Lectura fantasma
¿Qué es la lectura fantasma?
por ejemplo:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Nota: El nivel de aislamiento de transacciones predeterminado de InnoDB es de lectura repetible, por lo que las partes que no se explican específicamente en este artículo se establecen en el nivel de aislamiento de lectura repetible.

Q3 El fenómeno de leer la línea id = 1 se llama "lectura fantasma". En otras palabras, la lectura fantasma se refiere a cuando una transacción consulta el mismo rango dos veces antes y después, la última consulta ve filas que la consulta anterior no vio. y:
- La lectura fantasma solo aparecerá en "lectura actual".
- La lectura fantasma solo se refiere a la "fila recién insertada".
Debido a que estas tres consultas se han agregado para actualizar, todas se leen actualmente. La regla de lectura actual es poder leer el último valor de todos los registros enviados. Además, las dos declaraciones de la sesión B y la sesión C se enviarán después de la ejecución, por lo que Q2 y Q3 deberían ver los efectos operativos de estas dos transacciones , y también ver que esto no contradice las reglas de visibilidad de la transacción .
¿Qué pasa con la lectura fantasma?
1. Problemas semánticos:
La sesión A declaró en T1, "Quiero bloquear todas las filas con d = 5, y no se permiten otras transacciones para realizar operaciones de lectura y escritura". De hecho, esta semántica se destruye.
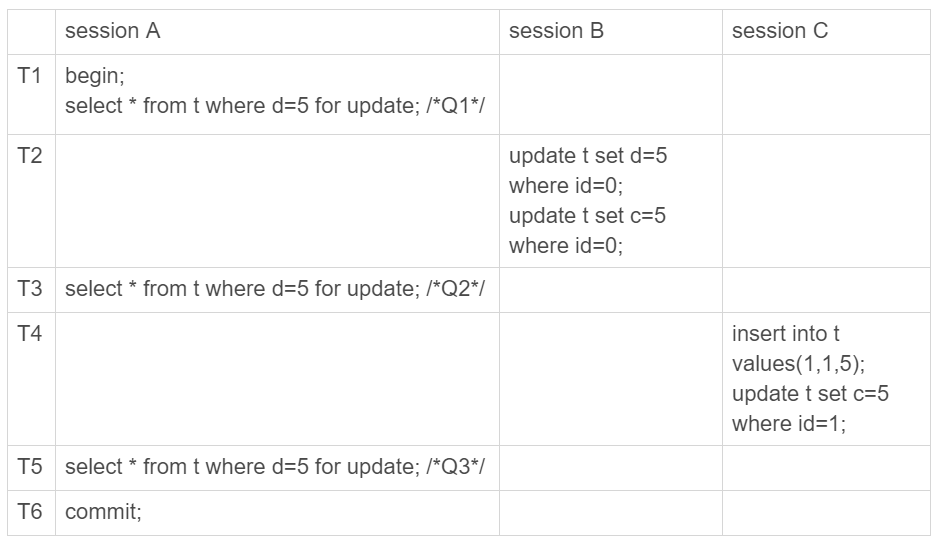
La segunda declaración de la sesión B y la sesión C destruye la declaración de bloqueo de la declaración Q1 en la sesión A para bloquear todas las d = 5 filas.
2. El problema de la coherencia de los datos:
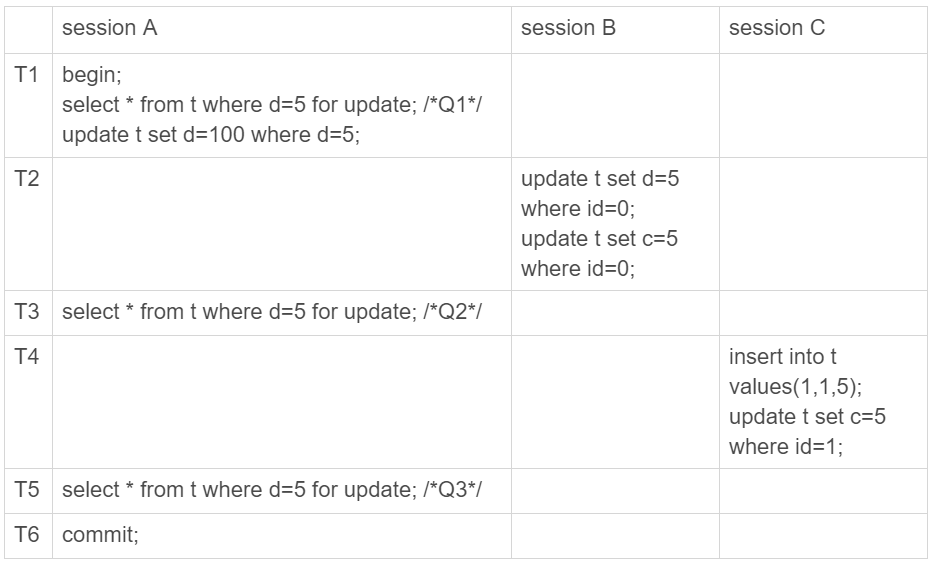
La semántica de bloqueo de la actualización es la misma que la de seleccionar ... para actualizar, por lo que es razonable agregar esta declaración de actualización en este momento. La sesión A declaró que "se debe agregar un candado a la declaración con d = 5" para actualizar los datos. La declaración de actualización recién agregada es modificar el valor d de la fila que considera bloqueada a 100 .
Veamos cuál será el resultado en la base de datos:
- Después de T1, la línea id = 5 se convierte en (5,5,100) Por supuesto, este resultado finalmente se envía oficialmente en T6;
- Después de T2, la línea id = 0 se convierte en (0,5,5);
- Después del tiempo T4, hay una fila más en la tabla (1,5,5);
- Las otras líneas no tienen nada que ver con esta secuencia de ejecución y permanecen sin cambios.
Mirándolo de esta manera, no hay nada de malo con los datos, pero echemos un vistazo al contenido del binlog en este momento:
- En T2, la transacción de la sesión B se confirma y se escriben dos declaraciones;
- En T4, la transacción de la sesión C se confirma y se escriben dos declaraciones;
- En T6, se confirma la transacción de la sesión A y la actualización de la instrucción t establece d = 100 donde se escribe d = 5.
Esta secuencia de oraciones, ya sea que obtenga la base de datos en espera para que se ejecute, o use binlog para clonar una base de datos más tarde, los resultados de estas tres líneas se convierten en (0,5,100), (1,5,100) y (5,5,100). Es decir, las dos filas id = 0 e id = 1 tienen inconsistencia de datos. Este problema es muy grave y no funcionará.
Cómo resolver la lectura fantasma:
Aquí, ya sabe, la razón de la lectura fantasma es que el bloqueo de fila solo puede bloquear la fila, pero para la acción de insertar un nuevo registro, el "espacio" entre los registros debe actualizarse. Por lo tanto, para resolver el problema de lectura fantasma, InnoDB tuvo que introducir un nuevo bloqueo, es decir, un bloqueo de espacio (Gap Lock).
Bloqueo de espacios
¿Qué es un bloqueo de espacio?
Como su nombre lo indica, gap lock bloquea el espacio entre dos valores.
Cuando ejecuta select * from t donde d = 5 para la actualización, no solo agregará bloqueos de fila a los 6 registros existentes en la base de datos , sino que también agregará 7 bloqueos de espacios . Esto asegura que no se puedan insertar nuevos registros.
todos sabemos. Los bloqueos de fila se dividen en bloqueos de lectura y bloqueos de escritura, exclusión de lectura y escritura, exclusión de escritura y escritura y conflictos entre bloqueos y bloqueos.
Sin embargo, el bloqueo de espacios es diferente. La relación conflictiva con el bloqueo de espacios es la operación de "insertar un registro en este espacio". No hay relación de conflicto entre bloqueos de brecha.

La sesión B no se bloqueará porque no hay registro de c = 7 en la tabla t . La sesión A agrega bloqueo de espacios (5,10). Y la sesión B también es un bloqueo de brecha agregado en esta brecha. Tienen el mismo objetivo, es decir, proteger esta brecha y no permitir que se inserten valores. Sin embargo, no existe ningún conflicto entre ellos.
siguiente bloqueo de tecla
El bloqueo de espacio y el bloqueo de fila se denominan en conjunto bloqueo de la siguiente tecla, y cada bloqueo de la siguiente tecla es el intervalo antes de abrir y cerrar.
Después de que se inicializa nuestra tabla t, si usamos select * from t para actualizar para bloquear todos los registros de toda la tabla, se forman 7 bloqueos de la siguiente tecla, que son (-∞, 0], (0,5], ( 5,10], (10,15], (15,20], (20, 25], (25, + supremum).
La introducción del bloqueo de espacios y el bloqueo de la siguiente tecla nos ayudó a resolver el problema de la lectura fantasma, pero también trajo algunas "dificultades".
La lógica empresarial es así: bloquear una fila arbitrariamente, insertar si la fila no existe y actualizar sus datos si la fila existe. Una vez que esta lógica tenga simultaneidad, encontrará un punto muerto.

- La sesión A ejecuta la instrucción select ... for update Dado que la línea id = 9 no existe, se agregará el bloqueo de espacio (5,10);
- La sesión B ejecuta la instrucción select ... for update, y también se agregan los bloqueos de brecha (5, 10.) No habrá conflicto entre bloqueos de brecha, por lo que esta instrucción se puede ejecutar con éxito;
- La sesión B intentó insertar una fila (9,9,9), que estaba bloqueada por el bloqueo de espacio de la sesión A, y tuvo que esperar;
- La sesión A intentó insertar una fila (9,9,9), que fue bloqueada por el bloqueo de espacio de la sesión B.
Por supuesto, la detección de interbloqueo de InnoDB descubrió inmediatamente este par de relaciones de interbloqueo, lo que provocó que la instrucción de inserción de la sesión A informara de un error y regresara. La introducción de bloqueos de espacios puede hacer que la misma declaración bloquee un rango mayor, lo que en realidad afecta el grado de concurrencia . En realidad, este es solo un ejemplo sencillo
Nota: Al comienzo del artículo, enfatizamos que bajo la premisa del nivel de lectura repetible, el bloqueo de espacio solo tendrá efecto bajo el nivel de aislamiento de lectura repetible.
Si configura el nivel de aislamiento para leer la confirmación , no hay bloqueo de espacio. Pero al mismo tiempo, si desea resolver posibles inconsistencias de datos y registros , debe establecer el formato binlog en fila . Si el nivel de aislamiento de envío de lectura es suficiente, es decir, la empresa no requiere garantías de lectura repetibles, por lo que considerando que el rango de bloqueo de los datos de operación bajo envío de lectura es menor (sin bloqueo de espacio), esta opción es razonable .
Reglas de bloqueo
Requisito previo: La versión posterior de MySQL puede cambiar la estrategia de bloqueo, por lo que esta regla está limitada a la última versión hasta ahora, es decir, serie 5.x <= 5.7.24, serie 8.0 <= 8.0.13.
Esta regla de bloqueo contiene dos "principios", dos "optimizaciones" y un "error" :
- Principio 1: La unidad básica de bloqueo es el bloqueo de la siguiente llave, que es el intervalo entre la apertura y el cierre frontal.
- Principio 2: Los objetos a los que se acceda durante el proceso de búsqueda estarán bloqueados.
- Optimización 1: consulta equivalente en el índice, cuando el índice único está bloqueado, el bloqueo de la siguiente tecla degenera en bloqueo de fila.
- Optimización 2: Consulta de equivalencia en el índice, cuando se desplaza hacia la derecha y el último valor no cumple la condición de equivalencia, el bloqueo de la siguiente tecla degenera en un bloqueo de espacio.
- Un error: la consulta de rango en el índice único accederá hasta el primer valor que no cumpla con la condición.
caso de estudio
Los siguientes casos son ejemplos de las tablas y los datos mencionados anteriormente.
1.

Dado que no hay ningún registro con id = 7 en la tabla t, use las reglas de bloqueo que mencionamos anteriormente para juzgar:
- Según el principio 1, la unidad de bloqueo es el bloqueo de la siguiente llave y el rango de bloqueo de la sesión A es (5,10);
- Al mismo tiempo, de acuerdo con la optimización 2, esta es una consulta equivalente (id = 7), y id = 10 no cumple con las condiciones de la consulta, y el bloqueo de la siguiente tecla degenera en un bloqueo de espacio, por lo que el rango de bloqueo final es (5,10).
2.

La sesión A necesita agregar un bloqueo de lectura a la línea c = 5 en el índice c:
- Según el principio 1, la unidad de bloqueo es el bloqueo de la siguiente tecla, por lo que el bloqueo de la siguiente tecla se agrega a (0,5).
- c es un índice ordinario, por lo que solo el acceso al registro c = 5 no puede detenerse inmediatamente. Debe desplazarse hacia la derecha y darse por vencido cuando c = 10. De acuerdo con el principio 2, todos los accesos deben estar bloqueados, así que agregue el bloqueo de la siguiente tecla a (5,10).
- Pero al mismo tiempo esto se ajusta a la optimización 2: juicio equivalente, atravesando hacia la derecha, el último valor no cumple la condición equivalente de c = 5, por lo que degenera en un bloqueo de espacio (5, 10).
- Según el principio 2, solo se bloquearán los objetos a los que se accede. Esta consulta utiliza un índice de cobertura y no necesita acceder al índice de la clave principal, por lo que no hay bloqueo en el índice de la clave principal. Por eso, la declaración de actualización de la sesión B se puede ejecutar.
Cabe señalar que en este ejemplo, bloquear en modo compartir solo bloquea el índice de cobertura , pero es diferente si es para actualización. Al ejecutar la actualización, el sistema pensará que desea actualizar los datos a continuación, por lo que agregará bloqueos de fila a las filas que cumplan con las condiciones del índice de clave principal. Además, este ejemplo muestra que el bloqueo se agrega al índice ; al mismo tiempo, nos da la guía de que si desea usar el bloqueo en el modo compartido para agregar un bloqueo de lectura a la fila para evitar que los datos se actualicen, debe omitir el índice de cobertura Optimizar, agregar campos que no existen en el índice en el campo de consulta.
3.


La figura de la izquierda es una consulta de rango de índice única:
- Al comienzo de la ejecución, es necesario encontrar la primera fila con id = 10, por lo que debería ser el bloqueo de la siguiente tecla (5,10). De acuerdo con la optimización 1, la condición equivalente en la identificación de la clave principal degenera en una fila bloqueo con solo id agregado = bloqueo de 10 filas para esta fila.
- La búsqueda de rango continuará buscando, encontrará la línea id = 15 y se detendrá, por lo que debe agregar el bloqueo de la siguiente tecla (10,15].
La figura de la derecha es una consulta de rango de índice no única:
- Después de agregar el bloqueo de la siguiente tecla (5,10) al índice c de la sesión A, dado que el índice c es un índice no único, no hay una regla de optimización, lo que significa que no degenerará en un bloqueo de fila, por lo que el último candado agregado por la sesion A es el índice Los dos candados de la siguiente llave (5,10] y (10,15) en c .
4.
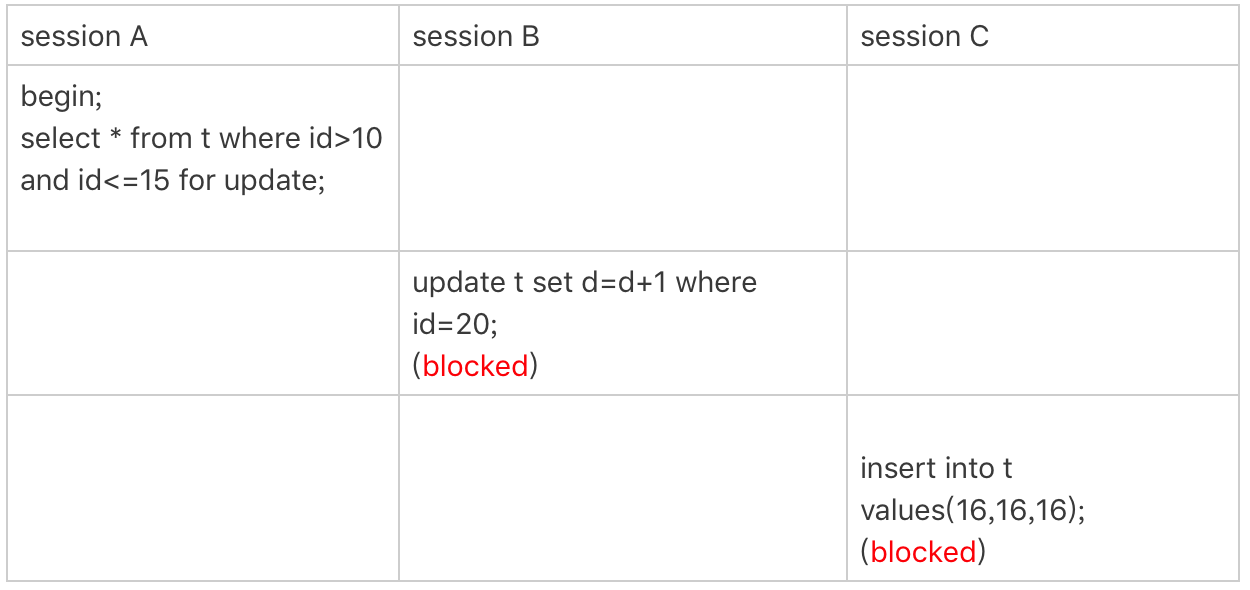
La sesión A es una consulta de rango. De acuerdo con el principio 1, solo el bloqueo de la siguiente tecla (10,15) debe agregarse a la identificación del índice, y debido a que la identificación es una clave única, el ciclo debe detenerse cuando llega a la identificación = 15. . Pero en términos de implementación, InnoDB escaneará hacia el primer comportamiento que no cumpla con la condición, es decir, id = 20. Y debido a que se trata de un escaneo de rango, el bloqueo de la siguiente tecla (15,20) en el índice id también se bloqueará.
5. En el ejemplo anterior, inserte un nuevo registro en la tabla t: inserte en t valores (30,10,30);
Ahora hay dos filas con c = 10 en la tabla, pero su ID de valor de clave principal es diferente (10 y 30 respectivamente), por lo que hay un espacio entre los dos registros con c = 10 . Esta vez usamos la declaración de eliminación para verificar. Tenga en cuenta que la lógica de bloqueo de la declaración de eliminación es en realidad similar a seleccionar ... para actualizar, que son los dos "principios", dos "optimizaciones" y un "error" que resumí al principio del artículo.

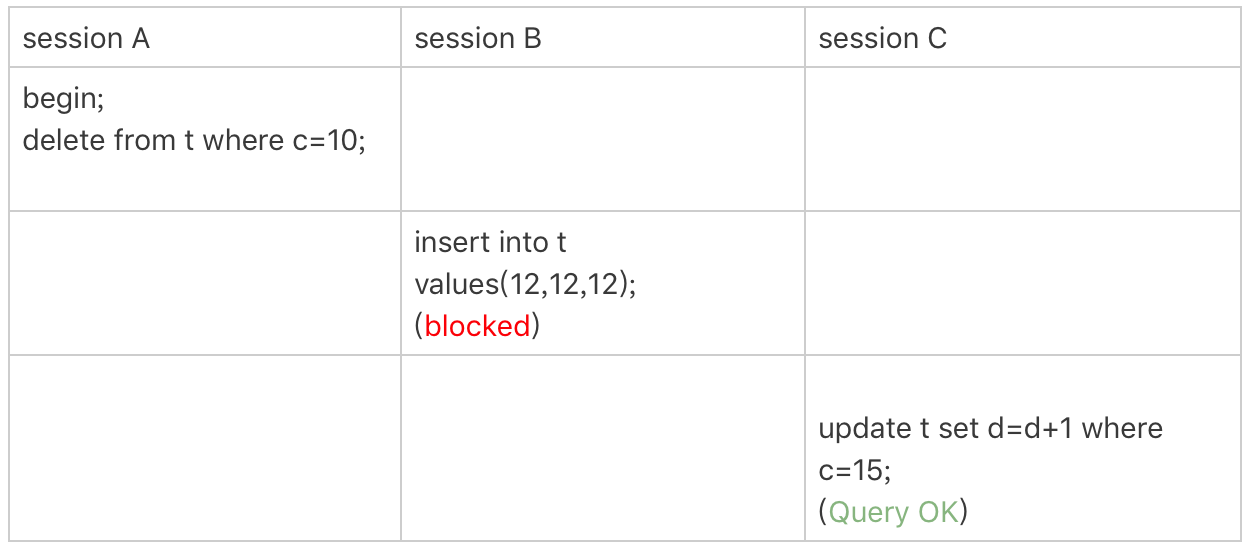
- Cuando la sesión A está atravesando, primero visite el primer registro con c = 10. De manera similar, de acuerdo con el principio 1, aquí está el bloqueo de la siguiente tecla (c = 5, id = 5) a (c = 10, id = 10) .
- Luego, la sesión A mira hacia la derecha hasta que llega a la línea (c = 15, id = 15) y el ciclo no termina. Según la optimización 2, esta es una consulta equivalente, y la fila que no cumple la condición se encuentra a la derecha, por lo que degenerará en un bloqueo de espacio de (c = 10, id = 10) a (c = 15, id = 15).
Hay líneas de puntos en los lados izquierdo y derecho de esta área azul, lo que indica el intervalo abierto, es decir, no hay bloqueo en las dos líneas (c = 5, id = 5) y (c = 15, id = 15) .

6. Continúe con el caso 5 anterior.

El límite 2 se agrega a la declaración de eliminación de la sesión A. Sabe que en realidad solo hay dos registros con c = 10 en la tabla t, por lo que si se agrega el límite 2 o no, el efecto de eliminación es el mismo, pero el efecto de bloqueo es diferente. Como puede ver, la declaración de inserción de la sesión B ha pasado. Por lo tanto, después de atravesar la línea (c = 10, id = 30), ya hay dos declaraciones que cumplen las condiciones y el ciclo termina.
Por lo tanto, el rango de bloqueo en el índice c pasa a ser de (c = 5, id = 5) a (c = 10, id = 30), que es el intervalo abierto y cerrado , como se muestra en la siguiente figura:

7. Ejemplos de interbloqueo

- Después de que la sesión A inicie la transacción, ejecute la instrucción de consulta más el bloqueo en el modo de compartir y agregue el bloqueo de la siguiente tecla (5,10) y el bloqueo de espacio (10,15) al índice c;
- La declaración de actualización de la sesión B también debe agregar el bloqueo de la siguiente tecla (5,10] al índice c para ingresar al bloqueo en espera;
- Luego, la sesión A debe insertar la línea (8,8,8) nuevamente, que está bloqueada por el bloqueo de espacio de la sesión B. Debido a un punto muerto, InnoDB permite que la sesión B retroceda.
8.

- Dado que está ordenado por c desc, la primera fila que se ubicará es la fila "más a la derecha" c = 20 en el índice c, por lo que se agregarán el bloqueo de espacio (20,25) y el bloqueo de siguiente tecla (15,20].
- Desplácese hacia la izquierda en el índice c y deténgase hasta que c = 10, por lo que el bloqueo de la siguiente tecla se agregará a (5,10), que es la razón por la cual la instrucción de inserción de la sesión B está bloqueada.
- Durante el proceso de escaneo, las tres filas c = 20, c = 15 y c = 10 tienen valores. Debido a que se selecciona *, se agregan tres bloqueos de fila a la identificación de la clave principal.
Por lo tanto, el rango de bloqueo de la instrucción select de la sesión A es: (5, 25) en el índice c, e id = 15 y 20 en el índice de clave principal.
Fuente del contenido: Lin Xiaobin "45 conferencias sobre combate real de MySQL"