Directorio de artículos
Bloqueo optimista frente a bloqueo pesimista
El bloqueo optimista y el bloqueo pesimista se nombran por sus significados, la diferencia entre ellos es la actitud de hacer las cosas .
Bloqueo pesimista
El bloqueo pesimista es más pesimista. Siempre cree que los recursos compartidos serán modificados por otros subprocesos cuando los usemos, lo que puede conducir fácilmente a problemas de seguridad de subprocesos. Por lo tanto, primero debemos bloquear y bloquear el acceso de otros subprocesos antes de acceder a los datos compartidos .
Los ejemplos comunes son bloqueos de filas, bloqueos de tablas, bloqueos de lectura, bloqueos de escritura, etc. en la base de datos
Cerradura optimista
El bloqueo optimista es lo opuesto al bloqueo pesimista, que es más optimista. Siempre cree que la probabilidad de que varios subprocesos modifiquen los recursos compartidos al mismo tiempo es baja, por lo que no importa si lo cambia.
El bloqueo optimista modificará directamente el recurso compartido, pero antes de actualizar el resultado de la modificación, verificará si otros subprocesos han modificado el recurso durante este período, si no, enviar la actualización, si la hay, luego abandonar la operación.
Debido a que el bloqueo optimista no está bloqueado en todo el proceso, también se denomina programación sin bloqueo , que generalmente se implementa mediante la operación CAS + mecanismo de número de versión .
CASO
Mecanismo CAS
CAS es la abreviatura de la palabra inglesa Compare And Swap, que es comparar y reemplazar , que es su núcleo.
Se utilizan tres operandos básicos en el mecanismo CAS, la dirección de memoria V, el antiguo valor esperado A y el nuevo valor esperado B
Cuando necesitamos modificar una variable, comparamos la dirección de memoria V con el antiguo valor esperado.Si los dos son iguales, reemplazamos el antiguo valor esperado A con el nuevo valor esperado B. Si son diferentes, use el valor en V como el valor esperado anterior y continúe repitiendo la operación anterior, es decir, gire .
Los siguientes son ejemplos de éxito y fracaso respectivamente.
En este momento, el valor almacenado en la dirección de memoria es 9, el antiguo valor esperado del hilo 1 es 9 y el nuevo valor esperado es 10, es decir, necesitamos sumar uno al valor en el

antiguo El valor esperado es el mismo que V, y la

modificación es exitosa en este momento al intercambiar B y V.
Entonces mire el fracaso de la modificación
En este momento, el valor en V es 9, y el antiguo valor esperado en el hilo 1 es 9, y queremos cambiar el valor en V a 10.

Cuando estamos a punto de modificar, de repente un hilo actualiza los datos primero, y el valor de V se convierte en 14

Dado que el valor de A es diferente de V en este momento, necesitamos obtener el valor en V nuevamente y calcular el nuevo valor esperado
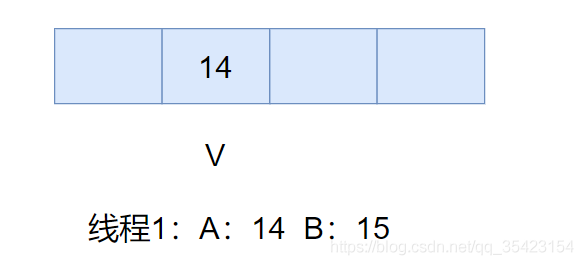
En este momento, los dos son iguales, el reemplazo se completa, V = 15
Como se puede ver en lo anterior, CAS es un bloqueo optimista, cree con optimismo que la concurrencia en el programa no es tan grave, por lo que deja que el hilo siga intentando actualizarse.
Problema de ABA
El llamado problema de ABA es que una variable se cambió de A a B, a continuación, de B a convertirse en el A .
Supongamos que estoy retirando dinero del banco. En este momento, tengo 1.000 yuanes en mi cuenta. Quiero retirar 500 yuanes. Sin embargo, debido a fluctuaciones repentinas en la red, esta operación se ha repetido dos veces, por lo

que solo podemos Realiza la primera deducción. Después de la ejecución, A! = V, por lo que el segundo hilo continuará girando y comparando.

En este momento, sucede que el compañero de cuarto pagó los 500 yuanes que pediste prestados hace unos años, y tu cantidad ha cambiado nuevamente. 1000

En este momento, el hilo 2 le descontó 500 nuevamente, por lo que retiró 500 yuanes, pero accidentalmente dedujo 1000.

Entonces, ¿cómo resolver este problema? Podemos introducir un mecanismo de número de versión , que solo puede ser reemplazado

cuando el número de versión es el mismo. Cuando el compañero de habitación te transfiere, debido al cambio en el valor, el número de versión también ha sido modificado.

En este momento, aunque los valores en A y V son los mismos, Pero el número de versión es diferente, por lo que no se puede cambiar.
Ventajas y desventajas de CAS
ventaja
- Cuando hay menos simultaneidad o menos operaciones de modificación variable, la eficiencia será mayor que el bloqueo tradicional, porque no implica cambiar entre el modo de usuario y el modo de kernel.
Desventaja
- El giro se compara y se reemplaza. Cuando la cantidad de simultaneidad es grande, es posible que no tenga éxito porque las variables se actualizan todo el tiempo y el giro continuo causará una presión excesiva en la CPU.
- CAS solo puede garantizar la atomicidad de una variable, pero no la atomicidad de todo el bloque de código, por lo que aún es necesario bloquear cuando se trata de actualizaciones atómicas de múltiples variables.
- El problema ABA anterior se puede resolver introduciendo el número de versión
Mutex VS Spinlock
Los bloqueos de exclusión mutua y los bloqueos giratorios son los dos tipos de bloqueos inferiores. La mayoría de los bloqueos de alto nivel se implementan en función de ellos. Hablemos de sus diferencias.
Mutex
Mutex es un bloqueo de suspensión , es decir, cuando un subproceso ocupa el bloqueo, otros subprocesos que no se bloquean pasarán a suspensión
Por ejemplo, tenemos dos subprocesos A y B que compiten por el bloqueo de mutex juntos. Cuando el subproceso A agarra con éxito el bloqueo de mutex, el bloqueo será monopolizado por él. Antes de liberar el bloqueo, la operación de bloqueo de B fallará y En este momento, el subproceso B cede la CPU a otros subprocesos, mientras que él mismo está bloqueado.
El fenómeno de que el bloqueo mutex entra en bloqueo después de fallar en el bloqueo es implementado por el kernel del sistema operativo , como se muestra en la figura siguiente
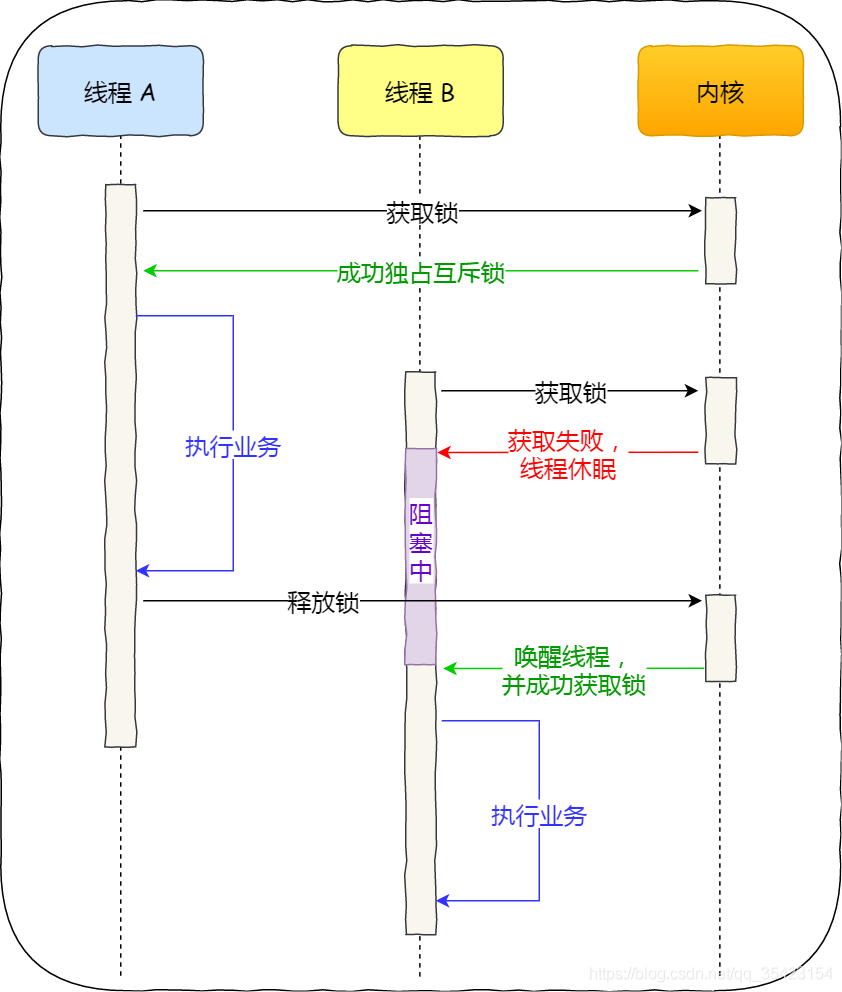
- Cuando el bloqueo falla, el kernel pondrá el hilo en suspensión y cambiará la CPU a otros hilos para que se ejecuten. Cambiar del modo de usuario al modo de kernel en este momento
- Cuando se libera el bloqueo, el kernel lleva el subproceso al estado listo y luego lo activa en el momento adecuado para adquirir el bloqueo y continuar ejecutando el negocio. Cambiar del modo kernel al modo usuario en este momento
Entonces, cuando el bloqueo de exclusión mutua no se bloquea, se acompaña de la sobrecarga de dos cambios de contexto , y si bloqueamos el tiempo durante un tiempo breve, el tiempo de cambio de contexto puede ser mayor que el tiempo de bloqueo.
Aunque la dificultad de usar mutexes es relativamente baja, considerando la sobrecarga del cambio de contexto, en algunos casos daremos prioridad a los bloqueos de giro.
Bloqueo giratorio
El bloqueo de giro se implementa en base a CAS . Completa las operaciones de bloqueo y desbloqueo en el modo de usuario y no cambia activamente el contexto , por lo que su sobrecarga es menor que la del bloqueo de mutex.
Cualquier hilo que intente adquirir el bloqueo seguirá intentándolo (es decir, girar) hasta que se obtenga el bloqueo, y solo un hilo puede adquirir el bloqueo de giro al mismo tiempo.
La esencia del bloqueo de giro es en realidad una operación CAS en un número entero en la memoria . El bloqueo implica los siguientes pasos
- Verifique el valor del entero, si es 0, el bloqueo está libre, luego realice el segundo paso, si es 1, el bloqueo está ocupado y se realiza el tercer paso
- Establezca el valor del entero en 1, el hilo actual entra en la sección crítica
- Continúe con la verificación de giro (de regreso al primer paso) hasta que el valor entero sea 0
De lo anterior se puede ver que el hilo que no logró adquirir el bloqueo de giro siempre estará ocupado esperando , girando hasta que adquiera el recurso de bloqueo, lo que también requiere que liberemos el bloqueo lo antes posible, de lo contrario ocupará una gran cantidad de recursos de CPU
Escenarios de comparación y aplicación
Debido a las diferentes estrategias de falla de los bloqueos de giro y los bloqueos de mutex, los bloqueos de giro usan una estrategia de espera ocupada , mientras que los bloqueos de mutex usan una estrategia de cambio de hilo . Debido a las diferentes estrategias, sus escenarios de aplicación también son diferentes.
Dado que el bloqueo de giro no requiere conmutación de subprocesos, está completamente implementado en modo de usuario y la sobrecarga de bloqueo es baja. Sin embargo, debido a su estrategia de espera ocupada, no es un problema para el bloqueo a corto plazo, pero provocará un bloqueo a largo plazo. Gran consumo de recursos de CPU. Y como no duerme, se puede utilizar en controladores de interrupciones.
El mutex utiliza una estrategia de conmutación de subprocesos. Cuando se cambia a otro subproceso, el subproceso original entrará en el estado de suspensión (bloqueo), por lo que si hay un requisito de suspensión, puede considerar el uso de un mutex. Y debido a que la suspensión no ocupa recursos de la CPU, tiene una gran ventaja sobre los bloqueos de giro en el bloqueo a largo plazo.
Los escenarios de aplicación específicos se muestran en la siguiente tabla
| demanda | Método de bloqueo |
|---|---|
| Bloqueo de techo bajo | Bloqueo giratorio |
| Bloqueo a corto plazo | Bloqueo giratorio |
| Bloqueo a largo plazo | Mutex |
| Bloquear el contexto de interrupción | Bloqueo giratorio |
| Se requiere dormir para mantener la cerradura | Mutex |
Bloqueo de lectura y escritura
El bloqueo de lectura y escritura se utiliza para distinguir claramente entre escenarios de lectura y escritura .
Su núcleo reside en escritura exclusiva, lectura compartida
- El bloqueo de lectura es un bloqueo compartido.Cuando ningún subproceso mantiene el bloqueo de escritura, el bloqueo de lectura se puede mantener simultáneamente por varios subprocesos, lo que mejora en gran medida la eficiencia de acceso de los recursos compartidos. Dado que el bloqueo de lectura solo tiene permisos de lectura, no hay ningún problema de seguridad de subprocesos.
- El bloqueo de escritura es un bloqueo exclusivo (bloqueo exclusivo) . Cuando cualquier subproceso mantiene el bloqueo de escritura, la adquisición de los otros subprocesos del bloqueo de lectura y el bloqueo de escritura se bloqueará
Como se muestra abajo
| Leer bloqueo | Bloqueo de escritura | |
|---|---|---|
| Leer bloqueo | compatible | No compatible |
| Bloqueo de escritura | No compatible | No compatible |
Método para realizar
Según los diferentes métodos de implementación, los bloqueos de lectura y escritura se dividen en lector primero, escritor primero y lectura y escritura correctas.
Lector primero
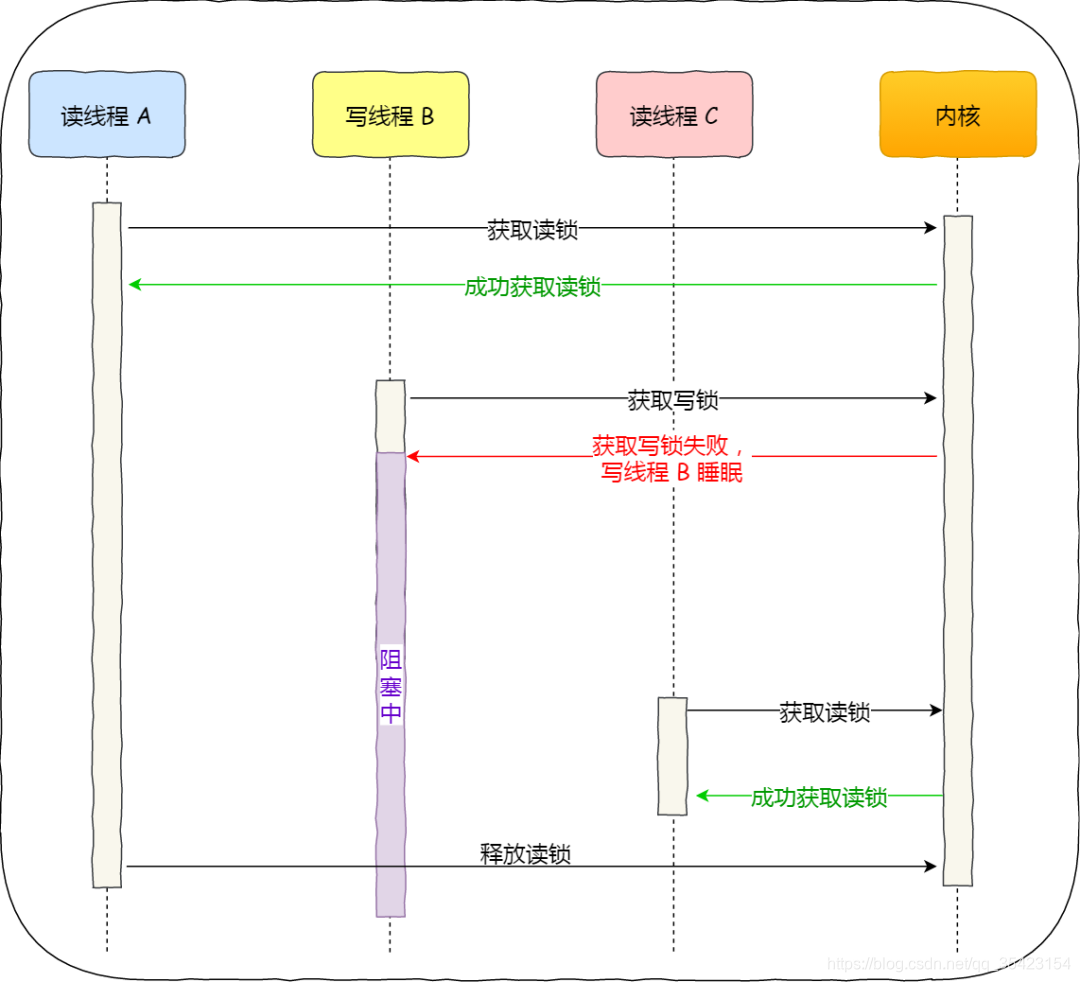
La primera expectativa del lector es que el bloqueo de lectura pueda mantenerse en más subprocesos para mejorar la concurrencia de los subprocesos de lectura.
Para hacer esto, sus reglas son las siguientes: incluso si un hilo solicita un bloqueo de escritura, siempre que haya lectores leyendo el contenido, otros hilos del lector pueden continuar solicitando un bloqueo de lectura y el proceso de solicitud de un bloqueo de escritura se bloquea hasta que Cuando ningún hilo del lector está leyendo, el hilo puede escribir
El proceso es el siguiente
Escritores primero
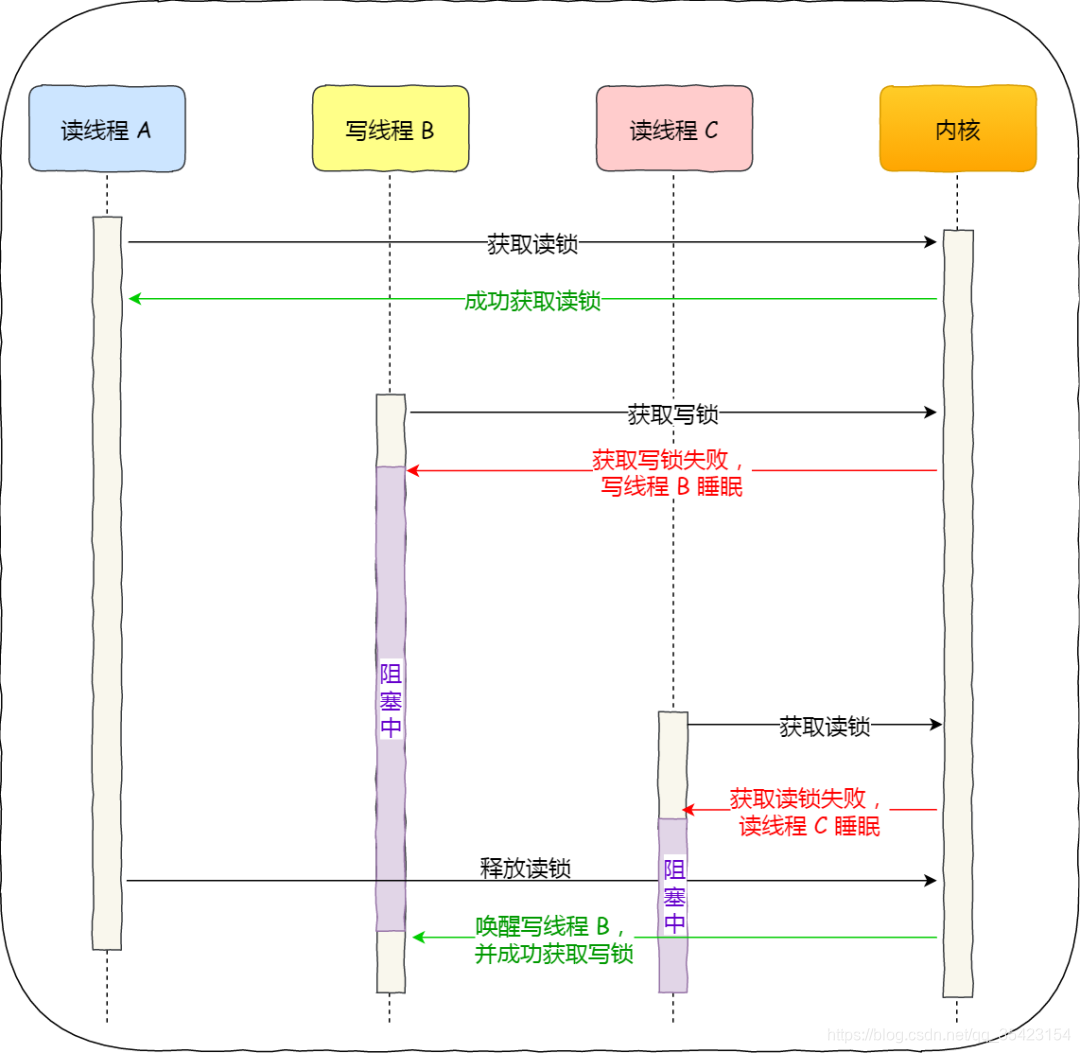
Y el escritor primero debe dar prioridad al proceso de escritor.
Supongamos que en este momento, un hilo de lectura ya tiene un bloqueo de lectura y está leyendo, y otro hilo de escritura aplica para un bloqueo de escritura y el hilo de escritura está bloqueado. Para garantizar que el escritor tenga prioridad, los subprocesos posteriores del lector se bloquearán cuando adquieran el bloqueo de lectura. Cuando el hilo del lector anterior libera el bloqueo de lectura, el hilo del escritor realiza una operación de escritura y otros hilos se bloquearán hasta que el hilo del escritor termine de escribir.
El proceso es el siguiente
Feria de alfabetización
Se puede ver en las dos reglas anteriores que la prioridad para leer y escribir hará que la otra parte muera de hambre.
- Cuando se priorizan los lectores , la concurrencia para el proceso de lectura es alta, pero si hay procesos que siempre adquieren el bloqueo de lectura, el proceso de escritura nunca podrá adquirir el bloqueo de escritura y el proceso de escritura se morirá de hambre.
- Cuando el escritor tiene prioridad , aunque se puede garantizar que el proceso de escritura no morirá de hambre, si el proceso de escritura ha ido adquiriendo el bloqueo de escritura, el proceso de lectura nunca obtendrá el bloqueo de lectura y el proceso de lectura se morirá de hambre.
Dado que favorecer a cualquiera de las partes hará que la otra se muera de hambre, podemos hacer una regla que lea y escriba de manera justa
Método de implementación: use una cola para poner en cola el hilo que adquiere el bloqueo. Ya sea el hilo de escritura o el hilo de lectura, el bloqueo se bloquea de acuerdo con el principio de primero en entrar, primero en salir. Esto también permite que el hilo de lectura sea concurrente sin hambre.
Bloqueo de lectura y escritura VS bloqueo de mutex
En términos de rendimiento, la eficiencia de los bloqueos de lectura y escritura no es mayor que la de los bloqueos mutex. La sobrecarga de los bloqueos de lectura y el bloqueo no es menor que la de los bloqueos de mutex, porque necesita mantener el número actual de lectores en tiempo real. Cuando el área crítica es pequeña y la competencia de bloqueos no es feroz, la eficiencia de los bloqueos de mutex suele ser más rápida
Aunque los bloqueos de lectura y escritura pueden no ser tan rápidos como los bloqueos de mutex, tienen una buena concurrencia. Para lugares con altos requisitos de concurrencia, se debe dar prioridad a los bloqueos de lectura y escritura.