Este proyecto toma los datos de las películas como tema y toma la recopilación, el procesamiento, el análisis y la visualización de datos como el proceso del proyecto, que puede realizar el procesamiento y cálculo fuera de línea de millones de datos de películas.
Enlace del proyecto: https://github.com/GoAlers/Bigdata-movie
Entorno de desarrollo: IDEA + Pycharm + Centos7.0 + hadoop2.8 + hive2.3.0 + hbase2.0.0 + mysql5.7 + sqoop
- 1. Responsable de la instalación y despliegue de la plataforma de big data Hadoop, configuración básica, optimización de parámetros y despliegue y gestión de componentes relacionados.
- 2. Construya una plataforma de big data distribuida, responsable del rastreador para recopilar datos masivos de películas y limpieza de datos, hacer nubes de mapas de palabras, gráficos de matplotlib y visualización de datos de Echarts.
- 3. Use Python / Java para escribir programación MR para calcular estadísticas de películas específicas sin conexión, use la herramienta sqoop para transferir datos y use hive para analizar datos relacionados.
- 4. Utilice algoritmos de aprendizaje automático y bibliotecas relacionadas para realizar análisis de opinión de reseñas de películas y predecir el rango de calificación de los usuarios y la taquilla, y contar el topN de la puntuación total.
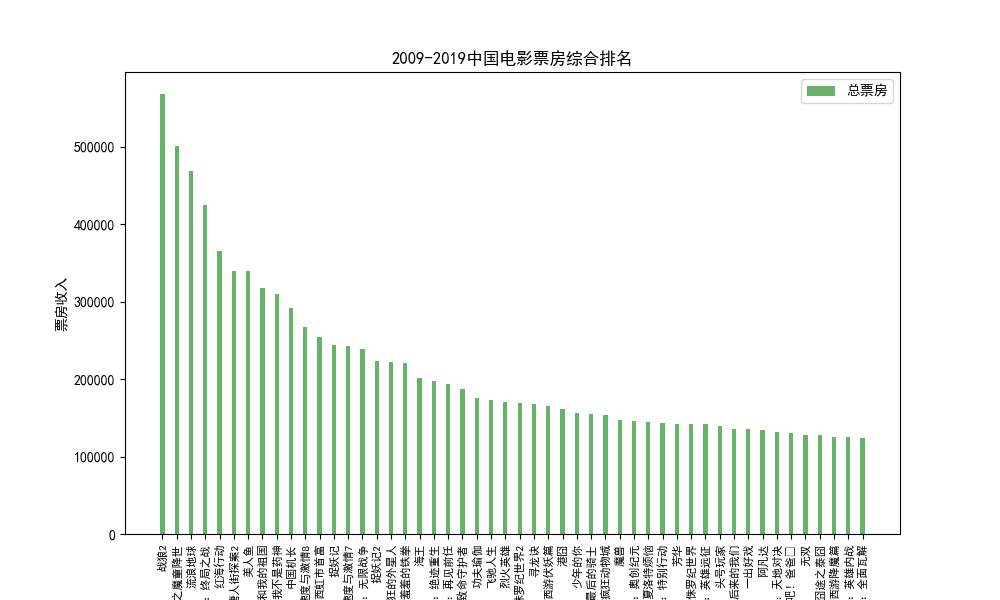
1. Recopilación de datos (pachong.py), limpieza: recopile datos de películas de Douban, obtenga la clasificación de los ingresos totales de la taquilla de películas (tome el top 20), elimine palabras redundantes y vacías, use la biblioteca PyMysql de Python para conectarse a la base de datos local de Mysql e importarlo La tabla de películas puede guardar datos localmente para la visualización visual de datos, o importar los datos a la herramienta de almacenamiento de datos Hive de big data para análisis de big data.
| Ordenar | Nombre de pelicula | Tipos de | Taquilla total (diez mil) | Por juego | Fecha de lanzamiento |
| 1 | Guerrero lobo 2 | acción | 567928 | 38 | 2017/7/27 |
| 2 | El chico demonio de Nezha llega al mundo | Animación | 501324 | 24 | 2019/7/26 |
| 3 | Tierra errante | Ciencia ficción | 468433 | 29 | 2019/2/5 |
| 4 | Vengadores 4: Endgame | acción | 425024 | 23 | 24/4/2019 |
| 5 | Operación Mar Rojo | acción | 365079 | 33 | 2018/2/16 |
| 6 | Detective Chinatown 2 | comedia | 339769 | 39 | 2018/2/16 |
| 7 | Sirena | comedia | 339211 | 44 | 2016/2/8 |
| 8 | Yo y mi patria | Trama | 317152 | 36 | 2019/9/30 |
| 9 | No soy un dios de la medicina | Trama | 309996 | 27 | 2018/7/5 |
| 10 | Capitán chino | Trama | 291229 | 27 | 2019/9/30 |
2. Visualización de datos: la visualización de datos puede hacer que los datos sean más intuitivos y más propicios para el análisis. Se puede decir que la tecnología de visualización es el contenido más importante del análisis y la minería de datos. Como proyecto de código abierto basado en el lenguaje Python, Matplotlib tiene como objetivo proporcionar un paquete de trazado de datos para Python para lograr funciones de trazado profesionales y ricas.
(1) Clasificación de taquilla de películas
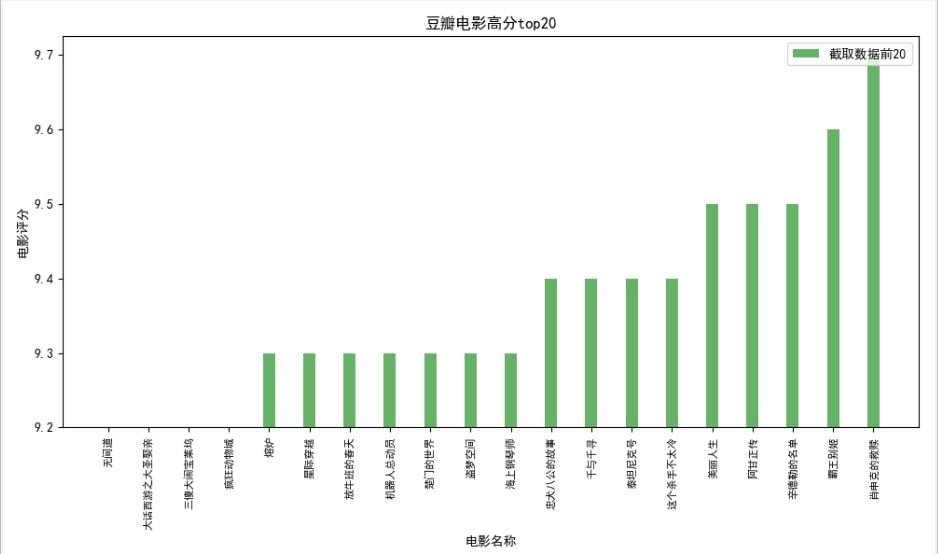
(2) Clasificación de clasificación de películas douanscore.py
(3) Echarts películas lanzadas recientemente
Echarts se utiliza principalmente para visualización y visualización de datos. Es una biblioteca de JavaScript de código abierto que es compatible con la mayoría de los navegadores existentes. En Python, Echarts está empaquetado en Pyecharts, una biblioteca de herramientas de visualización de datos. Proporciona gráficos de visualización de datos intuitivos, ricos y personalizables, incluidos gráficos de líneas convencionales, histogramas, gráficos de dispersión y gráficos circulares.

(4) Información de comentario breve para la película "囧 Mom"
La película del día de Año Nuevo "囧 Mom" se estrenó en Internet. Hasta ahora, su película Douban ha obtenido 6.0 puntos. El análisis del caso se lleva a cabo a través del comentario breve popular de Douban sobre la película "囧 Mom", y el rastreo de datos es se lleva a cabo con el software Octopus como herramienta de recopilación de datos. Los campos recopilados incluyen el nombre de usuario, la calificación, la cantidad de me gusta y el contenido de los comentarios, y utilizan expresiones regulares para hacer coincidir las etiquetas de los campos. Según el sistema de estrellas de calificación proporcionado por Douban Movies, cinco Se muestran como recomendado, recomendado, correcto, deficiente y muy deficiente. Calificación, la puntuación completa es de cinco estrellas y el formato de datos es el siguiente:
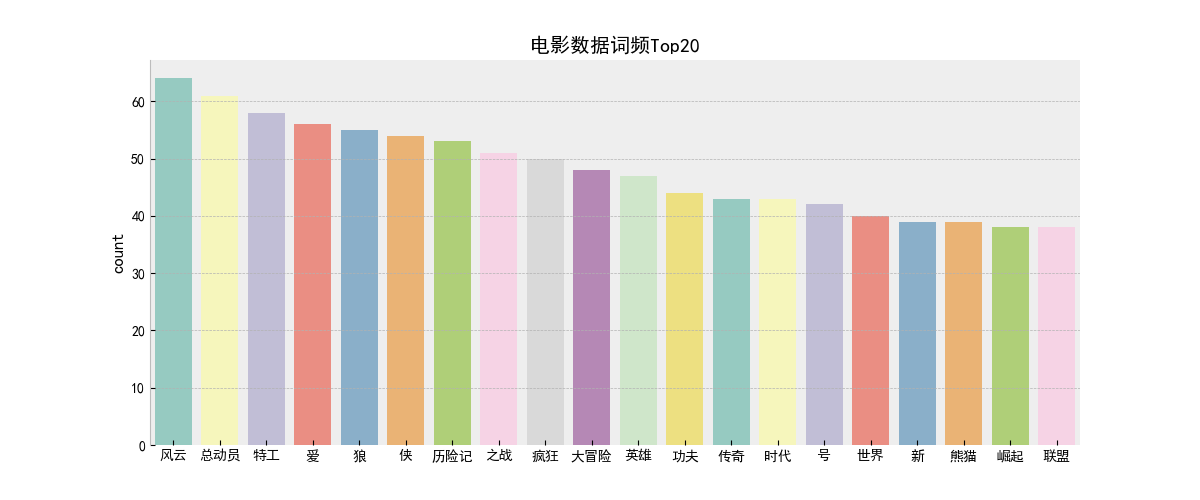
(7) Estadísticas de frecuencia de palabras de Python wordcount.py
3. Análisis de macrodatos:
La parte más importante del procesamiento de big data es el análisis de datos, que generalmente se divide en dos tipos: procesamiento por lotes y procesamiento de flujo. El procesamiento por lotes es el procesamiento unificado de datos masivos fuera de línea dentro de un período de tiempo, correspondiente al marco de procesamiento Mapreduce, Spark, etc.; El procesamiento de flujo es para el procesamiento dinámico de datos en tiempo real, es decir, procesar los datos mientras se reciben, correspondiente Los marcos de procesamiento incluyen Storm, Spark Streaming, Flink, etc. Este artículo se centra en el cálculo sin conexión e introduce el análisis de datos de películas.
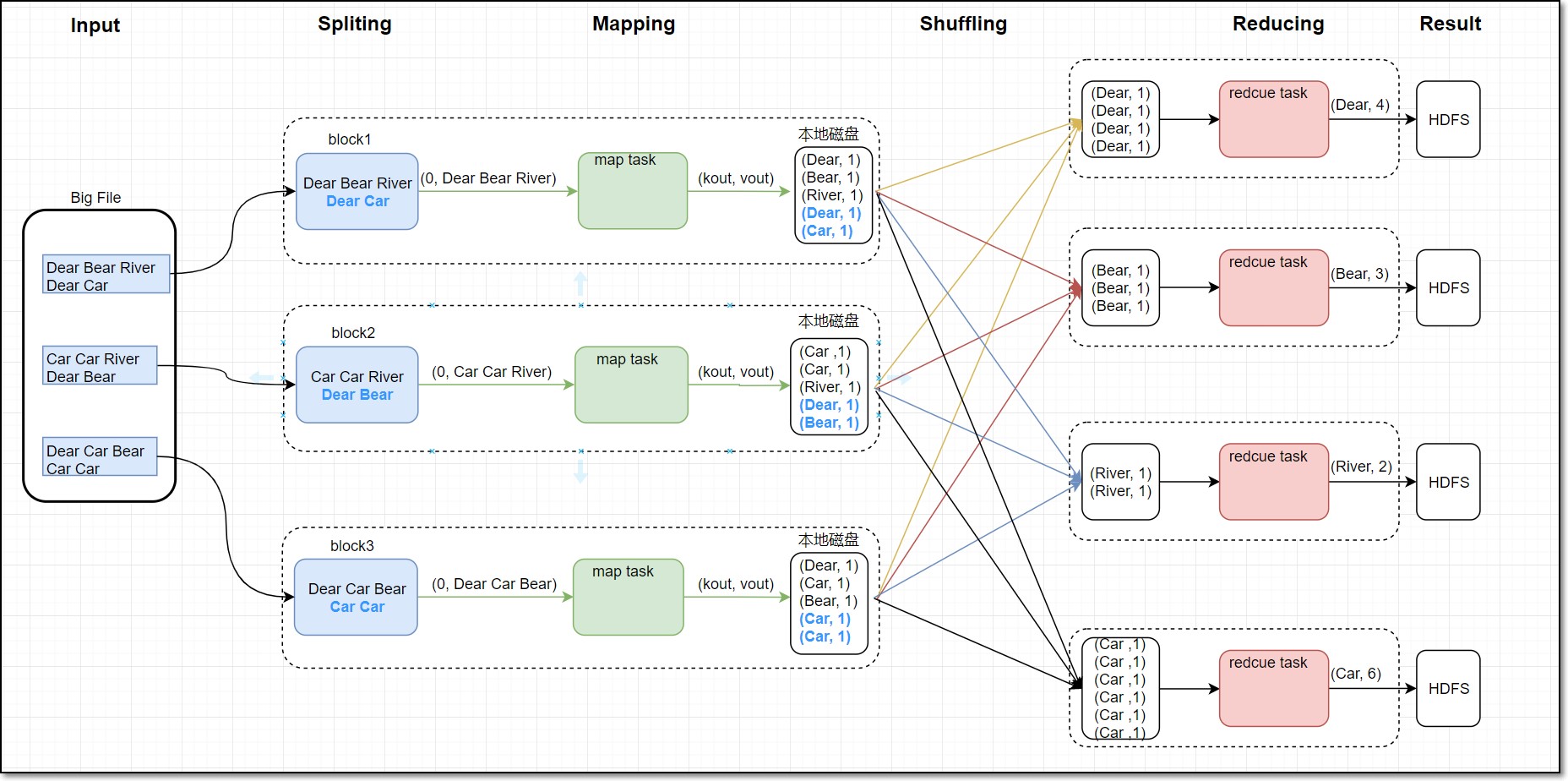
(1) Cálculo sin conexión de Mapreduce (archivo mapreduce_hive)
La programación de estadísticas de frecuencia de palabras de Mapreduce utiliza principalmente la idea del recuento de palabras y realiza estadísticas de frecuencia de palabras dividiendo palabras y oraciones de acuerdo con los formatos prescritos. Los datos estadísticos son la información de lanzamiento de películas históricas. La etapa del mapa es principalmente responsable de las estadísticas de segmentación de palabras. La etapa del mapa asigna cada cadena en un par de clave y valor, y asigna las palabras en (palabras, 1) forma por fila. El Shuffle Los resultados se particionan y ordenan, y luego se combinan y escriben en el disco de acuerdo con la salida de la misma partición. Finalmente, se obtiene un archivo particionado. Finalmente, la etapa de reducción resumirá y contará el número de cada palabra, y los datos finalmente se almacenarán en HDFS. Este artículo toma las palabras de películas como objetos estadísticos para comprender la función de las estadísticas de frecuencia de palabras. El diagrama de flujo de las estadísticas de frecuencia de palabras es el siguiente:
Código de etapa del mapa:
importar sys
para la línea en sys.stdin:
ss = line.strip (). split ('')
para s en ss:
if s.strip ()! = "":
print "% s \ t% s"% (s, 1 )
Reducir el código de fase:
import sys
current_word = Ninguno
count_pool = []
sum = 0
para línea en sys.stdin:
word, val = line.strip (). split ('\ t')
if current_word == None:
current_word = word
if current_word! = word:
for count in count_pool:
sum + = count
print " % s \ t% s "% (current_word, sum)
current_word = word
count_pool = []
sum = 0
count_pool.append (int (val))
para contar en count_pool:
sum + = count
print"% s \ t% s " % (palabra_actual, str (suma))
(2) almacén de datos de Hive
Hive es una herramienta de almacenamiento de datos basada en Hadoop, que se utiliza principalmente para resolver las estadísticas de datos de registros estructurados masivos. Puede mapear archivos de datos estructurados en una tabla y consultar y analizar estadísticamente los datos en la tabla a través de declaraciones similares a SQL. Utilice la herramienta de transferencia de datos Sqoop para importar información de la base de datos Mysql al almacén de datos de Hive.
El uso de Hive puede realizar análisis de datos masivos y admite funciones personalizadas, eliminando la necesidad de programación MapReduce. Este artículo realiza estadísticas sobre los datos históricos de películas de Douban. Una vez que se limpian los datos, se eliminan los valores nulos y los elementos redundantes, se obtienen más de 100.000 datos de películas. Algunos formatos de datos son los siguientes:
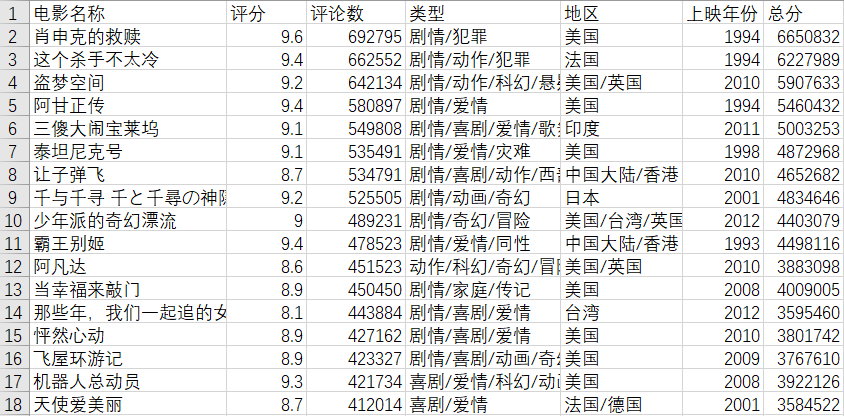
(3) Tipo de película y estadísticas de taquilla movietype.py
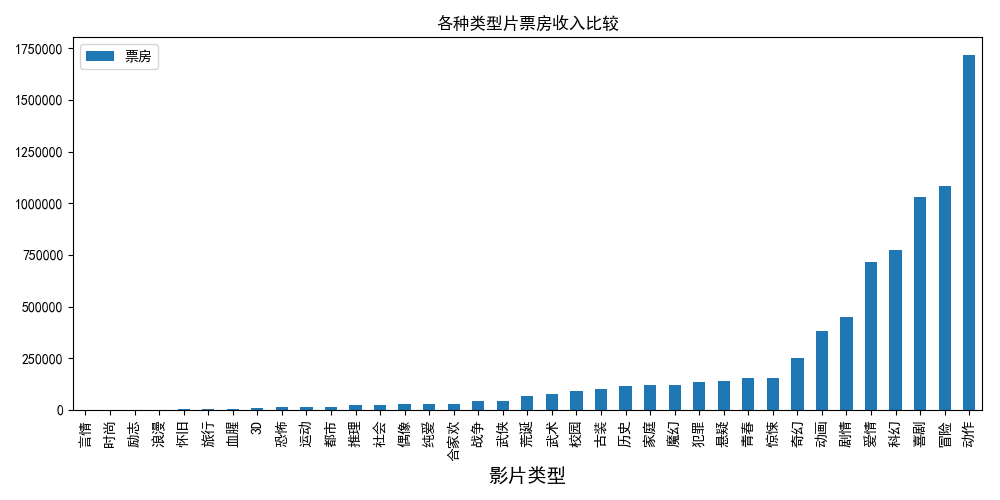
(5) La relación entre el director y el tipo de película director.py
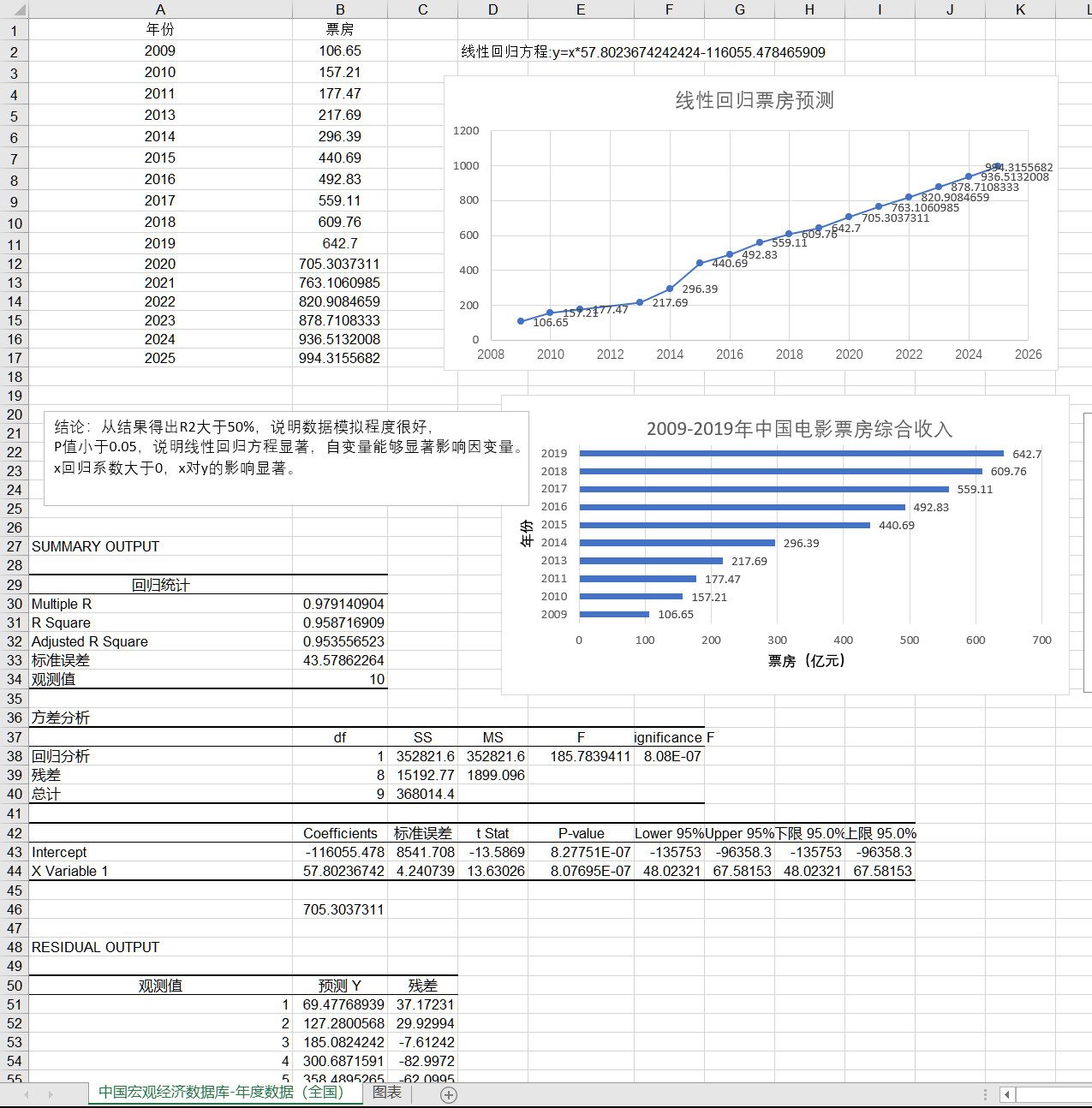
(6) Previsión de taquilla de películas (previsión de taquilla electrónica.xls)
(7) Predicción de partituras de películas scorepredict.py
Utilice la biblioteca sklearn de aprendizaje automático para crear un modelo de regresión, seleccione al azar a 5 usuarios para calcular la puntuación para predecir el rango de calificación del usuario para una nueva película y generar las calificaciones máxima, mínima y promedio.
#encoding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
from sklearn.linear_model import LinearRegression
#Drawing part data = pd.read_csv ('lianxi / film-csv.txt', encoding = 'utf-8', delimiter = ';')
#Read file data = data.iloc [:,: - 1] # Eliminar los datos ilegales en el archivo
data = data.drop (0) .drop_duplicates (). reset_index (). drop ('index', axis = 1) #Porque la primera línea elimina los datos vacíos y restablece el índice
# print data
t = [] # Divida el tipo de película de acuerdo con múltiples divisores
para i en el rango (len (datos)):
a = re.split (u '/ | / |, |, | |', datos [u'Movie Type ' ] [i])
para j en a:
t.append (j)
t = set (t) #Eliminar el tipo repetido
tt = []
para i en t: #Eliminar el tipo no estándar para obtener todos los existentes El tipo de
si (len (i) <= 2) | (i == u '
合家欢'): tt.append (i)
#
ID de predicción de puntuación = [1050,1114,1048,1488,1102] # ID de cinco usuarios
data1 = pd.read_csv ('lianxi / score.log', delimiter = ',', encoding = 'utf-8', header = 0, names = [u'movie name ', u'userid', u'score '])
data1 = data1 [data1 [u'userid']. Isin (id)] #Eliminar cinco datos relacionados con el usuario
data1 [u'nombre de la película '] = data1 [u'nombre de la película']. str.strip () #Eliminar el espacio del nombre de la película
all = [] #Se usa para guardar los resultados
de la predicción para k en rango (len (id )):
#Ciclo de cinco modelos para la predicción dfp1 = data1 [data1 [u'userid '] == id [k]]. Reset_index (). Drop (' index ', axis = 1)
datamerge = pd.merge (data , dfp1, on = u '电影名') #Utilizando merge para fusionar los detalles de la película con la nueva calificación de usuario
lst = []
lsd = []
lsr = []
for i in range (len (datamerge)): #Separe el tipo de película Y el director y la taquilla correspondiente
para j en tt:
if j in datamerge [u'movie type '] [i]:
d = re.split (u', |, | / | ', datamerge [u' director '] [i])
para k en d:
lsd.append (k.replace (u' ', u' '))
lst.append (j.replace (u' ', u' '))
lsr.append ( datamerge [u 'puntuación'] [i])
lsd1 = list (set (lsd))
for i in range (len (lsd1)): # Convierte el tipo de película y la taquilla en una cantidad continua para el entrenamiento de la máquina
para j en rango (len (lsd)):
si lsd1 [i] == lsd [j]:
lsd [j] = i + 1
para i en rango (len (tt)):
para j en rango (len (lst )):
si tt [i] == lst [j]:
lst [j] = i + 1
lsd = pd.DataFrame (lsd, columnas = [u '导演'])
lst = pd.DataFrame (lst, columnas = [u '影片 类型'])
lsr = pd.DataFrame (lsr, columnas = [u '评分'])
a = pd.concat ([lsd, lst, lsr], axis = 1)
imprimir (a)
trainx = a.iloc [:, 0: 2] # Tipo de película y director como cantidades de funciones
trainy = a.iloc [:, 2: 3] # Puntuación como valor de muestra
l =
LinearRegression ( ) # Modelado l.fit (trainx, trainy) # entrenamiento
anstest = pd.DataFrame ([[5,10]], columnas = [u'director ',
u'film type']) ans = l.predict (anstest)
#predict all.append (ans [0] [0] ) #Obtener el resultado
print (el valor máximo de u'score es '+'%. 2f '% max (all))
#output print (el valor mínimo de u'score es' + '%. 2f'% min (all))
print (El valor medio de u'score es '+'%. 2f '% np.median (all))
print (El valor medio de u'score es' + '%. 2f'% np.mean (all))