Expresión regular de shell
Tabla de contenido
- 1. Expresión regular de shell
-
- 1. El comando de ordenación: ordena el contenido del archivo por unidad de línea o según diferentes tipos de datos
- 2. El comando uniq --- utilizado para informar o ignorar líneas repetidas consecutivas en un archivo, a menudo combinado con el comando sort
- Tres, comando tr --- comúnmente utilizado para reemplazar, comprimir y eliminar caracteres de la entrada estándar
- Dos, expresión regular
1. Expresión regular de shell
1. El comando de ordenación: ordena el contenido del archivo por unidad de línea o según diferentes tipos de datos
Formato de sintaxis:
sort [选项] 参数
cat file | sort 选项


常用选项:
-f:忽略大小写
-b:忽略每行前面的空格
-n:按照数字进行排序
-r:反向排序
-u:等同于uniq,表示相同的数据仅显示一行
-t:指定字段分隔符,默认使用[Tab]键分隔
-k:指定排序字段
-o <输出文件>:将排序后的结果转存至指定文件
sort -n test.txt

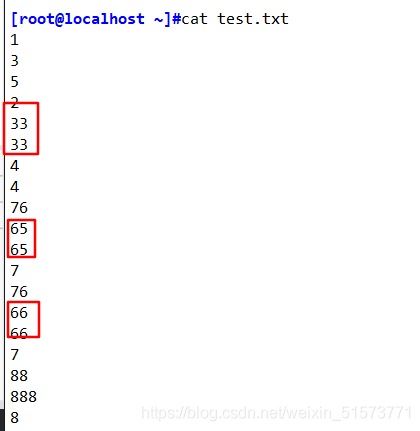
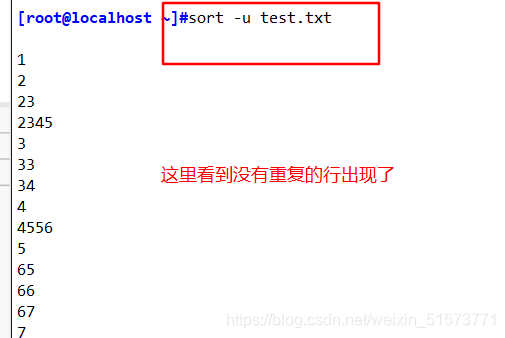
sort -u test.txt
sort -t ":" -k3 -n /etc/passwd

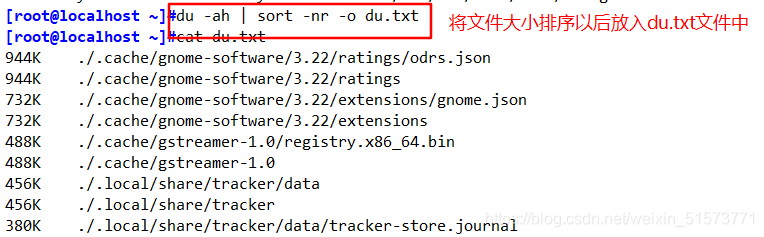
du -ah | sort -nr -o du.txt
2. El comando uniq: se utiliza para informar o ignorar líneas repetidas consecutivas en un archivo, a menudo combinado con el comando sort
语法格式:
uniq [选项] 参数
cat file | uniq 选项
常用选项:
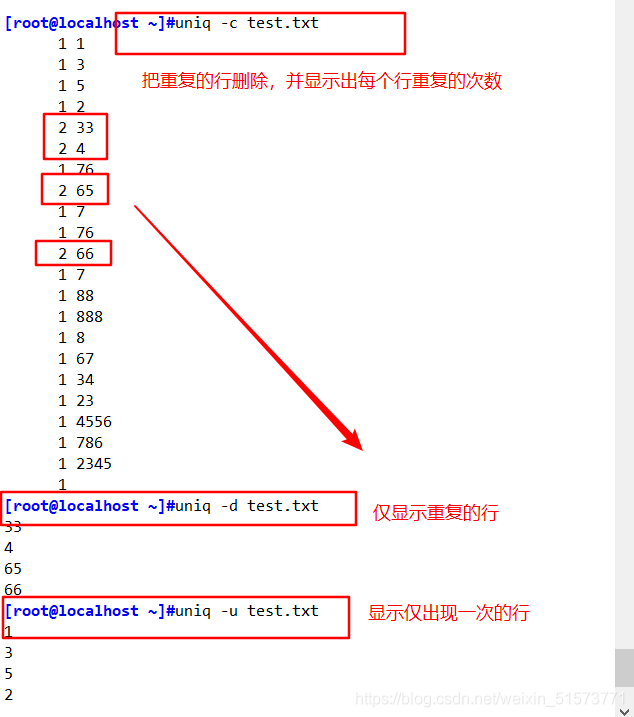
-c:进行计数,并删除文件中重复出现的行
-d:仅显示重复行
-u:仅显示出现一次的行
Tres, comando tr: comúnmente utilizado para reemplazar, comprimir y eliminar caracteres de la entrada estándar
语法格式:
tr [选项] [参数]
常用选项:
-c:保留字符集1的字符,其他的字符用(包括换行符\n)字符集2替换
-d:删除所有属于字符集1的字符
-s:将重复出现的字符串压缩为一个字符串;用字符集2 替换 字符集1
-t:字符集2 替换 字符集1,不加选项同结果。
参数:
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集。但执行删除操作时,不需要参数“字符集2”;
字符集2:指定要转换成的目标字符集。
[root@localhost ~]#echo "abc" | tr 'a-z' 'A-Z'
ABC
#将abc替换成ABC
[root@localhost ~]#echo abccabacca | tr -c "ab\n" "0"
ab00aba00a
#保留ab字符,将其他字符替换成00
[root@localhost ~]#echo 'hello world' | tr -d 'od'
hell wrl
#删除od字符
[root@localhost ~]#echo "thissss is a text linnnnnnne." | tr -s 'sn'
this is a text line.
#将重复出现的s n字符压缩成一个字符
[root@localhost ~]#cat 123.txt
aa
bb
[root@localhost ~]#cat 123.txt | tr -s "\n"
aa
bb
#删除空行
[root@localhost ~]#echo $PATH | tr -s ":" "\n"
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/root/bin
#把路径变量中的冒号":",替换成换行符"\n"
#删除Windows文件“造成”的'^M'字符:
cat 22.txt | tr -s "\r" "\n" > new_22.txt
或cat 22.txt | tr -d "\r" > new_22.txt
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作。而windows中要回车符+换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行。
[root@localhost ~]#rz -E
rz waiting to receive.
[root@localhost ~]#cat -A aa.txt
aa^M$
^M$
^M$
^M$
#在window创建一个文件,放入linux里面cat -A aa.txt 看到每个空格显示^M$.格式会发生变化

yum install -y dos2unix
dos2unix 33.txt #借用这个工具也可以改变格式,需要安装

Tipo de matriz
abc=(3 5 8 7 9 2 1)
echo ${abc[*]} | tr ' ' '\n' | sort -n

Dos, expresión regular
1. Función
Las expresiones regulares se usan generalmente en declaraciones de juicio para detectar si una cadena cumple con un formato determinado
2. Composición de expresiones regulares
La expresión regular se compone de caracteres ordinarios y metacaracteres.
Los caracteres comunes incluyen letras mayúsculas y minúsculas, números, signos de puntuación y algunos otros símbolos.
Los metacaracteres se refieren a caracteres especiales con un significado especial en expresiones regulares. Se pueden utilizar para especificar la apariencia del carácter principal (el carácter antes del metacarácter) en el objeto de destino
3. Metacaracteres comunes en expresiones regulares básicas (herramientas compatibles: grep, egrep, sed, awk)
| Metacaracteres comunes de expresiones regulares básicas | descripción |
|---|---|
| \ | El carácter de escape se utiliza para cancelar el significado de símbolos especiales. Ejemplo:!, \ N, $, etc. |
| ^ | La posición donde comienza la cadena de coincidencias. Ejemplo: a, the, #, [az] |
| PS | La posición donde termina la cadena correspondiente. Ejemplo: error de análisis de wordKaTeX: grupo esperado después de '^' en la posición 2 :, ^ ̲ coincide con líneas en blanco |
| . | Coincide con cualquier carácter excepto \ n. Ejemplo: go.d, g ... d |
| * | Coincide con la subexpresión anterior 0 o más veces, por ejemplo: goo * d, go. * D |
| [lista] | Coincide con un carácter de la lista, por ejemplo: vaya [ola] d, [abc], [az], [a-z0-9], [0-9] coincida con cualquier dígito |
| [^ lista] | Coincide con cualquier carácter en una lista que no esté en la lista, por ejemplo: [^ 0-9], [^ A-Z0-9], [^ az] coincide con cualquier letra que no sea minúscula |
| {norte} | Coincide con la subexpresión anterior n veces, por ejemplo: go {2} d, '[0-9] {2,}' coincide con dos dígitos |
| {norte} | Coincide con la subexpresión anterior no menos de n veces, por ejemplo: vaya {2,} d, '[0-9] {2,}' coincida con dos o más dígitos |
| {Nuevo Méjico} | Coincide con la subexpresión anterior n am veces, por ejemplo: vaya {2,3} d, '[0-9] {2,3}' coincida con dos o tres dígitos |
Nota: cuando egrep y awk usan {n}, {n,}, {n, m} para coincidir, no es necesario agregar "{}" antes de "\"
4. Metacaracteres de expresión regular extendidos (herramientas compatibles: egrep, awk)
| Metacaracteres extendidos de expresión regular | descripción |
|---|---|
| + | Coincide con la subexpresión anterior más de una vez, por ejemplo: go + d, coincidirá con al menos una o, como dios, bueno, bueno, etc. |
| ? | Coincide con la subexpresión anterior 0 o 1 vez, por ejemplo: go? D, coincidirá con gd o god |
| () | Tome la cadena entre paréntesis como un todo, por ejemplo: g (oo) + d, coincidirá con oo como un todo más de una vez, como bueno, bueno, etc. |
| | | Coincidir la cadena de palabras de una manera o, por ejemplo: g (oo | la) d, coincidirá bien o contento |