Algoritmo BF
El algoritmo BF (fuerza bruta), es decir, el algoritmo de fuerza bruta, es un algoritmo de coincidencia de patrones de cadena ordinario, el algoritmo BF es un algoritmo de fuerza bruta
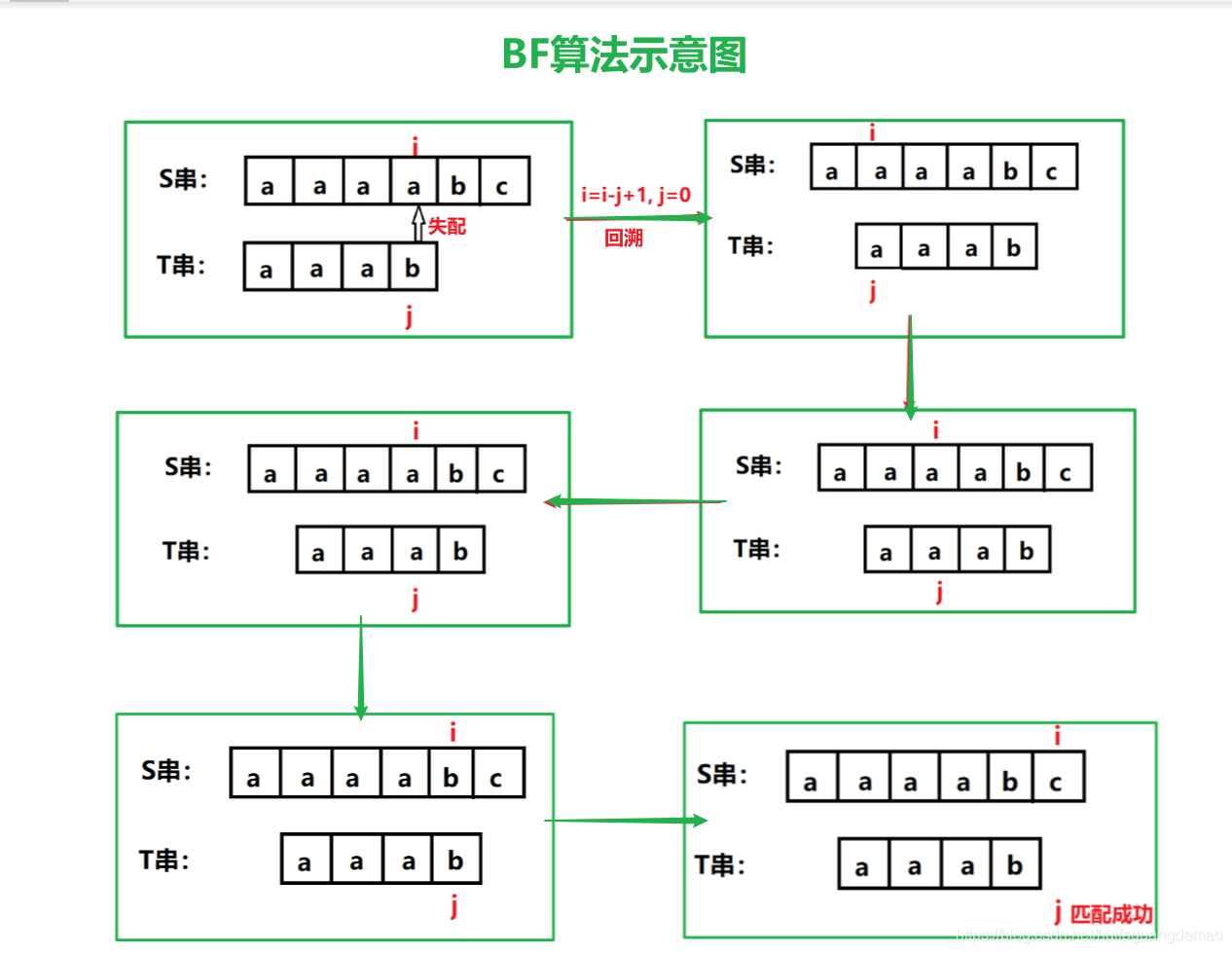
La idea del algoritmo BF es hacer coincidir el primer carácter de la cadena de destino S (cadena principal) con el primer carácter de la cadena de patrón T (subcadena). Si son iguales, continúe comparando el segundo carácter de S con el primer carácter de T. Dos caracteres; si no son iguales, compare el segundo carácter de S con el primer carácter de T , y compárelos sucesivamente hasta obtener el resultado final coincidente
La eficiencia del algoritmo BF no es alta, porque cada vez que no se encuentra, la cadena principal debe retroceder a la siguiente posición desde el inicio anterior.
Algoritmo BF complejidad temporal O (m * n) complejidad espacial O (1)
El diagrama del algoritmo BF es el siguiente:
El código C es el siguiente:
//返回 子串T 在 主串S 中第pos个字符之后的位置
//时间复杂度:O(m*n) 空间复杂度:O(1)
int BF(const char* S, const char *T,int pos) //S主串,T子串
{
if (S == NULL || T == NULL || pos < 0 || pos >= strlen(S))
{
return -1;
}
int i = pos;
int j = 0;
int len1 = strlen(S);//主串长度
int len2 = strlen(T);//子串长度
while(i<len1&&j<len2)
{
if (S[i] == T[j])
{
i++;
j++;
}
else
{
/*回退到本次开始的下一个位置(i-j+1),j回退到0*/
i = i - j + 1;
j = 0;
}
}
if (j >= len2) //子串走完即为查找成功
return i - j ;
else
return -1;
}
La eficiencia del algoritmo BF no es alta y la complejidad del tiempo es O (m * n) . Cada vez que falla la coincidencia, el cursor de la cadena principal i debe retroceder a la siguiente posición al comienzo del tiempo actual, y el cursor de la subcadena j debe retroceder a 0. El algoritmo KMP mejora el retroceso de i y j, evita retrocesos innecesarios, mejora la eficiencia y reduce la complejidad del tiempo a O (m + n)
Algoritmo KMP
El algoritmo KMP es un algoritmo de coincidencia de cadenas mejorado, propuesto por DEKnuth, JHMorris y VRPratt, tomando la primera letra de su apellido es el algoritmo KMP. El núcleo del algoritmo KMP es utilizar la información después de la falla de coincidencia para minimizar el número de coincidencias entre la cadena del patrón y la cadena principal para lograr el propósito de una coincidencia rápida
Algoritmo KMP complejidad temporal O (m + n) complejidad espacial O (n)
En el algoritmo BF, cada vez que hay una discrepancia, el cursor de la cadena principal i debe retroceder a i-j + 1, y el cursor de la subcadena j debe retroceder a 0
Pero, de hecho, cuando hay un desajuste, puede hacer que i no retroceda y j retroceda a la posición de retirada. Como se muestra en el diagrama del algoritmo BF en la siguiente figura, después del primer desajuste, i se retrocede a i-j + 1, j Retrocediendo a 0, pero podemos encontrar que en la comparación posterior, i ha regresado a la posición anterior y la posición de j ha cambiado (el cuadro rojo en la figura siguiente)
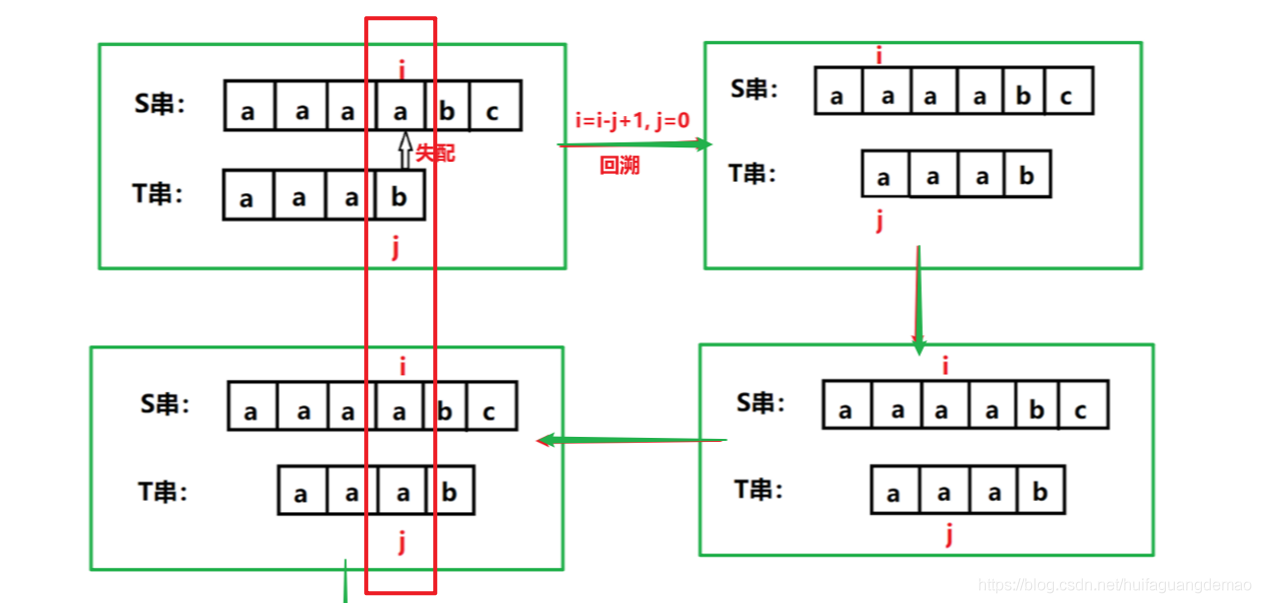
El algoritmo KMP es permitir que el cursor de la cadena principal i no se retire cuando hay una falta de coincidencia, y usar la información fallida anteriormente para devolver el cursor de la subcadena j a una posición adecuada
Entonces, la clave es encontrar la posición donde el cursor de la subcadena j debería retroceder después de la falta de coincidencia Usamos una siguiente matriz para almacenar la posición de j correspondiente a cada posición de la subcadena.
Copie el código del algoritmo BF anterior directamente, modifique la parte posterior de i, j para completar el marco del algoritmo KMP
int KMP(const char* S, const char *T,int pos) //S主串,T子串
{
if (S == NULL || T == NULL || pos < 0 || pos >= strlen(S))
{
return -1;
}
int i = pos;
int j = 0;
int len1 = strlen(S);//主串长度
int len2 = strlen(T);//子串长度
while(i<len1&&j<len2)
{
if (S[i] == T[j])
{
i++;
j++;
}
else//修改i,j的回退
{
//i不回退
//j要退到k
}
}
if (j >= len2) //子串走完即为查找成功
return i - j ;
else
return -1;
}
La siguiente tarea es encontrar la posición k donde se retira j, es decir, encontrar la siguiente matriz
Encuentra la siguiente matriz
Conocimientos previos: prefijo y sufijo de cadena
Prefijo: una subcadena que comienza con el primer carácter.
Prefijo verdadero: una subcadena que comienza con el primer carácter, pero sin incluir la cadena original en sí.
Sufijo: una subcadena que termina con el último carácter. Sufijo
verdadero: una subcadena que termina con el último carácter, pero sin incluir la cadena original.
Ejemplo:
prefijo ababc : a, ab, aba, abab, ababc
Prefijo verdadero: a, ab, aba, abab
Sufijo: c, bc, abc, babc, ababc Sufijo
verdadero: c, bc, abc, babc
En el siguiente ejemplo, se

produce una falta de coincidencia cuando i es 4 y j es 4, pero encontramos que el sufijo verdadero de la cadena S y el prefijo verdadero de la cadena T antes de la falta de coincidencia son iguales , y no es necesario comparar las partes iguales . Simplemente continúe la comparación (como se muestra en la figura a continuación), es decir, j retrocede hasta la parte posterior de la cadena igual, es decir, el subíndice j se convierte en la longitud de la cadena igual , por lo que la clave es encontrar la longitud k de la cadena igual para cada desajuste
Y debido a que en la primera comparación, los cuatro caracteres antes de la cadena S que no coinciden y la cadena T son correspondencia uno a uno e iguales, el sufijo verdadero de la cadena S también es el sufijo verdadero de la cadena T, por lo que k es la cadena T antes de la discrepancia. El valor de longitud cuando el prefijo verdadero y el sufijo verdadero de la cadena son iguales.

Por lo tanto, el método para encontrar el valor de k es: encuentre el prefijo verdadero igual y el sufijo verdadero antes de la discrepancia de subcadena, la longitud es k o se puede describir de la siguiente manera:
Encuentre las dos subcadenas verdaderas iguales más largas antes de la discrepancia de subcadenas, estas dos subcadenas verdaderas cumplen las siguientes características:
1. Una cadena comienza con el primer carácter
2. La otra cadena termina con el último carácter antes de la discrepancia
k es La longitud de la verdadera subcadena
El valor k correspondiente a cada carácter de la cadena T en el ejemplo anterior es el siguiente:
estipulación: siguiente [0] = - 1, siguiente [0] = 0
| Patrón de cuerda T cuerda | un | segundo | un | segundo | C |
|---|---|---|---|---|---|
| siguiente | -1 | 0 | 0 | 1 | 2 |
Nota : También hay una representación de matriz siguiente de uso común, next [0] pone 0, next [1] es 1, cada valor de k subsiguiente es 1 más grande que la tabla anterior, pero las ideas del algoritmo son las mismas, dos O bien, para facilitar la codificación, aquí se utiliza el método next [0] = -1
El valor de la siguiente matriz se puede calcular manualmente, el siguiente paso es usar el programa para encontrar la siguiente matriz:
- Para cualquier cadena, se puede determinar que next [0] = -1, next [1] = 0;
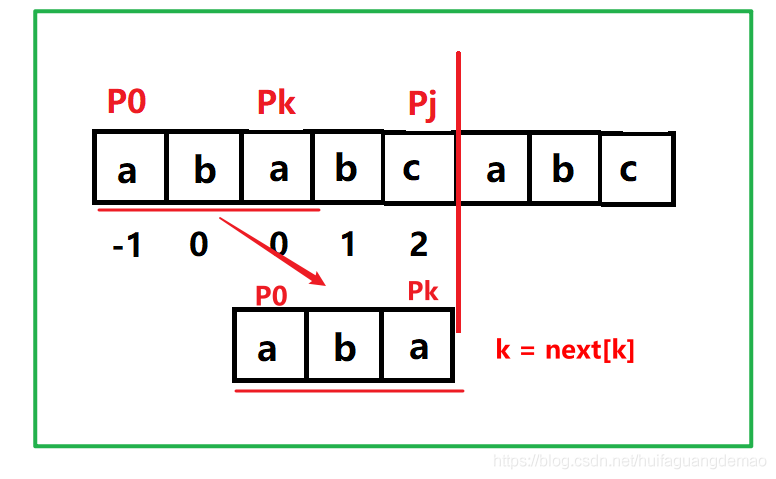
- Suponga que next [j] = k, es decir, la longitud del prefijo verdadero y el sufijo verdadero de la cadena antes del subíndice j es igual a k, es decir, P0 ... Pk-1 == Pj-k ... Pj-1, encuentre siguiente [j + 1]
- Caso 1: Si Pk == Pj, entonces P0 ... Pk-1Pk = Pj-k ... Pj-1Pj, es decir, cuando el prefijo verdadero y el sufijo verdadero correspondientes a j + 1 son iguales, el valor es k + 1, es decir, siguiente [j + 1 ] = k + 1
- Caso 2: Si Pk! = Pj, como se muestra en la figura siguiente, ponga P0 ... Pk debajo de Pk ... Pj, entonces la idea anterior se usará nuevamente, el cursor de la cadena principal j no se mueve y el cursor de la subcadena k regresa al valor apropiado La posición del cursor de la subcadena k se ha calculado antes, que es siguiente [k], por lo que k se devuelve a siguiente [k], es decir, k = siguiente [k] , y luego Pk se compara con Pj, por lo que Repita hasta que Pk == Pj o k de regreso a -1, k de regreso a -1 significa que no hay un prefijo verdadero y un sufijo verdadero iguales, luego al siguiente [j + 1] se le puede asignar un valor de 0, o al siguiente [j + 1] = k +1, que también es el beneficio de poner -1 en el primer valor k de la siguiente matriz
- Código C para la siguiente matriz:
static void GetNext(const char* T,int * next) //根据子串T获取它的next数组(用来存放所有的k值)
{
int lenT = strlen(T);
next[0] = -1;
next[1] = 0;
int j = 1;
int k = 0;
while (j + 1 < lenT)
{
if (T[k] == T[j] || k == -1 )//Pk==Pj,k为-1就没必要回退了
{
/*
next[j + 1] = k + 1;
j++;
k++;
*/
next[++j] = next[++k];
}
else//Pk != Pj
{
k = next[k];//主串游标j不动,子串游标k往回退
}
}
}
En este punto, se ha calculado la siguiente matriz, es decir, el cursor de la cadena principal no se mueve y se ha calculado la posición del cursor de la subcadena j. Finalmente, j = siguiente [j] se coloca bajo la condición de desajuste, y se completa el algoritmo KMP, el algoritmo KMP El código C completo es el siguiente:
static void GetNext(const char* T, int * next); //声明获取next数组的函数
int KMP(const char* S, const char *T, int pos) //S主串,T子串
{
if (S == NULL || T == NULL || pos < 0 || pos >= strlen(S))
{
return -1;
}
int i = pos;
int j = 0;
int len1 = strlen(S);//主串长度
int len2 = strlen(T);//子串长度
int *next = (int *)malloc(len2 * sizeof(int));
GetNext(T, next);//求next数组
while (i < len1&&j < len2)
{
if (S[i] == T[j] || j==-1)
{
i++;
j++;
}
else
{
//i不回退
j = next[j];//j回退到k
}
}
free(next);
if (j >= len2) //子串走完即为查找成功
return i - j;
else
return -1;
}
static void GetNext(const char* T, int * next) //根据子串T获取它的next数组(用来存放所有的k值)
{
int lenT = strlen(T);
next[0] = -1;
next[1] = 0;
int j = 1;
int k = 0;
while (j + 1 < lenT)
{
if (T[k] == T[j] || k == -1)//Pk==Pj,k为-1就没必要回退了
{
/*
next[j + 1] = k + 1;
j++;
k++;
*/
next[++j] = next[++k];
}
else//Pk != Pj
{
k = next[k];//主串游标j不动,子串游标k往回退
}
}
}