeeper Redis High Concurrency Practical Combat" Entrevista Esencial + Entrevista Esencial + Entrevista Esencial [ Entrada general al jardín del blog ]
-
Libros clásicos de Crazy Maker Circle: "SpringCloud, Nginx High Concurrency Core Programming" Fundamentos para los principales fabricantes + Fundamentos para los principales fabricantes + Fundamentos para los principales fabricantes [ Entrada general de Blog Park ]
-
Necesario para ingresar a una gran fábrica + aumento de salario: Alta concurrencia [Combate real de mensajería instantánea con tráfico de 100 millones de niveles] Serie de combate real [Pico de SpringCloud Nginx] Serie de combate real [ Entrada general de Blog Park ]
Directorio: Subbase de datos y subtabla-Sharding-JDBC
| Componente | dirección de enlace |
|---|---|
| Preparación 1: instalar un clúster de máquinas virtuales en la ventana | Producción de entorno Linux de máquina virtual distribuida GO |
| Y: mysql debe instalarse en la máquina virtual | Notas de mysql de Centos (incluida la duplicación de mysql vagabunda) GO |
| Subbase de datos y subtabla-Sharding-JDBC- desde el nivel inicial hasta el nivel 1 | Subbase de datos Sharding-JDBC, subtabla (introducción al combate real) GO |
| Subbase de datos y subtabla-Sharding-JDBC- desde el nivel inicial hasta el nivel 2 | Conocimientos básicos de Sharding-JDBC GO |
| Subbase de datos y tabla-Sharding-JDBC- desde la entrada al maestro 3 | Réplica maestro-esclavo del clúster MYSQL , principio y combate real GO |
| Sharding-JDBC de la entrada al maestro 4 | Llave primaria personalizada, llave primaria distribuida, principio y combate real GO |
| Sharding-JDBC desde el nivel inicial hasta el nivel de suficiencia 5 | Separación de lectura y escritura, principio y combate real GO |
| Sharding-JDBC desde el nivel inicial hasta el nivel de suficiencia 6 | Principio de implementación de Sharding-JDBC GO |
| Código fuente para Sharding-JDBC desde la entrada hasta el maestro | git |
1. Descripción general: tres estrategias de generación de claves principales para sharding-jdbc
En el desarrollo de software de base de datos tradicional, la tecnología de generación automática de clave primaria es un requisito básico. Las principales bases de datos también brindan el soporte correspondiente para esta demanda, como la clave de incremento automático de MySQL. Para MySQL, después de la subtabla de la subbase de datos, las diferentes tablas generan un Id único globalmente es un problema muy difícil. Debido a que las claves de incremento automático entre diferentes tablas reales en la misma tabla lógica no pueden reconocerse entre sí, esto provocará una generación de Id repetida. Por supuesto, podemos lograr la no repetición de datos restringiendo las reglas de las claves de generación de tablas, pero esto requiere la introducción de operaciones adicionales y fuerzas de mantenimiento para resolver el problema repetitivo, y el marco carece de escalabilidad.
La interfaz principal de la clave primaria distribuida proporcionada por sharding-jdbc es ShardingKeyGenerator. La interfaz de la clave primaria distribuida se utiliza principalmente para especificar cómo generar incrementos automáticos globales, adquisición de tipos, configuración de atributos, etc.
Sharding-jdbc proporciona dos estrategias de generación de claves primarias UUID、SNOWFLAKE, SNOWFLAKE se utiliza de forma predeterminada y las clases de implementación correspondientes son UUIDShardingKeyGenerator y SnowflakeShardingKeyGenerator.
Además de las dos clases de estrategia integradas anteriores, también puede personalizar el generador de clave principal basado en ShardingKeyGenerator.
2. Generador personalizado de claves primarias de incremento automático
shardingJdbc extrae la interfaz ShardingKeyGenerator del generador de clave primaria distribuida, que es conveniente para que los usuarios implementen su propio generador de clave primaria autoincrementante personalizado.
2.1 Código de referencia para el generador de clave primaria personalizado
package com.crazymaker.springcloud.sharding.jdbc.demo.strategy;
import lombok.Data;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
// 单机版 AtomicLong 类型的ID生成器
@Data
public class AtomicLongShardingKeyGenerator implements ShardingKeyGenerator
{
private AtomicLong atomicLong = new AtomicLong(0);
private Properties properties = new Properties();
@Override
public Comparable<?> generateKey() {
return atomicLong.incrementAndGet();
}
@Override
public String getType() {
//声明类型
return "AtomicLong";
}
}
2.2 Configuración de la interfaz SPI
En Apache ShardingSphere, muchas clases de implementación de funciones se cargan mediante inyección SPI. La interfaz de proveedor de servicios (SPI) es una API destinada a ser implementada o extendida por terceros. Puede usarse para implementar extensiones de marco o reemplazo de componentes.
SPI son las siglas de Service Provider Interface, que es un conjunto de interfaces proporcionadas por Java para ser implementadas o extendidas por terceros. Se puede utilizar para habilitar extensiones de framework y reemplazar componentes. La función de SPI es encontrar implementaciones de servicios para estas API extendidas.
SPI es en realidad un mecanismo de carga dinámico realizado por la combinación de " programación basada en interfaz + modo de estrategia + archivo de configuración ".
SPI se usa ampliamente en Spring, como la implementación de ServletContainerInitializer para la especificación servlet3.0, conversión automática de tipos Conversión de tipos SPI (Converter SPI, Formatter SPI), etc.
La razón por la que Apache ShardingSphere utiliza SPI para expandirse se debe al diseño óptimo de la arquitectura general. Para permitir que los usuarios avanzados carguen dinámicamente clases de implementación definidas por el usuario a través de la implementación de las interfaces correspondientes proporcionadas por Apache ShardingSphere, para satisfacer las necesidades reales de los usuarios en diferentes escenarios mientras se mantiene la integridad y estabilidad funcional de la arquitectura Apache ShardingSphere .
Agregue el siguiente archivo: META-INF / services / org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,
El contenido del archivo es: com.crazymaker.springcloud.sharding.jdbc.demo.strategy.AtomicLongShardingKeyGenerator.
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
#配置自己的 AtomicLongShardingKeyGenerator
com.crazymaker.springcloud.sharding.jdbc.demo.strategy.AtomicLongShardingKeyGenerator
#org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator
#org.apache.shardingsphere.core.strategy.keygen.UUIDShardingKeyGenerator
El archivo original del archivo anterior es el archivo de configuración spi copiado de META-INF / services de sharding-core-common-4.1.0.jar.
2.3 Utilice un generador de ID personalizado
Al configurar la estrategia de fragmentación, puede configurar un generador de ID personalizado, utilizando el tipo de generador. La configuración específica es la siguiente:
spring:
shardingsphere:
datasource:
names: ds0,ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
filters: com.alibaba.druid.filter.stat.StatFilter,com.alibaba.druid.wall.WallFilter,com.alibaba.druid.filter.logging.Log4j2Filter
url: jdbc:mysql://cdh1:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
password: 123456
username: root
maxActive: 20
initialSize: 1
maxWait: 60000
minIdle: 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
connection-properties: druid.stat.merggSql=ture;druid.stat.slowSqlMillis=5000
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
filters: com.alibaba.druid.filter.stat.StatFilter,com.alibaba.druid.wall.WallFilter,com.alibaba.druid.filter.logging.Log4j2Filter
url: jdbc:mysql://cdh2:3306/store?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
password: 123456
username: root
maxActive: 20
initialSize: 1
maxWait: 60000
minIdle: 1
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxOpenPreparedStatements: 20
connection-properties: druid.stat.merggSql=ture;druid.stat.slowSqlMillis=5000
sharding:
tables:
#逻辑表的配置很重要,直接关系到路由是否能成功
#shardingsphere会根据sql语言类型使用对应的路由印象进行路由,而logicTable是路由的关键字段
# 配置 t_order 表规则
t_order:
#真实数据节点,由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式
actual-data-nodes: ds$->{0..1}.t_order_$->{0..1}
key-generate-strategy:
column: order_id
key-generator-name: snowflake
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: t_order_$->{order_id % 2}
database-strategy:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2}
key-generator:
column: order_id
type: AtomicLong
props:
worker.id: 123
2.4 Prueba de clave primaria personalizada
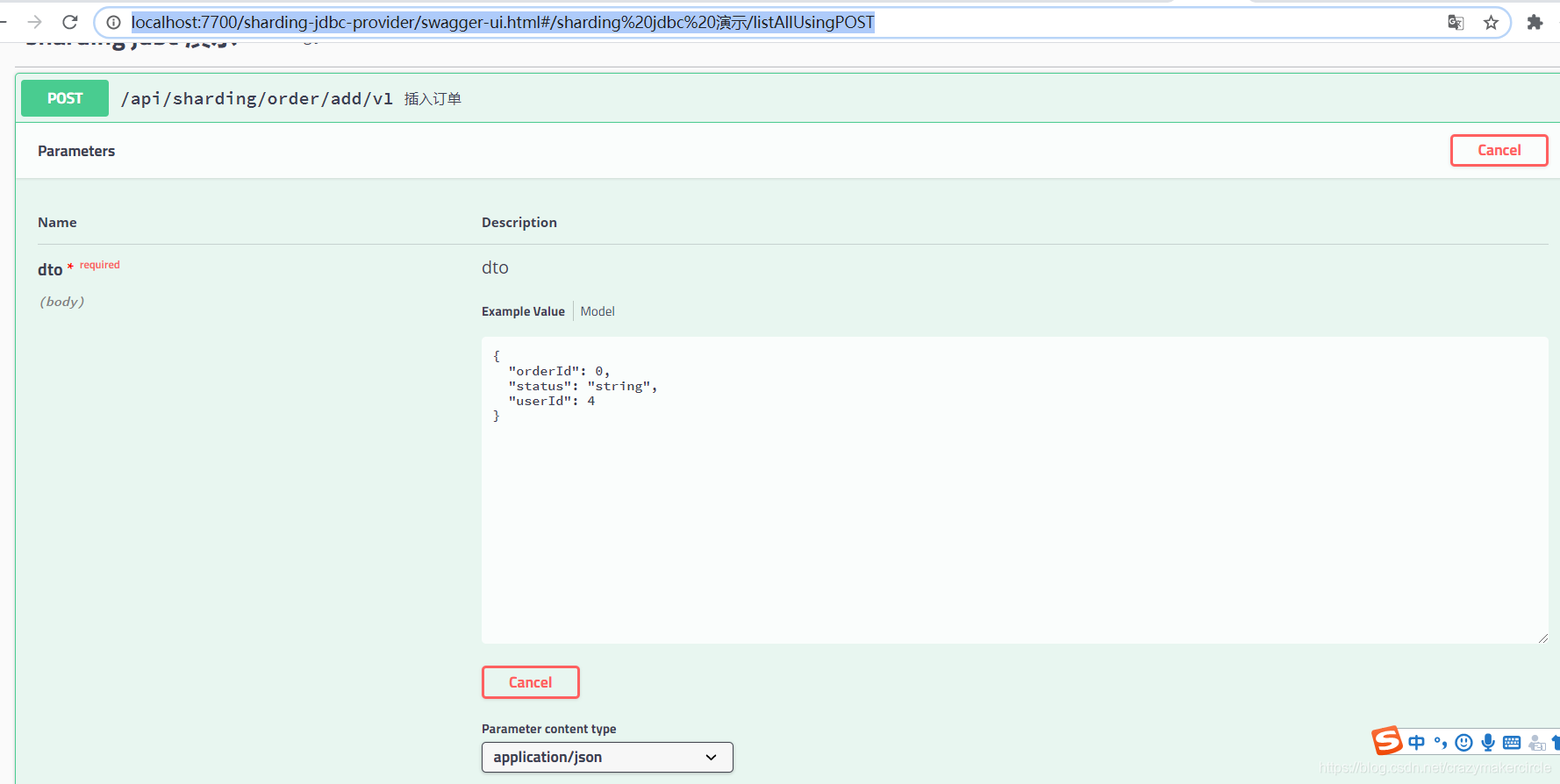
Inicie la aplicación, acceda a su interfaz de interfaz de usuario swagger y conéctese de la siguiente manera:
http://localhost:7700/sharding-jdbc-provider/swagger-ui.html#/sharding%20jdbc%20%E6%BC%94%E7%A4%BA/listAllUsingPOST
Agregue un pedido, el ID de usuario del pedido es 4 y el orderid no está completo, deje que el fondo lo genere automáticamente, como se muestra en la siguiente figura:
Después de enviar el pedido, puede ver todos los pedidos a través de la interfaz de consulta en la interfaz de usuario de swagger, como se muestra a continuación:
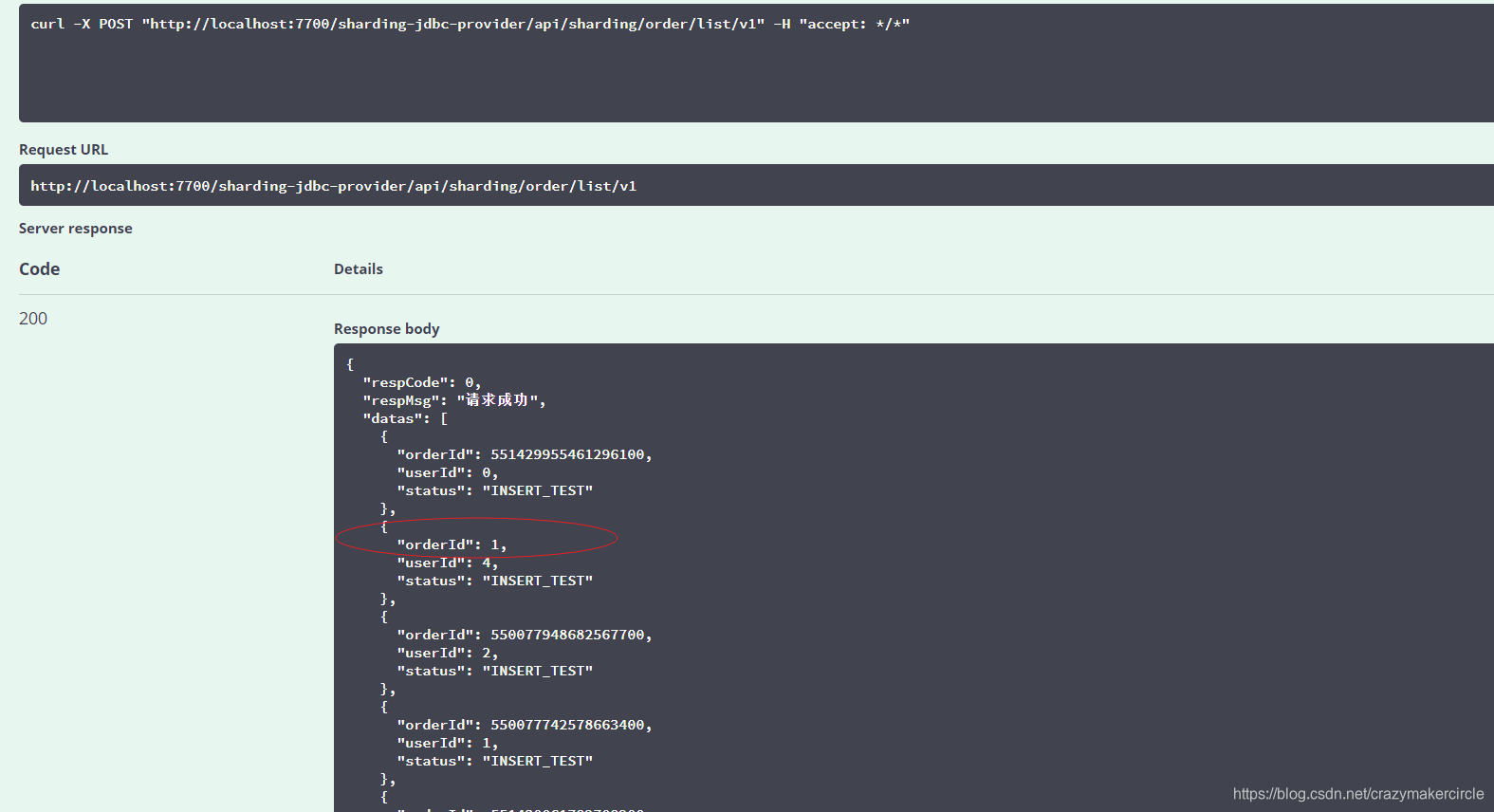
Como puede ver en la figura anterior, la nueva identificación de pedido es 1, que ya no es la identificación generada por el algoritmo de copo de nieve anterior.
Además, del registro impreso en la consola, se puede ver que la identificación generada es 1. El registro para insertar un pedido es el siguiente
[http-nio-7700-exec-8] INFO ShardingSphere-SQL - Actual SQL: ds0 ::: insert into t_order_1 (status, user_id, order_id) values (?, ?, ?) ::: [INSERT_TEST, 4, 1]
Inserte el pedido repetidamente, el ID del pedido será generado por AtomicLongShardingKeyGenerator, comenzando desde 1/2/3/4/5/6 / ...
Generador 3.UUID
Las clases de implementación del generador de ID integrado de ShardingJdbc incluyen UUIDShardingKeyGenerator y SnowflakeShardingKeyGenerator. Dependiendo del algoritmo UUID para generar claves de clave primaria únicas, la implementación de UUIDShardingKeyGenerator es muy simple, y su código fuente es el siguiente:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.shardingsphere.core.strategy.keygen;
import lombok.Getter;
import lombok.Setter;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Properties;
import java.util.UUID;
/**
* UUID key generator.
*/
@Getter
@Setter
public final class UUIDShardingKeyGenerator implements ShardingKeyGenerator {
private Properties properties = new Properties();
@Override
public String getType() {
return "UUID";
}
@Override
public synchronized Comparable<?> generateKey() {
return UUID.randomUUID().toString().replaceAll("-", "");
}
}
Debido a la función de índice B + Tree adoptada por InnoDB, el rendimiento de inserción de la clave principal generada por UUID es deficiente, y el UUID a menudo no se recomienda como clave principal.
4 algoritmo de copo de nieve
4.1 Introducción al algoritmo de copo de nieve
Hay muchos tipos de algoritmos de generación de id distribuidos, el SnowFlake de Twitter es uno de los clásicos.
Hay un dicho que dice que no hay dos copos de nieve idénticos en la naturaleza. Cada copo de nieve tiene su propia forma hermosa y única y es único. El algoritmo del copo de nieve también significa que la identificación generada es tan única como un copo de nieve.

1. Descripción general del algoritmo de copo de nieve
El ID generado por el algoritmo del copo de nieve es puramente numérico y cronológico. La versión original era la versión scala, y más tarde aparecieron muchas otras versiones de idiomas como Java, C ++, etc.
2. Composición
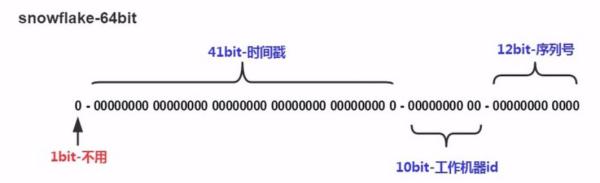
Se compone aproximadamente de cuatro partes: el primer carácter no válido, la diferencia de marca de tiempo, el código de la máquina (proceso) y el número de serie.
Según el algoritmo de Twitter Snowflake, la longitud es de 64 bits; la composición de 64 bits es la siguiente:
-
Bit de signo de 1 bit.
-
Desplazamiento de marca de tiempo de 41 bits desde 2016.11.01 (datos publicados de clave primaria distribuida de Sharding-JDBC) hasta ahora.
-
Id. De proceso de trabajador de 10 bits.
-
Desplazamiento de incremento automático de 12 bits en un milésimo.
| Bits | nombre de pila | Descripción |
|---|---|---|
| 1 | Bit de signo | 0, generalmente no se usa |
| 41 | Marca de tiempo | Preciso al número de milisegundos, admite 2 ^ 41 /365/24/60/60/1000=69,7 años |
| 10 | Número de proceso de trabajo | Soporta 1024 procesos |
| 12 | número de serie | Incremento de 0 cada milisegundo, admite 4096 números |
Los ID generados por el copo de nieve están ordenados por incrementos de tiempo en su conjunto y suman exactamente 64 bits, que es un tipo Long (la longitud es de hasta 19 cuando se convierte en una cadena). Y no habrá colisiones de ID en todo el sistema distribuido (diferenciado por centro de datos y workerId), y la eficiencia del trabajo es alta. Snowflake puede generar 260.000 ID por segundo después de la prueba.
3. Características (autocrecientes, ordenadas, adecuadas para escenarios distribuidos)
- Posición de tiempo: se puede ordenar según el tiempo, lo que ayuda a mejorar la velocidad de la consulta.
- Bit de ID de máquina: es adecuado para identificar cada nodo de varios nodos en un entorno distribuido. La longitud de bits de la máquina se puede dividir en 10 bits de acuerdo con la cantidad de nodos y las condiciones de implementación, como dividir 5 bits para representar el bit de proceso.
- Bit de número de serie: es una serie de ID de aumento automático, que pueden admitir que el mismo nodo genere varios números de serie de ID en el mismo milisegundo. El número de serie de conteo de 12 dígitos admite que cada nodo genere 4096 números de serie de ID cada milisegundo
El algoritmo del copo de nieve se puede modificar según la situación del proyecto y sus propias necesidades.

Tres, las deficiencias del algoritmo del copo de nieve.
- Muy dependiente del tiempo,
- Si se vuelve a marcar el reloj, se generará un ID duplicado
El ID distribuido de sharding-jdbc adopta el algoritmo de copo de nieve de código abierto de Twitter y no necesita depender de ningún componente de terceros, por lo que su escalabilidad y capacidad de mantenimiento se simplifican enormemente;
Pero la falla del algoritmo del copo de nieve (que depende en gran medida del tiempo, si el reloj se marca hacia atrás, se generará una ID duplicada), sharding-jdbc no proporciona una solución, si el usuario quiere fortalecerlo, necesita expandirse por sí mismo;
4.2 Código fuente de SnowflakeShardingKeyGenerator
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.shardingsphere.core.strategy.keygen;
import com.google.common.base.Preconditions;
import lombok.Getter;
import lombok.Setter;
import lombok.SneakyThrows;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Calendar;
import java.util.Properties;
/**
* Snowflake distributed primary key generator.
*
* <p>
* Use snowflake algorithm. Length is 64 bit.
* </p>
*
* <pre>
* 1bit sign bit.
* 41bits timestamp offset from 2016.11.01(ShardingSphere distributed primary key published data) to now.
* 10bits worker process id.
* 12bits auto increment offset in one mills
* </pre>
*
* <p>
* Call @{@code SnowflakeShardingKeyGenerator.setWorkerId} to set worker id, default value is 0.
* </p>
*
* <p>
* Call @{@code SnowflakeShardingKeyGenerator.setMaxTolerateTimeDifferenceMilliseconds} to set max tolerate time difference milliseconds, default value is 0.
* </p>
*/
public final class SnowflakeShardingKeyGenerator implements ShardingKeyGenerator {
public static final long EPOCH;
private static final long SEQUENCE_BITS = 12L;
private static final long WORKER_ID_BITS = 10L;
private static final long SEQUENCE_MASK = (1 << SEQUENCE_BITS) - 1;
private static final long WORKER_ID_LEFT_SHIFT_BITS = SEQUENCE_BITS;
private static final long TIMESTAMP_LEFT_SHIFT_BITS = WORKER_ID_LEFT_SHIFT_BITS + WORKER_ID_BITS;
private static final long WORKER_ID_MAX_VALUE = 1L << WORKER_ID_BITS;
private static final long WORKER_ID = 0;
private static final int DEFAULT_VIBRATION_VALUE = 1;
private static final int MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS = 10;
@Setter
private static TimeService timeService = new TimeService();
@Getter
@Setter
private Properties properties = new Properties();
private int sequenceOffset = -1;
private long sequence;
private long lastMilliseconds;
static {
Calendar calendar = Calendar.getInstance();
calendar.set(2016, Calendar.NOVEMBER, 1);
calendar.set(Calendar.HOUR_OF_DAY, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
EPOCH = calendar.getTimeInMillis();
}
@Override
public String getType() {
return "SNOWFLAKE";
}
@Override
public synchronized Comparable<?> generateKey() {
long currentMilliseconds = timeService.getCurrentMillis();
if (waitTolerateTimeDifferenceIfNeed(currentMilliseconds)) {
currentMilliseconds = timeService.getCurrentMillis();
}
if (lastMilliseconds == currentMilliseconds) {
if (0L == (sequence = (sequence + 1) & SEQUENCE_MASK)) {
currentMilliseconds = waitUntilNextTime(currentMilliseconds);
}
} else {
vibrateSequenceOffset();
sequence = sequenceOffset;
}
lastMilliseconds = currentMilliseconds;
return ((currentMilliseconds - EPOCH) << TIMESTAMP_LEFT_SHIFT_BITS) | (getWorkerId() << WORKER_ID_LEFT_SHIFT_BITS) | sequence;
}
@SneakyThrows
private boolean waitTolerateTimeDifferenceIfNeed(final long currentMilliseconds) {
if (lastMilliseconds <= currentMilliseconds) {
return false;
}
long timeDifferenceMilliseconds = lastMilliseconds - currentMilliseconds;
Preconditions.checkState(timeDifferenceMilliseconds < getMaxTolerateTimeDifferenceMilliseconds(),
"Clock is moving backwards, last time is %d milliseconds, current time is %d milliseconds", lastMilliseconds, currentMilliseconds);
Thread.sleep(timeDifferenceMilliseconds);
return true;
}
//取得节点的ID
private long getWorkerId() {
long result = Long.valueOf(properties.getProperty("worker.id", String.valueOf(WORKER_ID)));
Preconditions.checkArgument(result >= 0L && result < WORKER_ID_MAX_VALUE);
return result;
}
private int getMaxVibrationOffset() {
int result = Integer.parseInt(properties.getProperty("max.vibration.offset", String.valueOf(DEFAULT_VIBRATION_VALUE)));
Preconditions.checkArgument(result >= 0 && result <= SEQUENCE_MASK, "Illegal max vibration offset");
return result;
}
private int getMaxTolerateTimeDifferenceMilliseconds() {
return Integer.valueOf(properties.getProperty("max.tolerate.time.difference.milliseconds", String.valueOf(MAX_TOLERATE_TIME_DIFFERENCE_MILLISECONDS)));
}
private long waitUntilNextTime(final long lastTime) {
long result = timeService.getCurrentMillis();
while (result <= lastTime) {
result = timeService.getCurrentMillis();
}
return result;
}
private void vibrateSequenceOffset() {
sequenceOffset = sequenceOffset >= getMaxVibrationOffset() ? 0 : sequenceOffset + 1;
}
}
EPOCH = calendar.getTimeInMillis (); Calcule el número de milisegundos desde cero en 2016/11/01.
Lógica de implementación generateKey ()
Verifique que la hora actual sea menor o igual que la marca de tiempo del último número generado para evitar la sincronización del reloj del servidor, que puede causar retrocesos de tiempo, lo que resulta en números duplicados para
obtener números de serie. Cuando se pueda obtener la marca de tiempo actual desde el incremento hasta el valor máximo, llame a #waitUntilNextTime () para obtener el siguiente milisegundo.
Establezca la marca de tiempo del número de última generación, que se utiliza para verificar la reversión de tiempo.
Número de generación de operación de bit
De acuerdo con el código, si solo se genera una identificación en un milisegundo, entonces el número de serie de 12 bits es todo 0, por lo que la identificación generada en este caso es par.
4.3 ¿El problema de configuración de workerId (nodo)?
Pregunta: El algoritmo Snowflake debe garantizar que cada nodo distribuido tenga un workerId (nodo) único. ¿Cómo resolver la asignación de números de proceso de trabajador?
La implementación del algoritmo de Twitter Snowflake es relativamente simple y fácil de entender ¿Qué es más problemático es cómo resolver la asignación de números de proceso de trabajo? ¿Cómo garantizar que el mundo sea único?
解决方案:
可以通过IP、主机名称等信息,生成workerId(节点Id)。还可以通过 Zookeeper、Consul、Etcd 等提供分布式配置功能的中间件。
Debido al algoritmo de copo de nieve de ShardingJdbc, no es tan completo. La estrategia de solución relativamente simple y grosera es:
-
En proyectos de producción, se puede implementar un generador de ID personalizado basado en la biblioteca Snow ID muy madura y de alto rendimiento de Baidu.
-
En el proyecto de aprendizaje, puede implementar un generador de ID personalizado basado en la biblioteca de ID de copo de nieve de tipo de aprendizaje de Crazy Maker Circle.
referencias:
http://shardingsphere.io/document/current/cn/overview/
https://blog.csdn.net/tianyaleixiaowu/article/details/70242971
https://blog.csdn.net/clypm/article/details/54378502
https://blog.csdn.net/u011116672/article/details/78374724
https://blog.csdn.net/feelwing1314/article/details/80237178
Serie de entornos de alto desarrollo concurrente: entorno springcloud
| Componente | dirección de enlace |
|---|---|
| Instalación y pit pit de la máquina virtual de Windows centos | vagrant + java + springcloud + redis + descarga del espejo del guardián del zoológico (y producción detallada)) |
| Instalación de centos mysql y pit pit | notas de centos mysql (contiene el espejo vagabundo de mysql) |
| Instalación de Linux kafka y pit pit | Integración de Kafka springboot (o springcloud) |
| Instalación de Linux openresty | Instalación de Linux openresty |
| [Obligatorio] Instalación de Linux Redis (con video) | Instalación de Linux Redis (con video) |
| [Obligatorio] Instalación de Linux Zookeeper (con video) | Instalación de Linux Zookeeper, con video |
| Instalación de Windows Redis (con video) | Instalación de Windows Redis (con video) |
| Instalación fuera de línea de RabbitMQ (con video) | Instalación fuera de línea de RabbitMQ (con video) |
| Instalación de ElasticSearch, con video | Instalación de ElasticSearch, con video |
| Instalación de Nacos (con video) | Instalación de Nacos (con video) |
| [Obligatorio] Eureka | Comenzando con Eureka con video |
| [Obligatorio] Introducción a Springcloud Config, con video | Comenzando con Springcloud Config con video |
| [Obligatorio] Empaquetado y puesta en marcha del andamio SpringCloud | Empaquetado y puesta en marcha de andamios SpringCloud |
| Inicio automático de Linux, animación suspendida, inicio automático, inicio automático temporizado | Animación suspendida de inicio automático de Linux |
Volver a ◀ Círculo de creadores de locos ▶
Comunidad de investigación de alta concurrencia de Crazy Maker Circle-Java, abre la puerta a grandes fábricas para todos