1. Idea de algoritmo
QLearning es un algoritmo basado en valores en algoritmos de aprendizaje por refuerzo Q significa que en un determinado entorno, Q (estado, acción) realiza la acción a (a∈A) en el estado s (s∈S) en un momento determinado. Para la expectativa de obtener ingresos, el entorno retroalimentará la recompensa correspondiente r (puntuación) de acuerdo con las acciones del agente.
Por lo tanto, la idea principal del algoritmo es construir una tabla Q de estado y acción para almacenar el valor Q, y luego seleccionar la acción que puede obtener el mayor beneficio en función del valor Q.

2. Ejemplos y fórmulas básicas

Ejemplo : Comenzar desde el punto de partida y llegar al círculo final es una victoria-puntos extra, y un triángulo es una derrota-deducciones. La primera ronda es una caminata aleatoria, hasta que haya una puntuación, será seguida por una alta probabilidad.
- Agente-cubo
- Entorno (entorno): se simula en forma tk
- Recompensa: la puntuación de recompensa y castigo por la acción.
- Acción arriba, abajo, izquierda y derecha
El problema se puede resumir en un proceso de decisión de Markov.
Cada cuadrícula se considera un estado s
q (a | s) es
la probabilidad de realizar una acción a en el estado s p (s '| s, a) es la probabilidad de elegir una acción para pasar al siguiente estado s' en el estado s
R (s '| s, a) representa la recompensa de realizar la acción ay pasar al estado s'in s
El objetivo es encontrar una estrategia que pueda llegar al final para obtener la máxima recompensa y obtener la fórmula de máxima recompensa:
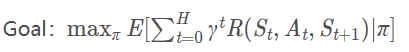
La principal ventaja de Qlearning es el uso de 时间差分法TD (una combinación de Monte Carlo y programación dinámica) para realizar el aprendizaje fuera de línea y el uso de ecuaciones de Bellman para resolver la estrategia óptima para el proceso de Markov.
Ver: método de diferencia horaria
Fórmula central :
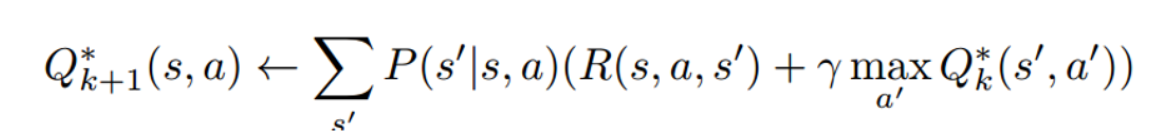
Actualización oficial :
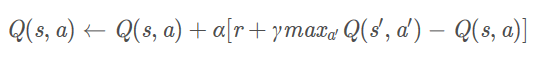
Código de núcleo:
import numpy as np
import random
from environment import Env
from collections import defaultdict
class QLearningAgent:
def __init__(self, actions):
# actions = [0, 1, 2, 3]
self.actions = actions # 动作
self.learning_rate = 0.01 # 学习率
self.discount_factor = 0.9 # 折扣因子
self.epsilon = 0.1 # [ˈepsɪlɒn]
self.q_table = defaultdict(lambda: [0.0, 0.0, 0.0, 0.0])
# 采样 <s, a, r, s'>
def learn(self, state, action, reward, next_state):
current_q = self.q_table[state][action]
# 贝尔曼方程更新
new_q = reward + self.discount_factor * max(self.q_table[next_state])
self.q_table[state][action] += self.learning_rate * (new_q - current_q)
# 从Q-table中选取动作
def get_action(self, state):
if np.random.rand() < self.epsilon:
# 贪婪策略随机探索动作
action = np.random.choice(self.actions)
else:
# 从q表中选择
state_action = self.q_table[state]
action = self.arg_max(state_action) # 选组最大效益动作
return action
# 选取最大分数
@staticmethod
def arg_max(state_action):
max_index_list = []
max_value = state_action[0]
for index, value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
if __name__ == "__main__":
env = Env() # 初始化tk窗口
agent = QLearningAgent(actions=list(range(env.n_actions))) # 初始化物体实例
for episode in range(1000):
state = env.reset()
while True:
env.render()
# agent产生动作
action = agent.get_action(str(state))
next_state, reward, done = env.step(action)
# 更新Q表 -- 核心更新公式
agent.learn(str(state), action, reward, str(next_state))
state = next_state
env.print_value_all(agent.q_table)
# 当到达终点就终止游戏开始新一轮训练
if done:
break
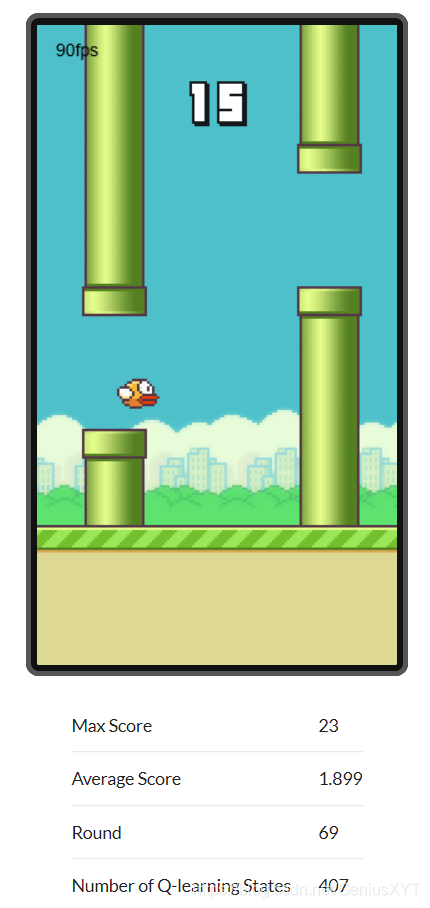
Otro ejemplo de aprendizaje Q: Flappy Bird (Flying Bird)
Ejemplo de aprendizaje Q: Flappy Bird