Como desarrollo de un servicio de fondo, estamos lidiando con la base de datos todos los días en nuestro trabajo diario, hemos estado realizando varias operaciones CRUD y usaremos el pool de conexiones de la base de datos. Según el historial de desarrollo, existen los siguientes tipos de grupos de conexiones de bases de datos bien conocidos en la industria: c3p0, DBCP, Tomcat JDBC Connection Pool, Druid, etc., pero el más popular es HiKariCP recientemente.
HiKariCP es conocido como el grupo de conexiones de bases de datos más rápido de la industria. Desde que SpringBoot 2.0 lo adoptó como el grupo de conexiones de bases de datos predeterminado, su impulso de desarrollo ha sido imparable. ¿Por qué es tan rápido? Hoy nos centraremos en las razones.
Uno, ¿qué es un grupo de conexiones de base de datos?
Antes de explicar HiKariCP, introduzcamos brevemente qué es un grupo de conexiones de base de datos (agrupación de conexiones de base de datos) y por qué hay un grupo de conexiones de base de datos.
Básicamente hablando, el grupo de conexiones de la base de datos, como nuestro grupo de subprocesos de uso común, es un recurso agrupado.Crea una cierta cantidad de objetos de conexión de la base de datos y los almacena en un área de memoria cuando se inicializa el programa. Permite que la aplicación reutilice una conexión de base de datos existente. Cuando se necesita ejecutar SQL, obtenemos una conexión directamente del grupo de conexiones en lugar de restablecer una conexión de base de datos. Cuando se ejecuta SQL, la conexión de base de datos no es verdadera. Turn desactivarlo, pero devolverlo al grupo de conexiones de la base de datos. Podemos controlar el número inicial de conexiones, conexión mínima, conexión máxima, tiempo de inactividad máximo y otros parámetros en el grupo de conexiones configurando los parámetros del grupo de conexiones para asegurar que el número de acceso a la base de datos esté dentro de un cierto rango controlable, Prevenir caídas del sistema y garantizar una buena experiencia de usuario. El diagrama del grupo de conexiones de la base de datos es el siguiente:
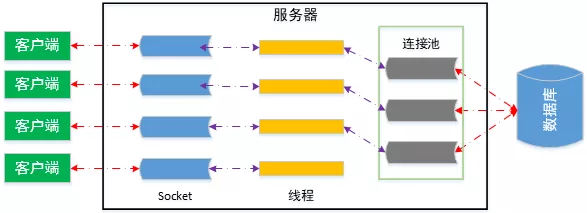
Por lo tanto, la función principal de usar el grupo de conexiones de base de datos es evitar la creación y destrucción frecuentes de conexiones de base de datos y ahorrar gastos generales del sistema. Debido a que las conexiones a la base de datos son limitadas y costosas, crear y liberar conexiones a la base de datos requiere mucho tiempo. Este tipo de operaciones frecuentes requerirán una gran sobrecarga de rendimiento, lo que provocará una desaceleración en la velocidad de respuesta del sitio web e incluso fallas del servidor.
2. Análisis comparativo de grupos de conexiones de bases de datos comunes
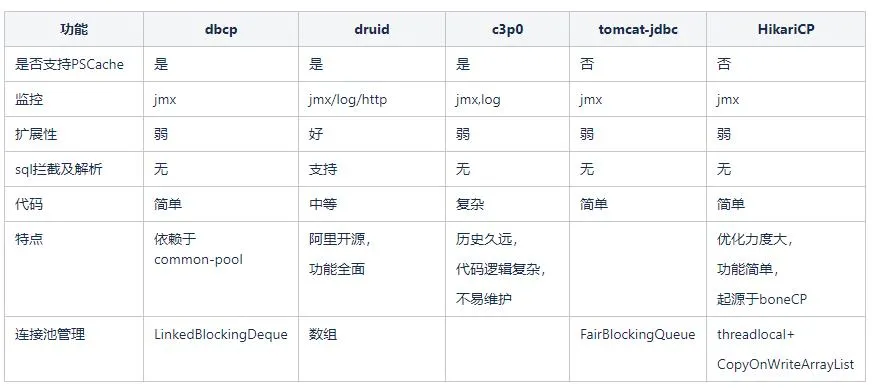
Aquí hay un resumen detallado de la comparación de varias funciones de grupos de conexiones de bases de datos comunes. Nos enfocamos en analizar la corriente principal actual de Alibaba Druid y HikariCP. HikariCP es completamente superior en rendimiento a los grupos de conexiones de Druid. El rendimiento de Druid es ligeramente peor debido al mecanismo de bloqueo diferente, y Druid proporciona funciones más ricas, que incluyen monitoreo, interceptación y análisis de SQL. El enfoque de los dos es diferente. HikariCP persigue el máximo rendimiento.
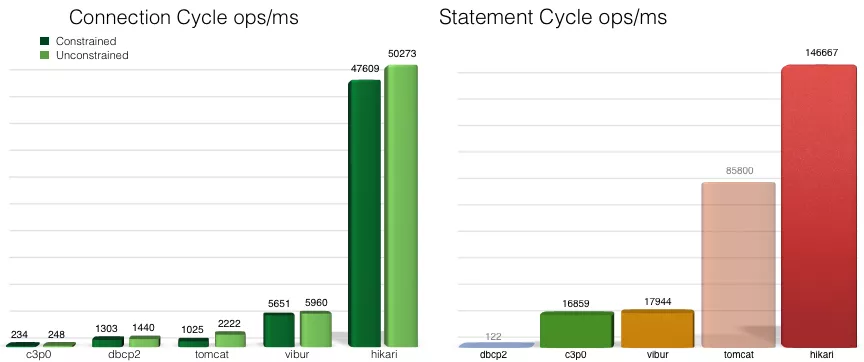
El siguiente es el cuadro de comparación de rendimiento proporcionado por el sitio web oficial. En términos de rendimiento, el orden de los cinco grupos de conexiones de base de datos es el siguiente: HikariCP> druid> tomcat-jdbc> dbcp> c3p0:
3. Introducción al grupo de conexiones de la base de datos HikariCP
HikariCP afirma ser el mejor grupo de conexiones de base de datos de la historia, y SpringBoot 2.0 lo establece como el grupo de conexiones de origen de datos predeterminado. En comparación con otros grupos de conexiones, Hikari tiene un rendimiento mucho mayor. Entonces, ¿cómo se hace? Al ver la introducción del sitio web oficial de HikariCP, la optimización de HikariCP se resume de la siguiente manera:
1. Optimización del código de bytes: código optimizado, la cantidad de código de bytes después de la compilación es muy pequeña, de modo que la memoria caché de la CPU puede cargar más código de programa;
HikariCP también ha realizado grandes esfuerzos para optimizar y agilizar el código de bytes, utilizando un código de bytes de Java de terceros para modificar la biblioteca de clases Javassist para generar un proxy dinámico delegado. La implementación del proxy dinámico está en la clase ProxyFactory, que es más rápida, en comparación con JDK Proxy Se genera menos código de bytes y se simplifica una gran cantidad de código de bytes innecesario.
2. Optimice el proxy y el interceptor: reduzca el código, por ejemplo, el proxy Statement de HikariCP tiene solo 100 líneas de código, solo una décima parte de BoneCP;
3. Tipo de matriz personalizada (FastStatementList) en lugar de ArrayList: evite la verificación de rango cada vez que get () de ArrayList, evite escanear de principio a fin al llamar a remove () (porque la característica de conexión es que la conexión se libera después de que se obtiene la conexión ) ;
4. Tipo de colección personalizado (ConcurrentBag): mejora la eficiencia de la lectura y escritura simultáneas;
5. Otras optimizaciones para defectos de BoneCP , como el estudio de llamadas a métodos que toman más de un intervalo de tiempo de CPU.
Por supuesto, como pool de conexiones de bases de datos, no se puede decir que pronto será respetado por los consumidores, además tiene muy buena robustez y estabilidad. Desde su lanzamiento en 15 años, HikariCP ha resistido la prueba del amplio mercado de aplicaciones y SpringBoot2.0 lo ha promovido con éxito como el grupo de conexiones de base de datos predeterminado.Es confiable en términos de confiabilidad. En segundo lugar, con su pequeña cantidad de código, pequeña cantidad de CPU y memoria, su tasa de ejecución es muy alta. Finalmente, básicamente no hay diferencia entre la configuración de Spring HikariCP y druid, y la migración es muy conveniente Estas son las razones por las que HikariCP es tan popular en la actualidad.
Bytecode optimizado, proxy e interceptor optimizados, tipo de matriz personalizada.
Cuatro, análisis del código fuente central de HikariCP
4.1 Cómo FastList optimiza los problemas de rendimiento
Primero, echemos un vistazo a los pasos para realizar la estandarización del funcionamiento de la base de datos:
Obtenga una conexión a la base de datos a través de la fuente de datos;
Crear declaración;
Ejecute SQL;
Obtenga resultados de ejecución de SQL a través de ResultSet;
Suelte el ResultSet;
Declaración de lanzamiento;
- Libere la conexión de la base de datos.
Todos los grupos de conexiones de bases de datos actualmente realizan operaciones de bases de datos estrictamente de acuerdo con este orden. Para evitar la operación de lanzamiento final, varios grupos de conexiones de bases de datos guardarán la declaración creada en la matriz ArrayList para asegurarse de que cuando se cierre la conexión, pueda desactivar todos Declaraciones en la matriz a su vez. Al procesar este paso, HiKariCP cree que hay espacio para la optimización en algunas operaciones de método de ArrayList, por lo que la implementación simplificada de la interfaz List está optimizada para varios métodos centrales en la interfaz List, y las otras partes son básicamente las mismas que ArrayList.
El primero es el método get (). ArrayList realizará rangeCheck cada vez que se llame al método get () para verificar si el índice está fuera de rango. Esta verificación se elimina en la implementación de FastList porque el grupo de conexiones de la base de datos cumple con la legalidad de el índice y puede garantizar que no excederá el límite. En este momento, rangeCheck es una sobrecarga de cálculo no válida, por lo que no hay necesidad de verificar fuera de los límites cada vez. La eliminación de operaciones no válidas frecuentes puede reducir significativamente el consumo de rendimiento.
- Operación FastList get ()
public T get(int index)
{
// ArrayList 在此多了范围检测 rangeCheck(index);
return elementData[index];
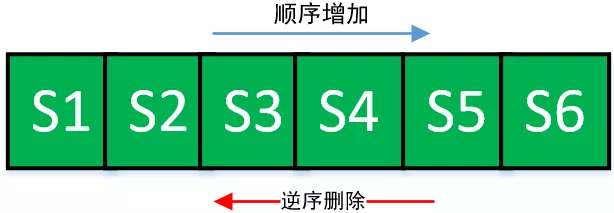
}El segundo es el método de eliminación. Al crear una declaración a través de conn.createStatement (), debe llamar al método add () de ArrayList para agregarlo a ArrayList. Esto no es un problema; pero al cerrar la declaración a través de stmt.close (), debe llamar al método remove () de ArrayList para eliminarlo de ArrayList, mientras que el método remove (Object) de ArrayList atraviesa la matriz desde el principio, mientras que FastList atraviesa desde el final de la matriz, por lo que es más eficiente. Suponga que una conexión crea 6 declaraciones en secuencia, a saber, S1, S2, S3, S4, S5, S6, y el orden de las declaraciones de cierre generalmente se invierte, de S6 a S1, mientras que el método remove (Object o) de ArrayList es el orden Búsqueda transversal, eliminación inversa y búsqueda secuencial, la eficiencia de la búsqueda es demasiado lenta. Por lo tanto, FastList lo optimiza y lo cambia a búsqueda inversa. El siguiente código es la operación de eliminación de datos implementada por FastList. En comparación con el código remove () de ArrayList, FastList elimina el rango de verificación y los pasos de atravesar elementos de verificación de principio a fin, y su rendimiento es más rápido.
- Operación de eliminación de FastList
public boolean remove(Object element)
{
// 删除操作使用逆序查找
for (int index = size - 1; index >= 0; index--) {
if (element == elementData[index]) {
final int numMoved = size - index - 1;
// 如果角标不是最后一个,复制一个新的数组结构
if (numMoved > 0) {
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
}
//如果角标是最后面的 直接初始化为null
elementData[--size] = null;
return true;
}
}
return false;
}A través del análisis del código fuente anterior, los puntos de optimización de FastList siguen siendo muy simples. En comparación con ArrayList, solo se eliminan los ajustes menores, como la comprobación del bastidor, la optimización de la expansión, etc. Al eliminar, la matriz se recorre para encontrar elementos y otros ajustes menores, a fin de lograr el máximo rendimiento. Por supuesto, la optimización de FastList de ArrayList, no podemos decir que ArrayList no sea buena. El llamado posicionamiento es diferente y la búsqueda es diferente. Como contenedor general, ArrayList es más seguro y estable. Verifica el rangeCheck antes de la operación y arroja excepciones directamente a las solicitudes ilegales, que está más en línea con el mecanismo de falla rápida , mientras que FastList persigue el máximo rendimiento.
Hablemos de ConcurrentBag, otra estructura de datos en HiKariCP, y veamos cómo mejora el rendimiento.
4.2 Análisis del principio de realización de ConcurrentBag
Los métodos de implementación del grupo de conexiones de bases de datos actuales se implementan principalmente con dos colas de bloqueo. Uno se usa para almacenar conexiones de base de datos inactivas en la cola, y el otro se usa para almacenar conexiones de base de datos ocupadas en la cola ocupada; cuando se obtiene una conexión, la conexión de base de datos inactiva se mueve de la cola inactiva a la cola ocupada, y cuando la conexión se cierra, la conexión de la base de datos pasa de ocupada a inactiva. Este esquema delega el problema de la concurrencia en la cola de bloqueo, que es simple de implementar, pero el rendimiento no es muy satisfactorio. Debido a que la cola de bloqueo en el SDK de Java se implementa con bloqueos, y la contención de bloqueos en escenarios de alta concurrencia tiene un gran impacto en el rendimiento.
HiKariCP no usa la cola de bloqueo en el SDK de Java, sino que implementa un contenedor concurrente llamado ConcurrentBag por sí mismo, que tiene un mejor rendimiento que LinkedBlockingQueue y LinkedTransferQueue en la implementación del grupo de conexiones (interacción de datos multiproceso).
Hay 4 atributos más críticos en ConcurrentBag, a saber: la cola compartida sharedList que se usa para almacenar todas las conexiones de la base de datos, el almacenamiento local de subprocesos threadList, el número de subprocesos que esperan conexiones de la base de datos, los servidores y la herramienta handoffQueue para asignar las conexiones de la base de datos. Entre ellos, handoffQueue usa SynchronousQueue proporcionado por Java SDK, y SynchronousQueue se usa principalmente para transferir datos entre subprocesos.
- Atributos clave en ConcurrentBag
// 存放共享元素,用于存储所有的数据库连接
private final CopyOnWriteArrayList<T> sharedList;
// 在 ThreadLocal 缓存线程本地的数据库连接,避免线程争用
private final ThreadLocal<List<Object>> threadList;
// 等待数据库连接的线程数
private final AtomicInteger waiters;
// 接力队列,用来分配数据库连接
private final SynchronousQueue<T> handoffQueue;ConcurrentBag garantiza que todos los recursos solo se pueden agregar a través del método add (). Cuando el grupo de subprocesos crea una conexión de base de datos, se agrega a ConcurrentBag llamando al método add () de ConcurrentBag y se elimina mediante el método remove (). La siguiente es la implementación específica del método add () y el método remove (). Al agregar, la conexión se agrega a la cola compartida sharedList. Si hay un hilo esperando una conexión de base de datos en este momento, entonces la conexión se asigna a la espera a través del hilo handoffQueue.
- Métodos add () y remove () de ConcurrentBag
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");
}
// 新添加的资源优先放入sharedList
sharedList.add(bagEntry);
// 当有等待资源的线程时,将资源交到等待线程 handoffQueue 后才返回
while (waiters.get() > 0 && bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) {
yield();
}
}
public boolean remove(final T bagEntry)
{
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
// 从sharedList中移出
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}Al mismo tiempo, ConcurrentBag obtiene una conexión de base de datos inactiva a través del método de préstamo () proporcionado, y recupera recursos mediante el método de retorno (). La lógica principal de préstamo () es:
- Compruebe si hay una conexión inactiva en el hilo de almacenamiento local threadList, si es así, devuelva una conexión inactiva;
- Si no hay una conexión inactiva en el almacenamiento local de subprocesos, obténgala de la cola compartida sharedList;
- Si no hay conexiones libres en la cola compartida, el subproceso solicitante debe esperar.
- Métodos de préstamo () y recompensa () de ConcurrentBag
// 该方法会从连接池中获取连接, 如果没有连接可用, 会一直等待timeout超时
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 首先查看线程本地资源threadList是否有空闲连接
final List<Object> list = threadList.get();
// 从后往前反向遍历是有好处的, 因为最后一次使用的连接, 空闲的可能性比较大, 之前的连接可能会被其他线程提前借走了
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// 线程本地存储中的连接也可以被窃取, 所以需要用CAS方法防止重复分配
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 当无可用本地化资源时,遍历全部资源,查看可用资源,并用CAS方法防止资源被重复分配
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 因为可能“抢走”了其他线程的资源,因此提醒包裹进行资源添加
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 当现有全部资源都在使用中时,等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将资源状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化处理
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
}Se puede decir que el método del préstamo () es el método más básico en todo el HikariCP. Es el método que eventualmente llamaremos cuando obtengamos una conexión del grupo de conexiones. Cabe señalar que el método de préstamo () solo proporciona referencias de objeto y no elimina el objeto, por lo tanto, debe ser devuelto a través del método return () al usarlo, de lo contrario fácilmente causará pérdidas de memoria. El método requite () primero cambia el estado de conexión de la base de datos a no utilizado, y luego verifica si hay un hilo en espera, y si lo hay, se asigna al hilo en espera; de lo contrario, la conexión de la base de datos se guarda en el almacenamiento local del hilo.
La implementación de ConcurrentBag utiliza el mecanismo de robo de colas para obtener elementos: primero intente obtener elementos pertenecientes al hilo actual de ThreadLocal para evitar la competencia de bloqueos, y si no hay elementos disponibles, vuelva a obtenerlos del CopyOnWriteArrayList compartido. Además, ThreadLocal y CopyOnWriteArrayList son variables miembro en ConcurrentBag y no se comparten entre subprocesos, lo que evita el uso compartido falso. Al mismo tiempo, debido a que la conexión en el almacenamiento local del subproceso puede ser robada por otros subprocesos, y la conexión inactiva se obtiene en la cola compartida, se necesita el método CAS para evitar la asignación duplicada.
Cinco, resumen
Como grupo de conexiones predeterminado de SpringBoot2.0, Hikari se usa actualmente ampliamente en la industria. Para la mayoría de las empresas, se puede acceder rápidamente y usar para lograr conexiones eficientes.
Referencia
Autor: equipo de vivo Game Technology