
Para las empresas, la arquitectura sin servidor tiene un enorme potencial de aplicación. Con la mejora de los productos en la nube, la mejora de la integración de productos y las capacidades de integración y la mejora de las capacidades de automatización del proceso de entrega de software, creemos que bajo la arquitectura sin servidor, la agilidad empresarial tiene el potencial de aumentar 10 veces. Este intercambio se divide principalmente en los siguientes cuatro aspectos:
1. ¿Los desafíos de DevOps y cómo reducir el costo de implementación de DevOps?
2. ¿Por qué la ausencia de servidor es un resultado inevitable del desarrollo de la nube?
3. Sin servidor + DevOps =?
Cuatro, compartir casos reales
1. Desafíos de DevOps
Desafíos de DevOps
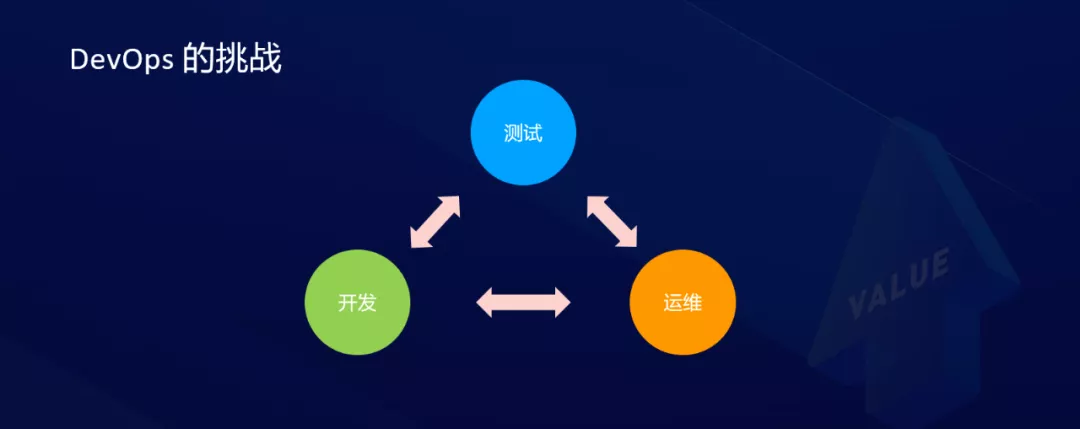
Para todo el proceso de entrega de aplicaciones, generalmente hay tres vínculos involucrados, a saber, desarrollo, prueba y operación y mantenimiento, que en las estructuras organizacionales tradicionales, a menudo corresponden a tres equipos diferentes. Cada uno de estos tres enlaces tiene su propio enfoque, pero en realidad, para que todo el proceso de entrega de la aplicación sea fluido y eficiente, y para mantener la aplicación en un estado de alta disponibilidad después de su lanzamiento, a menudo se requieren tres equipos para interactuar entre sí. El muro de la existencia se rompió.
El muro aquí no solo es un obstáculo provocado por el alejamiento de la estructura organizativa, sino también por el enfoque diferente de las tres áreas. Por ejemplo, el desarrollo debe prestar atención a la capacidad de prueba, la operación y el mantenimiento. Estas cosas afectarán profundamente el diseño de la arquitectura y el desarrollo de la aplicación. Si el desarrollador no considera completamente la capacidad de prueba del código, causará muchos problemas. Los grandes problemas, como cómo implementar la inyección de fallas y el control de flujo fino, deben considerarse claramente durante el desarrollo.
Lo mismo ocurre con la operación y el mantenimiento. Al desarrollar, también debe considerar la operatividad. Por ejemplo, al desarrollar, debe considerar cómo hacer que el servicio sea fluido y no perder datos cuando el servicio está realmente fuera de línea. Al mismo tiempo, este diseño también es Debe estar profundamente conectado con el sistema de operación y mantenimiento, para que pueda conectarse de manera muy confiable y segura, y mejorar la eficiencia de la operación y el mantenimiento.
Muchas fallas internas en Alibaba también son causadas por la inconsistencia de la información en el diseño entre el desarrollo y la operación y el mantenimiento. Por ejemplo, se garantizan tres copias de alta confiabilidad durante el desarrollo y el diseño, pero en el lado de la operación y el mantenimiento, puede pensar que la copia está ubicada. La máquina no proporcionó servicios y estaba fuera de línea por error.
Por lo tanto, DevOps en realidad contiene dos significados: el primero es hacer que el desarrollo, las pruebas, la operación y el mantenimiento se conviertan en un equipo; en segundo lugar, es necesario unificar la mente de todo el equipo, que también es el verdadero desafío de DevOps.
Desarrollo de desafíos de DevOps
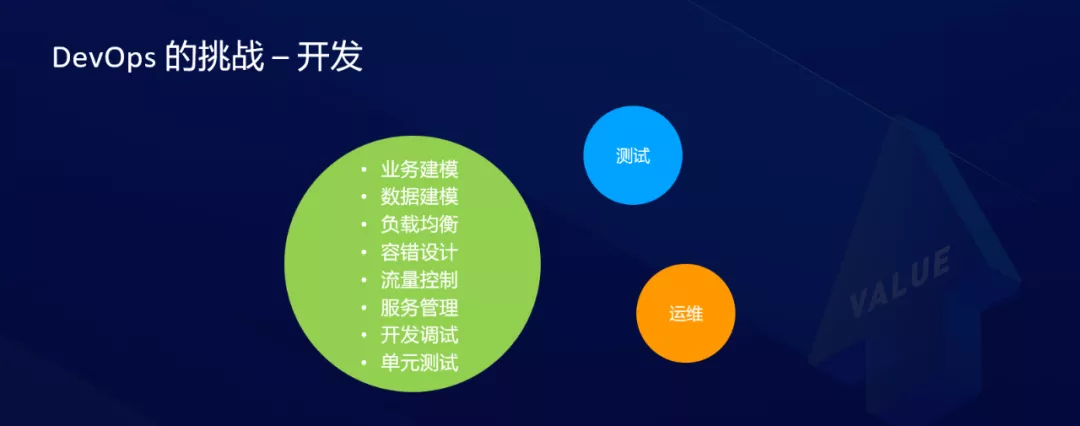
Una revisión rápida de lo que se debe considerar en cada aspecto de DevOps. En la etapa de desarrollo, primero debe clasificar los requisitos y escenarios comerciales, y convertir los requisitos en el diseño del sistema. Al mismo tiempo, debe considerar cómo está diseñado el modelo de datos para evitar que la base de datos se convierta en un solo punto y un cuello de botella. Debido a que en empresas de Internet como Alibaba, las aplicaciones conllevan una gran cantidad de visitas de usuarios, es necesario considerar el equilibrio complejo, el diseño tolerante a fallas, el control de flujo, etc.
Si se adopta una arquitectura de microservicio y la aplicación constará de varios servicios, también se debe considerar la administración de servicios. Después de todas las consideraciones anteriores, se transforma en un diseño de sistema y finalmente se lleva a cabo el desarrollo, la depuración y las pruebas unitarias, que una vez finalizadas, la aplicación puede pasar al enlace de prueba.
Pruebas de desafío de DevOps
Se deben considerar muchos aspectos y dimensiones al realizar pruebas para garantizar la calidad de todos los aspectos del software. Las pruebas incluyen pruebas de integración, pruebas E2E de extremo a extremo, pruebas de rendimiento, pruebas de estrés, pruebas de tolerancia a fallas, pruebas de compatibilidad, pruebas de destrucción, etc.

Reto de DevOps: operación y mantenimiento
Una vez que la aplicación pasa la prueba, se produce un producto. Se considera que este producto tiene la capacidad de ser lanzado, y se requieren operaciones posteriores y trabajo de mantenimiento, como el lanzamiento de la aplicación en escala de grises, la reversión de la actualización, el servidor en línea y fuera de línea y la supervisión. Alarma, actualización de parches de seguridad, configuración de red, auditoría operativa, drenaje del entorno de producción, etc.

Desafíos de DevOps: ¿cómo reducir el costo de implementación de DevOps?
Cuando analizamos los elementos de trabajo contenidos en DevOps en profundidad, podemos sentir que si queremos construir una aplicación flexible y altamente confiable, hay muchos puntos a considerar, y estos solo son necesarios después de implementar DevOps. Se ha convertido en algo que el mismo equipo debe tener en cuenta en todo el ciclo de vida de la aplicación. Esto requiere una mentalidad y una habilidad de equipo muy altas.
La canalización de entrega de aplicaciones DevOps contiene muchos enlaces. Cómo conectar estos enlaces sin problemas y darse cuenta de la automatización también es un aspecto muy importante.

Después de revisar los desafíos de DevOps, se puede ver en la práctica dentro de Alibaba y en toda la industria que la complejidad de DevOps debe reducirse a través de plataformas y herramientas.
2. Introducción a Serverless
Tendencia de la nube
Antes de presentar Serverless, primero revise la tendencia de desarrollo de la nube y luego analice por qué Serverless es el resultado inevitable del desarrollo de la nube.
En los últimos diez años, la computación en la nube ha logrado un gran desarrollo, lo que permite a los usuarios obtener fácilmente una potencia informática casi ilimitada a través de API, y estas potencias informáticas se presentan a través de máquinas virtuales Hay muchos modelos de este tipo. La ventaja es que es compatible con el entorno operativo y de desarrollo original de la aplicación.Este modo puede hacer que las aplicaciones heredadas tradicionales migren a la nube sin problemas.
La primera etapa de la nube es la cloudificación de la infraestructura, aquí está el modelo de alojamiento en la nube. Para crear aplicaciones basadas en el almacenamiento en la nube y la infraestructura de red, el valor central de este modelo radica en la elasticidad y el costo de los recursos. En la siguiente etapa, el sistema en la nube ha superado con creces a la infraestructura y podemos ver el surgimiento de muchos servicios en la nube en varios campos. Por lo tanto, hoy en día, debemos considerar cómo utilizar las capacidades de los servicios en la nube para construir aplicaciones más rápidamente construyendo bloques en lugar de reinventar ruedas Este es el modelo nativo de la nube.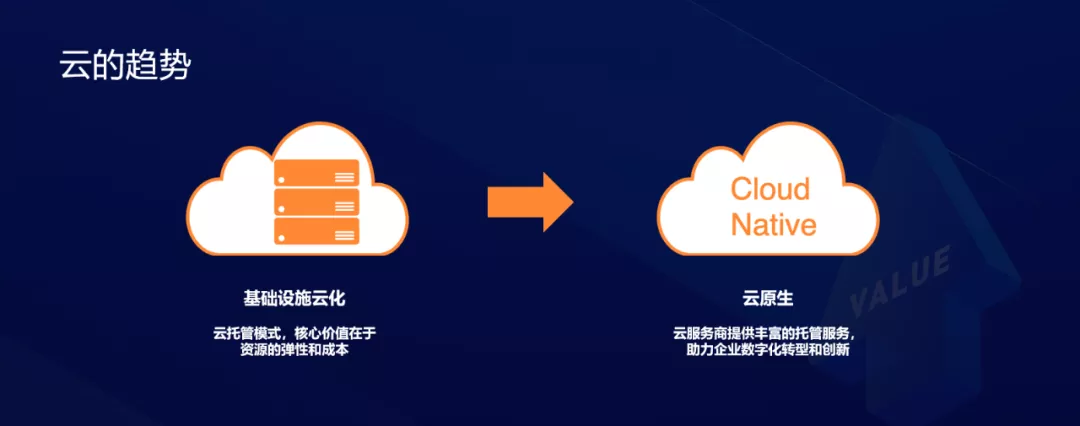
El sistema de productos en la nube se está volviendo rápidamente sin servidor
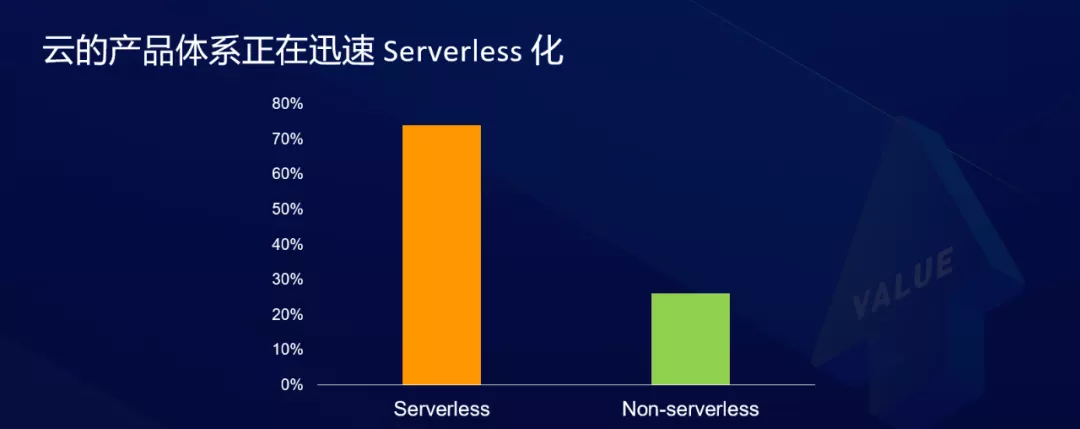
En la actualidad, los sistemas de productos de los principales fabricantes de computación en la nube se están convirtiendo rápidamente en servidores sin servidor, lo que no es una predicción del futuro, sino un hecho que realmente está sucediendo. Los datos de la figura siguiente se basan en estadísticas sobre nuevas funciones o nuevos formularios de servicio lanzados por los productos AWS, Microsoft y Alibaba Cloud. Se puede ver que la mayoría de los nuevos servicios se están volviendo sin servidor.
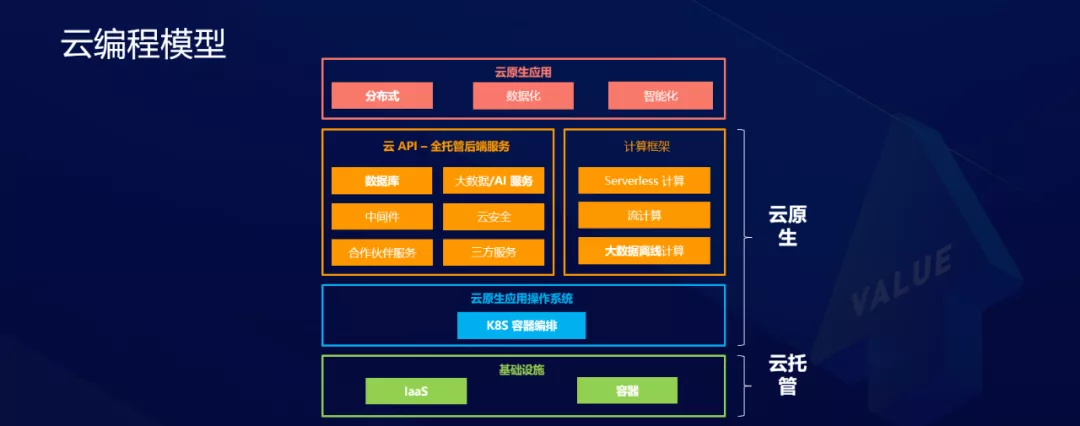
Modelo de programación en la nube
La computación en la nube ha producido una gran cantidad de servicios. Desde la perspectiva de la eficiencia, estos servicios en la nube se encuentran en una forma abstracta sin servidor de nivel superior, lo que se vuelve muy significativo. Si volvemos a examinar el sistema de productos en la nube desde la perspectiva del modelo de programación en la nube, podemos ver que la capa inferior es la capa de infraestructura, que consta de dos partes, a saber, IaaS y contenedores. Por encima de la infraestructura está el sistema operativo de aplicaciones nativo de la nube. K8s es el estándar de facto en esta capa, que puede administrar bien la infraestructura IaaS subyacente. Aparece una API muy rica en el sistema operativo, que es un sistema de servicios en la nube completamente administrado. Si observa el sistema de productos de Alibaba Cloud, encontrará que Alibaba Cloud proporciona un sistema de productos rico, que incluye bases de datos, big data y middleware, todos los cuales brindan servicios en un modelo de alojamiento completo sin servidor.
Con una cantidad tan grande de API en la nube, el problema actual es cómo diseñar un marco informático general que se pueda conectar muy de cerca con estos servicios en la nube sin servidor y API en la nube para ayudar a los clientes a crear rápidamente aplicaciones elásticas y de alta disponibilidad. Por lo tanto, la computación sin servidor aparece en la capa del marco. La razón principal de esto es que necesita tener una reacción química cercana con las API en la nube para ayudar a los usuarios a mejorar la eficiencia de la construcción, operación y mantenimiento de aplicaciones, y ayudar a los clientes a construir nuevas tecnologías distribuidas, digitales e inteligentes. Una generación de aplicaciones nativas en la nube.
Diferencias entre el alojamiento en la nube y las aplicaciones sin servidor
A continuación, se muestra una comparación de las diferencias más esenciales entre las aplicaciones alojadas en la nube y las aplicaciones sin servidor. Para las aplicaciones, el modelo de construcción se puede dividir en tres capas, a saber, la gestión de la infraestructura subyacente, la integración de servicios externos intermedios y la lógica de la aplicación superior. Si se adopta el modelo de alojamiento en la nube, la aplicación se crea en la capa de infraestructura. El nivel de abstracción de la construcción de la aplicación es relativamente bajo, por lo que supondrá mucho trabajo. Los usuarios deben integrar diferentes componentes y servicios, y muchas decisiones y La implementación y la entrega serán más lentas, se deben considerar muchas cosas y habrá mucho trabajo repetitivo en la operación y el mantenimiento.
Si los usuarios utilizan el modelo sin servidor para crear aplicaciones, lo que equivale a crear aplicaciones en la API de nivel superior, la lógica de unión y la gestión de la infraestructura están a cargo de los proveedores de servicios en la nube, y el costo de integración y toma de decisiones para los usuarios es relativamente bajo. Lo que debe tenerse en cuenta es cómo adaptar la lógica empresarial y los requisitos con los servicios en la nube para crear aplicaciones. La ventaja de crear aplicaciones basadas en API en la nube muy eficientes es que el costo de construcción es muy bajo y se puede entregar diariamente y por horas, y reducirá en gran medida la carga de la operación y el mantenimiento futuros.

¿Qué es la informática sin servidor?
La computación sin servidor tiene cuatro características: primero, no hay necesidad de mantener la infraestructura de computación en la nube, y el nivel de abstracción de la construcción de aplicaciones aumenta para volverse más eficiente; segundo, puede lograr una escala elástica en tiempo real, de modo que se puedan utilizar futuros algoritmos de detección de carga basados en datos. La realización no solo cumple con una latencia muy baja, sino que también logra una alta utilización de recursos; en tercer lugar, el modo de medición proporciona un modelo bajo demanda muy detallado, que puede lograr una medición de segundo nivel y un modelo de pago completamente bajo demanda. Para los usuarios, la utilización de recursos es del 100%; finalmente, se puede lograr una alta disponibilidad y esta capacidad está integrada en la capa de la plataforma.

Sistema de productos Alibaba Cloud Serverless
Aquí hay una explicación. La computación sin servidor es solo una parte de los productos sin servidor de Alibaba Cloud. Además, también incluye almacenamiento, API, análisis y middleware. Por lo tanto, desde este punto de vista, sin servidor no es un concepto muy nuevo. El almacenamiento de objetos OSS más antiguo es un producto sin servidor. Se puede ver que el sistema de productos en la nube se está volviendo sin servidor, pero en los últimos años ha habido un sistema sin servidor en general, como la informática funcional. A continuación, la plataforma informática puede conectar los productos del sistema sin servidor para crear una aplicación sin servidor.
Tres, DevOps sin servidor
Cuando estas capacidades sin servidor están disponibles, ¿cómo combinar estas capacidades con DevOps?
Simplifique la gestión, la operación y el mantenimiento de la infraestructura
La siguiente figura muestra más desde la perspectiva de cómo crear aplicaciones de alta disponibilidad. Aquí, los módulos de la aplicación se dividen en cuatro áreas: incluida la infraestructura, el tiempo de ejecución, los datos y las aplicaciones. La capa de infraestructura debe ocuparse de las operaciones relacionadas con la máquina, como el manejo de fallas. En tiempo de ejecución, se requieren aislamiento de recursos de la aplicación y control de flujo. La capa de datos debe estar relacionada principalmente con la base de datos y la caché, por ejemplo, cómo diseñar la estructura de la tabla de la base de datos, cómo diseñar la estrategia de la caché, cómo lograr el equilibrio de carga y cómo garantizar que no haya cuellos de botella de expansión horizontal.
En la capa de aplicación, debe ocuparse de las operaciones relacionadas con la aplicación, como errores de paquetes de código, errores de configuración y latidos anormales. La plataforma puede ocuparse completamente de la parte en el cuadro azul punteado en la figura siguiente, y los usuarios pueden no darse cuenta; el cuadro azul sólido significa que la plataforma ha ayudado a los usuarios a hacer mucho trabajo, pero el usuario aún necesita percibir y tomar ciertas decisiones; el cuadro rojo representa todavía La parte que debe gestionar el usuario. Se puede ver que en términos de tolerancia a fallas, la plataforma proporciona capacidades muy sólidas, incluida la tolerancia a desastres de múltiples zonas de disponibilidad, resiliencia rápida, capacidades de control de flujo integradas y capacidades de alarma y monitoreo de múltiples niveles y dimensiones. Con estas capacidades, la complejidad de la infraestructura de administración de usuarios se reduce en gran medida.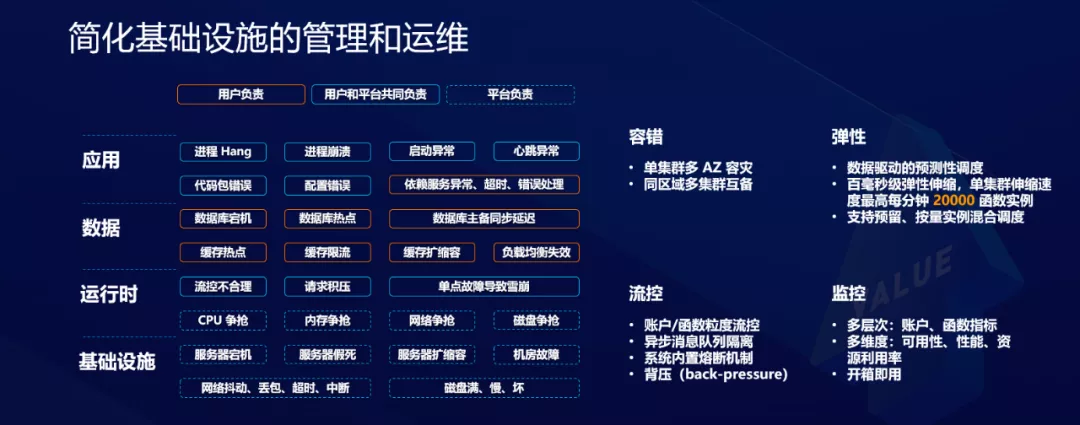
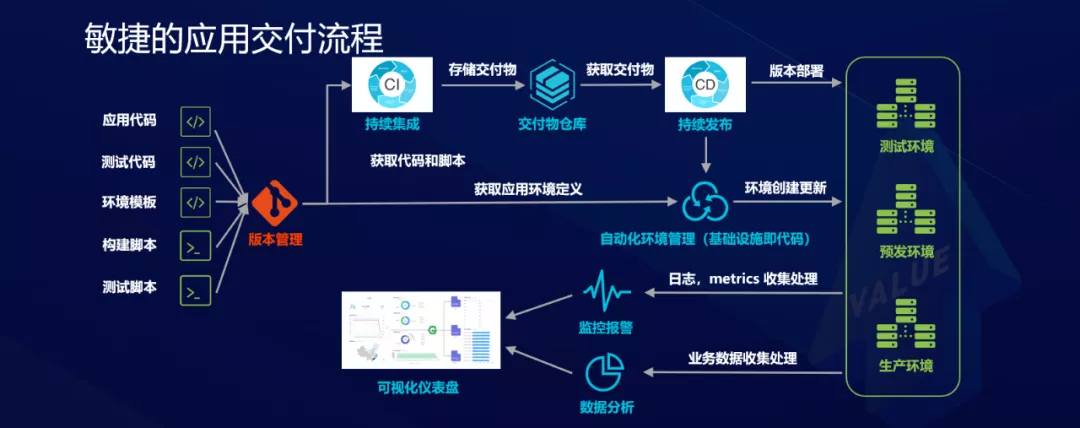
Proceso de perspectiva de aplicación ágil
La siguiente figura muestra el proceso de entrega de la aplicación. El código se almacena y administra a través de una biblioteca de códigos de administración unificada, y luego se convierte en un entregable a través de la integración continua, y luego se almacena en el almacén de entregables. El entregable puede ser una imagen de contenedor o un patrón de paquete de código. Una vez que se produce el entregable, se puede implementar automáticamente en el entorno de prueba y producción para la implementación de la versión y, finalmente, en el entorno de producción. Por lo tanto, el punto clave de este proceso de entrega de aplicaciones es lograr un alto grado de automatización, y hay dos aspectos clave de la automatización: la infraestructura, a saber, el código y la serie automatizada entre enlaces.
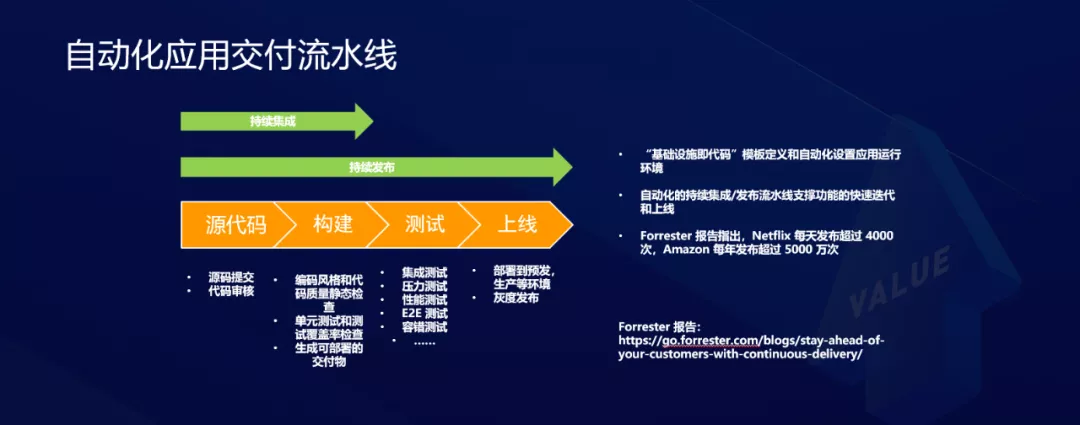
Canalización de entrega de aplicaciones automatizada
La siguiente figura muestra la canalización de entrega de aplicaciones automatizada. Puede ver que en cada uno de los siguientes enlaces, se deben implementar muchas funciones y muchas de ellas son tareas repetitivas, por lo que la infraestructura es el código.
Infraestructura como código
La siguiente figura muestra la infraestructura como código. El modelo de aplicación sin servidor define los recursos de la aplicación a través de declaraciones, lo que permite la estandarización, la automatización y la visualización.
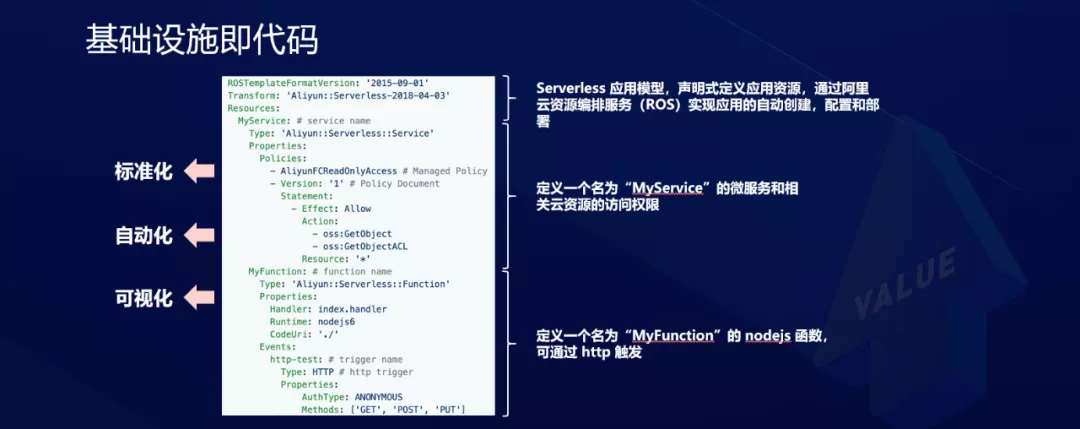
Se pueden pasar diferentes parámetros para la plantilla y el entorno de ejecución de la aplicación se puede generar dinámicamente.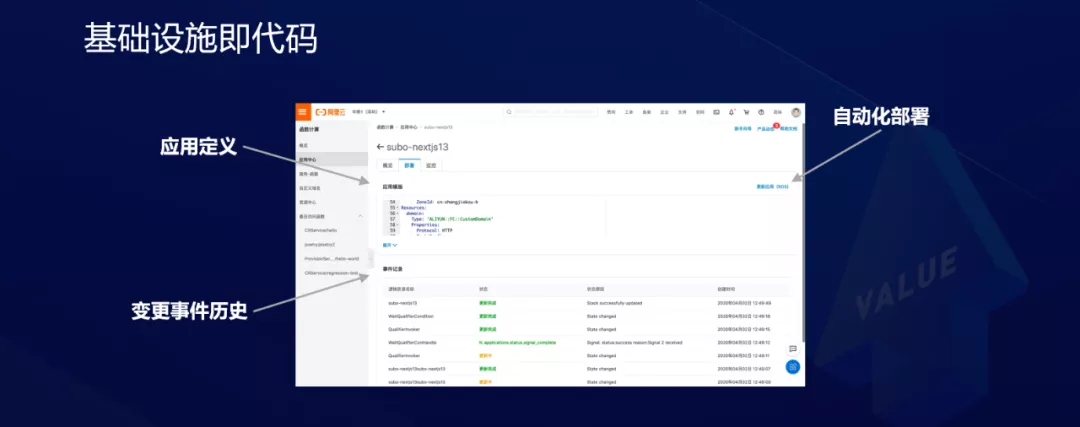
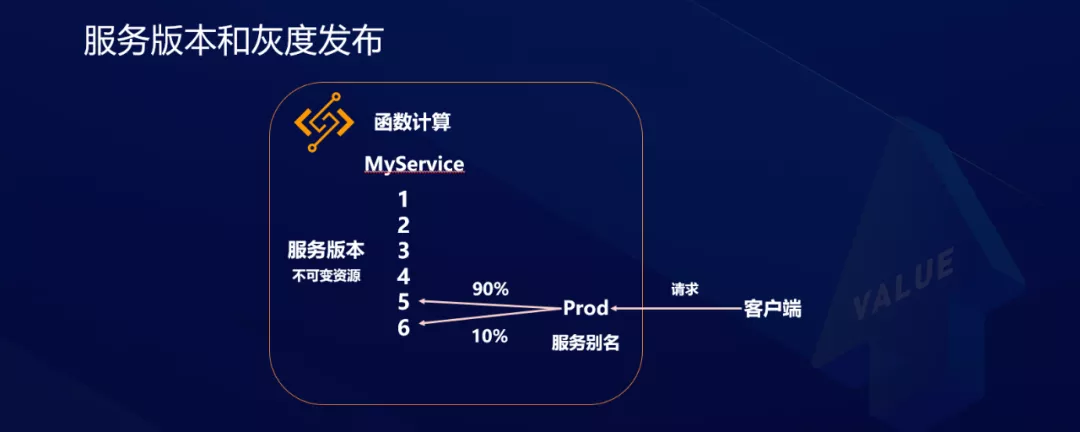
Versión de servicio y versión gris
En el cálculo de funciones, la aplicación tiene el concepto de versión. La versión es una entidad inmutable. Por lo tanto, evita que las aplicaciones en línea se dañen debido a una modificación inesperada de la versión. Alibaba Cloud evita estos problemas a través de la versión de servicio y la liberación gris. Se accede a las aplicaciones de acceso final a través de alias.
Flujo de trabajo sin servidor
Alibaba Cloud proporciona un flujo de trabajo sin servidor para facilitar a los usuarios la conexión entre DevOps. Los usuarios pueden crear rápidamente flujos de trabajo a través de capacidades de servicio y herramientas de soporte, y mostrarlos de manera visual, de modo que puedan ver claramente los efectos del flujo de trabajo.

Canalización de entrega de aplicaciones automatizada
Recuerde cómo automatizar la canalización de entrega de aplicaciones cuando estas capacidades estén disponibles. En la etapa del código fuente, se puede implementar una verificación estática de la calidad del código para garantizar la calidad del código de CheckIn. Cuando CheckIn llega al código base, automáticamente ejecutará pruebas unitarias y producirá entregables. En el proceso de prueba, la integración perfecta con Alibaba Cloud ROS puede realizar una implementación automatizada en el entorno de prueba y ejecutar casos de prueba. Una vez que se completan, la implementación se puede confirmar a través de ReleaseManager, y estas tareas se conectan en serie a través del flujo de trabajo, se lanzan al entorno previo al lanzamiento y se implementan en el entorno de producción. Cada paso está automatizado y la eficiencia de la investigación y el desarrollo se ha mejorado considerablemente.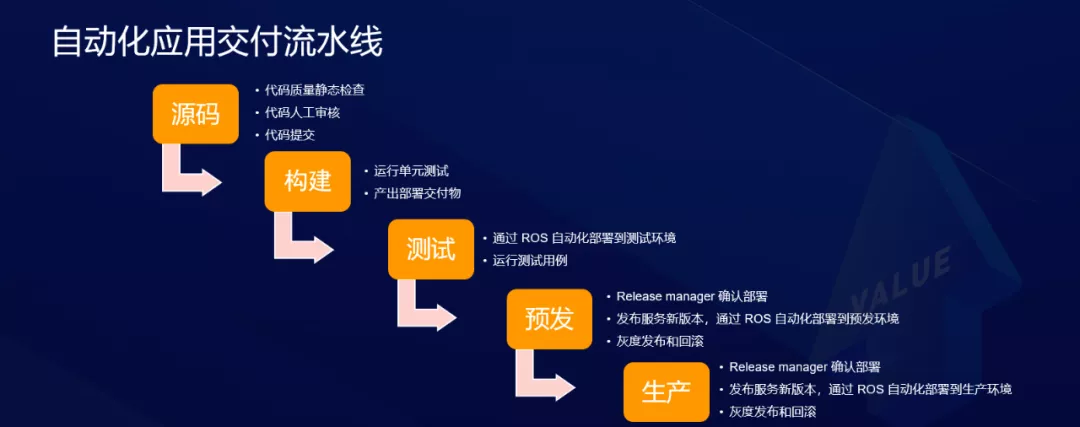
Consulta y recopilación de registros
En la plataforma informática sin servidor, se proporcionan de forma nativa una gran cantidad de funciones de recopilación de registros y recopilación de métricas, como consultas de registros simples y consultas de registros avanzadas, que pueden proporcionar a los usuarios capacidades avanzadas de análisis de datos a través de registros.
Capacidades de recopilación y visualización de métricas
Además de proporcionar vistas de indicadores básicos, la plataforma informática sin servidor también admite vistas de indicadores personalizados. Los usuarios pueden realizar análisis de datos relacionados con la empresa a través de búsquedas de índices de palabras clave personalizadas.
Cuando se combinan Serverless y DevOps, la eficiencia de I + D se puede mejorar enormemente. Por un lado, reduce en gran medida la carga mental del equipo de desarrollo; por otro lado, todo el proceso de DevOps se puede automatizar en gran medida mediante herramientas.
Cuarto, compartir casos
Finalmente, comparta algunos casos exitosos. La informática sin servidor de Alibaba es compatible con la plataforma del programa Alibaba Economy Mini, lo que ahorra un 40% de los recursos de I + D. Alibaba Cloud Serverless admite el uso de la computación funcional de Yuque para implementar servicios computacionalmente intensivos como documentos, lo que reduce en gran medida los costos de operación y mantenimiento, y también reduce los costos de operación y mantenimiento de los documentos de grafito en un 58%, lo que ayuda a Weibo a mejorar la eficiencia de la investigación y el desarrollo y a hacer funciones en línea. El tiempo ha cambiado de las 2 semanas originales a unas pocas horas.
Se puede ver que en 2020 la aceptación de la industria de Serverless ha mejorado enormemente y, al mismo tiempo, las capacidades de Serverless se han vuelto más universales.
Sobre el Autor:
Yang Haoran (no enojado), el jefe de computación sin servidor, se unió a Alibaba Cloud en 2010 y estuvo profundamente involucrado en todo el proceso de investigación y desarrollo de sistemas distribuidos de Alibaba Cloud Feitian e iteración de productos. Tener un conocimiento profundo de la computación distribuida a gran escala, el almacenamiento y el procesamiento de datos a gran escala.
Enlace original
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.