Haga clic a continuación para seguirme y luego haga clic en... "Establecer como estrella" en la esquina superior derecha para recibir actualizaciones lo antes posible ~~~
Las expresiones regulares (Expresión regular) a menudo se abrevian como expresiones regulares en el código. Las expresiones regulares se utilizan generalmente para recuperar y reemplazar texto que se ajusta a ciertas reglas y es una herramienta de procesamiento de texto potente y flexible. La regularidad describe una regla mediante la cual se puede hacer coincidir un tipo de cadena.
Para facilitar la comprensión, las expresiones regulares en todos los ejemplos están representadas por "regex=regular" . El signo "=" va seguido de la expresión regular. Los caracteres coincidentes se marcarán con colores. Los caracteres coincidentes consecutivamente se marcarán con un oscuro y uno claro.Distinción de color.
Por ejemplo: regex=\d+, donde \d+ es una regla regular, que coincide con cualquier número mayor que 1, de la siguiente manera:
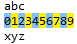
Aprender la sintaxis de las expresiones regulares consiste principalmente en aprender metacaracteres y su comportamiento en el contexto de las expresiones regulares. Los metacaracteres incluyen: caracteres ordinarios, caracteres estándar, caracteres especiales, caracteres calificativos (cuantificadores) y caracteres de posicionamiento (caracteres de límite).
1. personajes ordinarios
Letras [a-zA-Z], números [0-9], subrayado [-], caracteres chinos, signos de puntuación
Hacer coincidir la letra a puede ser regex=a
Hacer coincidir la letra b puede ser regex=b
Hacer coincidir las letras aob puede ser regex=a|b. Esta expresión regular introduce un carácter especial "|" , cuyo nombre profesional es "o". También puedes llamarlo "barra vertical". En resumen, significa "o". .
Hacer coincidir las letras aoboc puede ser regex=a|b|c
Hacer coincidir las letras aobococd puede ser regex=a|b|c|d
Obviamente me parece un poco tonto escribir de esta manera, si coincide con las 26 letras, esta forma de escribir es demasiado confusa.
Aquí se introducen dos caracteres especiales: corchetes "[ ]" y guión bajo "-"
"[ ]" , el nombre profesional es "conjunto de caracteres", también puedes llamarlo "corchetes".
"-" significa "rango", también puedes llamarlo "a", regex=[az] coincide con cualquiera de las 26 letras de la a a la z.
Luego, hacer coincidir las letras aobocd puede ser regex=[abcd]
Para hacer coincidir cualquier número del 1 al 8, puede usar regex=[1-8], de modo que los dos números 0 y 9 no coincidan, de la siguiente manera:
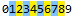
2. Juego de caracteres estándar
El juego de caracteres estándar es una expresión simple que puede coincidir con "muchos caracteres comunes", como: \d, \w, \s
Hacer coincidir cualquier número del 0 al 9 puede ser regex=[0-9] o regex= \d
El conjunto de caracteres estándar debe distinguir entre mayúsculas y minúsculas, ya que las mayúsculas tienen el significado opuesto.
regex= \D, coincide con caracteres no numéricos, es decir, no puede coincidir con los números del 0 al 9, de la siguiente manera:
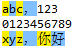
Las siguientes son algunas descripciones de caracteres estándar de uso común.
| Caracteres estándar | significado |
| \d | Coincide con cualquier número del 0 al 9, equivalente a [0-9] |
| \D | Coincide con caracteres no numéricos, equivalente a [^0-9] |
| \w | Coincide con cualquier letra, número o guión bajo, equivalente a [^A-Za-z0-9_] |
| \W | Coincide con cualquier carácter no alfanumérico, numérico o de subrayado, equivalente a [^A-Za-z0-9_] |
| \s | Coincide con cualquier carácter de espacio en blanco, incluidos espacio, tabulación y avance de formulario, equivalente a [\f\n\r\t\v] |
| \S | Coincide con cualquier carácter que no sea un espacio en blanco, equivalente a [^\f\n\r\t\v] |
| \norte | Coincidir con el carácter de nueva línea |
| \r | Coincide con un retorno de carro |
| \ t | coincidir con el carácter de la pestaña |
| \v | Coincidir con pestaña vertical |
| \F | Coincidir con el feed de formulario |
3. Caracteres especiales
Estos caracteres tienen significados especiales en expresiones regulares, como: *, +, ? ,\, etc.
"\" es un carácter de escape que se utiliza para hacer coincidir caracteres especiales.
Para hacer coincidir la barra invertida "\", puede usar regex=[\\]. Debido a que "\" es un carácter especial, debe agregar otro "\" delante para escapar.
Para hacer coincidir el asterisco "*", puede usar regex=\*. Debido a que "*" es un carácter especial, debe agregar otro "*" delante para escaparlo.
Las siguientes son algunas descripciones de caracteres especiales de uso común, que se analizarán más adelante.
| Caracteres especiales | significado |
| \ | Carácter de escape para marcar el siguiente carácter como carácter especial |
| ^ | Coincide con el comienzo de la cadena. |
| ps | Coincide con la posición al final de una cadena. |
| * | Coincide con el carácter o subexpresión anterior cero o más veces |
| + | Coincide con el carácter o subexpresión anterior una o más veces |
| ? | Coincide con el carácter o subexpresión anterior cero o una vez |
| . | "Punto" coincide con cualquier carácter excepto "\r\n" |
| | | o |
| [ ] | conjunto de caracteres |
| ( ) | Agrupación, para hacer coincidir los caracteres entre paréntesis, utilice "\(" o "\)" |
4. Caracteres calificativos (cuantificadores)
Los caracteres calificadores, también llamados cuantificadores, se utilizan para indicar el número de caracteres coincidentes.
Haga coincidir cualquier número de 1 dígito con regex=\d
Haga coincidir cualquier número de 2 dígitos con regex=\d\d
Haga coincidir cualquier número de 3 dígitos con regex=\d\d\d
Coincide con cualquier número de 16 dígitos. Sería un poco tonto escribirlo así.
Aquí se introduce el carácter "{n}" utilizado para representar el límite de cantidad.
" {n} " , n es un número entero no negativo, coincidente n veces
Nota: regex=\d\d{3} coincide con 4 números cualesquiera, no 6. El cuantificador solo es responsable de los caracteres anteriores. El contenido coincidente de regex=\d\d{3} es el siguiente:

Haga coincidir cualquier número de 16 dígitos con regex=\d{16}
Para hacer coincidir cualquier número con más de 16 dígitos, puede usar regex=\d{16,}
Para hacer coincidir cualquier número de 1 a 16 o más dígitos, puede usar regex=\d{1,16}
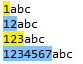
En la imagen de arriba, podemos ver que regex=\d{1,16} puede coincidir con cualquier número del 1 al 16.
A continuación se presenta el modo codicioso y el modo no codicioso en el número de coincidencias :
La coincidencia regular tiene por defecto el modo codicioso, es decir, cuantos más caracteres coincidan, mejor. El modo no significa que cuantos menos caracteres coincidan, mejor. Simplemente agregue un signo de interrogación "?" después de modificar el cuantificador del número de coincidencias. palabras .
Entonces, ¿la misma cadena que la anterior, regex=\d{1,16}? ¿Con qué coincide?
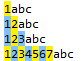
Debido a que se agrega un signo de interrogación "?" después del cuantificador {1,16} , que indica un modo no codicioso, solo se puede hacer coincidir un número, es decir, cuantos menos caracteres coincidentes, mejor.
Las siguientes son algunas descripciones de caracteres de calificación de uso común.
| Personajes calificados | significado |
| * | Coincide con el carácter o subexpresión anterior cero o más veces |
| + | Coincide con el carácter o subexpresión anterior una o más veces |
| ? | Coincide con el carácter o subexpresión anterior cero o una vez |
| {norte} | n es un número entero no negativo que coincide con un cierto número de n veces |
| {norte,} | n es un número entero no negativo que coincide al menos n veces |
| {Nuevo Méjico} | n y m son números enteros no negativos, donde n<=m; coinciden al menos n veces y como máximo m veces |
Hacer coincidir 0 o más letras A puede ser regex=A* o regex=A{0,}
Hacer coincidir al menos una letra A puede ser regex=A+ o regex=A{1,}
Para hacer coincidir 0 o 1 letra A, puede usar regex=A? o regex=A{0,1}
Hacer coincidir al menos un AMOR puede ser expresión regular=(LOVE)+
El efecto de coincidencia es el siguiente:

5. Posicionamiento de personajes (límites de personajes)
Los caracteres de posicionamiento también se denominan límites de caracteres. Los marcadores no coinciden con caracteres sino con posiciones que cumplen ciertas condiciones, por lo que los caracteres de posicionamiento tienen "ancho cero".
Las siguientes son algunas descripciones de caracteres de posicionamiento de uso común.
| personaje ancla | significado |
| ^ | Coincide con la posición inicial de la cadena, indicando el comienzo. |
| ps | Coincide con la posición al final de la cadena, indicando el final |
| \b | coincidir con el límite de una palabra |
Las cadenas coincidentes que comienzan con Hola pueden ser expresiones regulares=^Hola
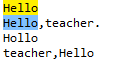
Para hacer coincidir una cadena que termina en Hola, puede usar regex=Hello$, de la siguiente manera:

Para hacer coincidir una cadena de cualquier longitud que comience con H y termine con o, puede usar regex= ^H.*o$ , de la siguiente manera:

" \b " coincide con una posición donde el carácter anterior y el siguiente no son todos \w
Si regex=hola\b coincide en la cadena "hola,hola1 hola1 bhola",
Los resultados coincidentes son los siguientes:
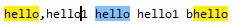
Analice las siguientes preguntas : ¿Por qué hello1 no puede coincidir con el patrón regular "hello\b" ?
首先\b是一个定位字符,它是零宽的,标识一个位置,这个位置的前面和这个位置的后面不能全是\w,即不能全是字母数字和下划线[A-Za-z0-9_],而hello1的o与1之间的位置前面是o后面是1,前后全是\w,不符合\b匹配的含义,因此hello1不能匹配正则表达式“hello\b”。
但是bhello可以匹配“hello\b”这个正则,因为hello的结尾的位置,前面是o,后面是空白,所以符合\b匹配的含义,因此bhello可以匹配“hello\b”这个正则。
6、自定义字符集合
方括号[ ]表示字符集合,即[ ]表示自定义集合,用[ ]可以匹配方括号里的任意一个字符。
regex=[aeiou]匹配“a”,“e”,“i”,“o”,“u”任意一个字符,也就是可以匹配集合[aeiou]的任意一个字符。
需要注意,特殊字符(除了小尖角“^”和中划线“-”外)被包含到方括号中,就会失去特殊意义,只代表其字符本身。
regex=[abc+*?]匹配“a”,“b”,“c”任意一个字符或者“+”,“*”,“?”,即包含在自定义集合中的特殊字符“+”,“*”,“?”失去了特殊含义,只表示其字符本身的意思。
特殊字符小尖角“^”,原本含义是匹配字符串的开始位置,如果包含在自定义集合[ ]中,则表示取反的意思。
比如:regex=[^aeiou]匹配“a”,“e”,“i”,“o”,“u”之外的任意一个字符。
中划线“-”,在自定义集合[ ]中,表示“范围”,而不是字符“-”本身,regex=[a-z],匹配从a到z中26个字母的任意一个。
除小数点“.”外,标准字符集合包含在方括号中,仍然表示集合范围。
regex=[\d.+]匹配0-9的任意一个数字或者小数点“.”或者加号“+”
也就是说\d在自定义集合中仍然表示数字,但是小数点在字符集合中只表示小数点本身,而不是除“\r\n”之外的任何单个字符。
7、选择符和分组
| 表达式 | 作用 |
| pattern1|pattern2 | 或的关系,匹配左边的pattern1或右边的pattern2 |
| (pattern) | 匹配pattern并获取这一匹配,并存储 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是不进行存储 |
regex=x|y,匹配字符x或y。
( )表示捕获组,( )的作用如下:
1、括号中的表达式可以作为整体被修饰,用来表示匹配括号中表达式的次数
regex=(abc){2,3},可以匹配连续的2个或3个abc,如下:

2、括号中的表达式匹配到的内容会存储起来,并可以获取到括号中表达式匹配到的内容
3、每一对括号会分配一个编号,使用( )的捕获根据左括号的顺序从1开始自动编号,编号为0的捕获是整个正则表达式匹配到的文本。
捕获组( )可以把匹配的内容存储起来,那么如何获取( )捕获到的内容呢,下面介绍反向引用。
8、反向引用“\number”
每一对括号会分配一个编号,使用( )的捕获根据左括号的顺序从1开始自动编号。通过反向引用,可以对分组已捕获的字符串进行引用。
“\number”中的number就是组号。
regex=(abc)d\1可以匹配字符串abcdabc,即\1表示把获取到的第一组再匹配一次,如下:

(?:pattern)表示非捕获组,匹配括号中表达式匹配到的内容,但是不进行存储匹配到的内容。这在使用 "或" 字符 (|) 来组合一个正则的各个部分是很有用的。
例如:匹配字符“story”或者“stories”,regex=stor(?:y|ies)就是一个比 regex=story|stories更简略的表达式。
9、预搜索(零宽断言)
预搜索,又叫零宽断言,又叫环视,它是对位置的匹配,与定位字符(边界字符)类似。
| 表达式 | 作用 |
| (?=pattern) | 断言此位置的后面能匹配表达式pattern |
| (?<=pattern) | 断言此位置的前面能匹配表达式pattern |
| (?!pattern) | 断言此位置的后面不能匹配表达式pattern |
| (?<!pattern) | 断言此位置的前面不能匹配表达式pattern |
regex=love (?=story)匹配的结果如下(匹配“love ”后面是story):

regex=love (?!story)匹配的结果如下(匹配“love ”后面不能是story):

10、运算符的优先级
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
La siguiente tabla está ordenada por prioridad de mayor a menor.
| operador | describir |
| \ | Personaje de escape |
| (), (?:), (?=), [] | Paréntesis y corchetes, agrupaciones y colecciones personalizadas |
| *, +, ?, {n}, {n,}, {n,m} | Caracteres calificativos (cuantificadores) |
| ^, $, caracteres estándar, caracteres | Personajes ancla (personajes límite) y personajes. |
| | | o |
Nota: La operación "|" tiene la prioridad más baja, que es inferior a la prioridad de los caracteres normales.
Por lo tanto, regex=r|loom coincide con "r" o "loom", de la siguiente manera:
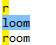
Si desea hacer coincidir "habitación" o "telar", utilice paréntesis para crear una subexpresión, regex=(r|l)oom, de la siguiente manera:
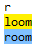
Finalmente, me gustaría presentarles el proceso de uso de expresiones regulares en el desarrollo:
1. Analizar las características de los datos que se compararán y simular varios datos de prueba;
2. Utilice herramientas habituales para escribir expresiones regulares y combínelas con datos de prueba para verificar la expresión regular que escribió;
3. Llame a la expresión regular que se ha verificado en la herramienta normal del programa.
Aquí recomiendo a todos una herramienta normal " RegexBuddy ", que puede descargarla de Internet o responder a la palabra clave " expresión regular " en segundo plano para obtenerla.
Hasta ahora se ha introducido la sintaxis de las expresiones regulares, ¿la dominas? Ven y pruébala.