1. Información general
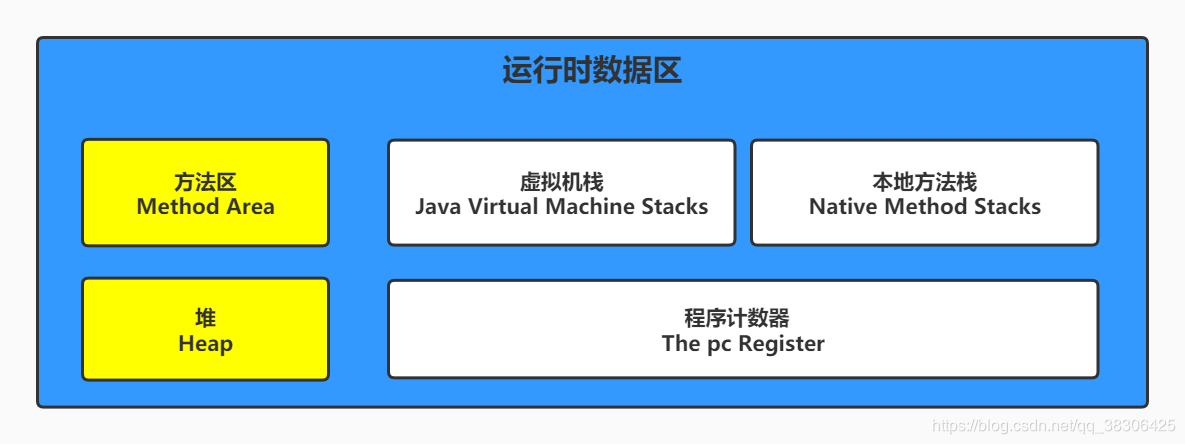
La JVM se centra en almacenar datos en el área del montón y del método (no del montón), por lo que el diseño de la memoria también se centra en
estas dos áreas (tenga en cuenta que estas dos áreas son compartidas por subprocesos).
Para la pila de la máquina virtual, la pila del método local y el contador del programa son todos privados de subprocesos.
Se puede entender que el área de datos en tiempo de ejecución de JVM es una especificación y el modelo de memoria de JVM es la implementación de la especificación.
2. Área de montón y método (no montón)
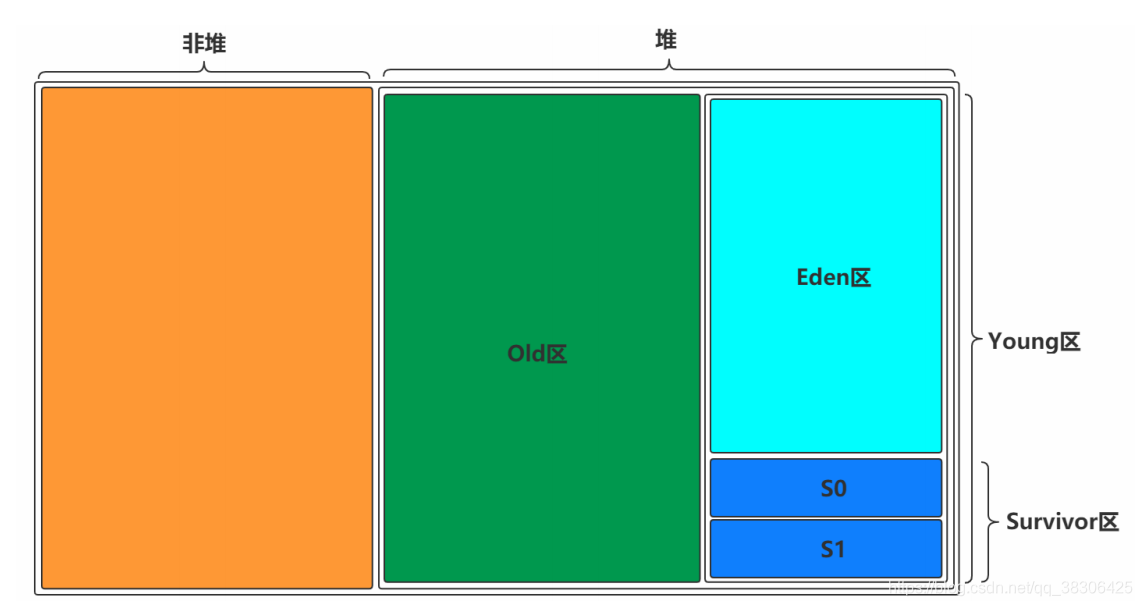
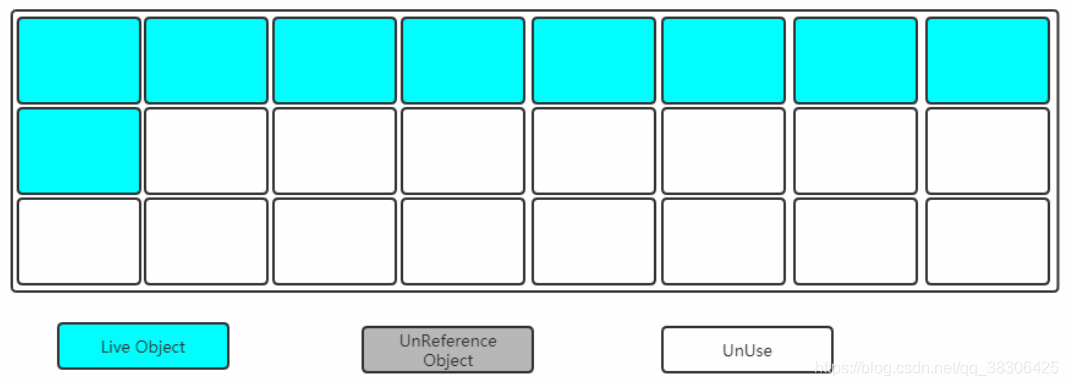
Uno es el área que no es del montón (área de método), el otro es el área del montón. El montón se divide en dos bloques, uno es el área Viejo, el otro es el área Joven y el Joven se divide en dos bloques, uno es el área Superviviente (S0 + S1) y el otro es el área Edén. S0 tiene el mismo tamaño que S1 y también se puede llamar desde y hasta
2.1 Proceso de creación de objetos
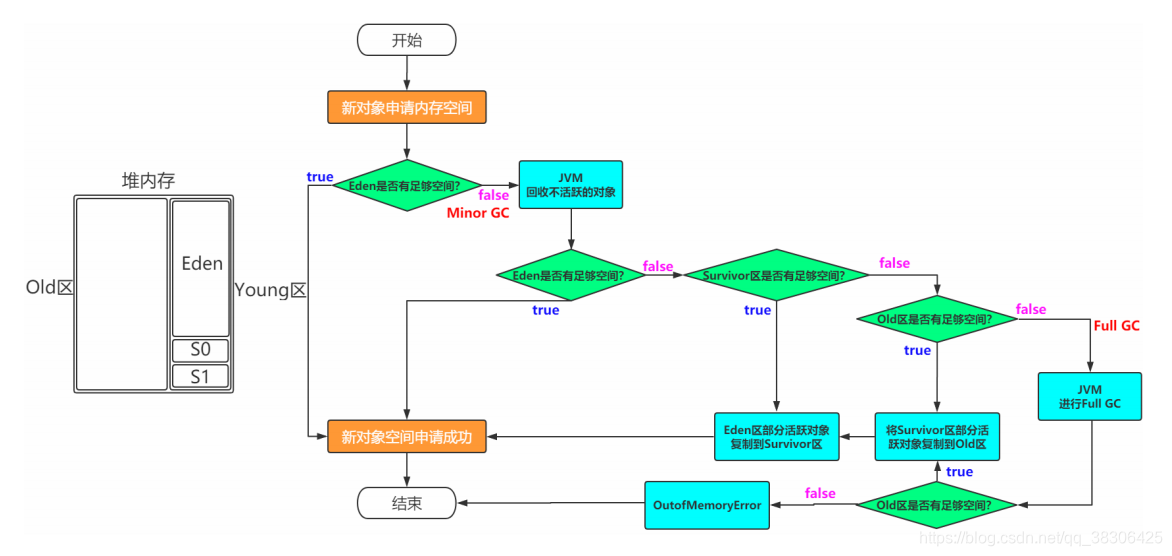
En general, los objetos recién creados se asignarán al área del Edén, y algunos objetos grandes especiales se asignarán directamente al área Antigua (mecanismo de garantía).
Soy un objeto común de Java. Nací en el área del Edén. En el área del Edén, también vi a un hermano pequeño que se parecía a mí. Jugamos en el área del Edén durante mucho tiempo. Un día había demasiada gente en el área de Edén y me vi obligado a ir al área "De" del área de Survivor. Desde que fui al área de Survivor, comencé a desviarme. A veces, en el área "De" de Survivor, hay Cuando estaba en el área "Para" de Survivor, no tenía un hogar permanente. Hasta que cumplí los 18 años, mi padre dijo que yo era un adulto y que debía ir a la sociedad para irrumpir en el mundo. Entonces fui a la generación anterior, en la generación anterior hay mucha gente y son bastante viejos.
2.2 Explicación detallada de cada área de la memoria dinámica
| nombre | Introducción |
|---|---|
| Distrito Viejo | La zona Vieja, también conocida como la vejez, almacena una gran cantidad de objetos longevos o grandes que superan el tamaño de la zona Joven mediante un mecanismo de garantía. |
| Distrito joven | El área de Young también se conoce como la nueva generación, que almacena objetos recién creados y objetos que no se han creado durante mucho tiempo. El área de Young se divide en el área de Edén y el área de Supervivientes (S0 + S1). El área de Edén almacena objetos recién creados y el área de Supervivientes almacena Objetos que han sido GC al menos una vez |
3. Preguntas frecuentes
Cómo entender la GC menor / mayor / completa
Minor GC: nueva generación
Major GC: antigua generación
Full GC: nueva generación + antigua generación + non-heap, porque la antigua generación GC está vinculada a non-heap GC
¿Por qué se necesita el área de Supervivientes? ¿No es solo el Edén?
Sin Survivor, cada vez que se realice una GC menor en el área del Edén, los objetos sobrevivientes se enviarán a la generación anterior. De esta manera, la generación anterior se llena rápidamente, activando Major GC (porque Major GC suele ir acompañada de Minor GC, que también puede considerarse que activa la Full GC).
El espacio de memoria de la generación anterior es mucho más grande que el de la nueva generación y lleva mucho más tiempo realizar un GC completo que el GC menor.
¿Cuál es la desventaja del tiempo de ejecución prolongado?
El GC completo frecuente consume mucho tiempo, lo que afectará la velocidad de ejecución y respuesta de programas grandes. Podría decir, luego aumentar o disminuir el espacio de la vejez. Si se aumenta el espacio de la vejez, más objetos supervivientes pueden llenar la vejez. Aunque la frecuencia de Full GC se reduce, a medida que aumenta el espacio de la generación anterior, una vez que se produce Full GC, la ejecución llevará más tiempo. Si se reduce el espacio de la generación anterior, aunque se reduce el tiempo necesario para la GC completa, la generación anterior se llena rápidamente de objetos activos y aumenta la frecuencia de la GC completa. Por lo tanto, la importancia de Survivor es reducir los objetos enviados a la generación anterior, reduciendo así la ocurrencia de Full GC. La preselección de Survivor garantiza que solo se enviarán los objetos que puedan sobrevivir en la generación joven después de 16 Minor GC. Vejez.
¿Por qué necesitamos dos zonas de supervivientes?
La mayor ventaja es que resuelve la fragmentación. En otras palabras, ¿por qué no funciona un área de Superviviente? En la
primera parte, sabemos que se debe configurar el área de Superviviente. Suponiendo que solo hay un área de Superviviente, simulemos el proceso: el
objeto recién creado está en el Edén. Una vez que el Edén está lleno, se activa un GC menor y los objetos supervivientes en el Edén se moverán al área de Supervivientes. Esto continúa en bucle. La próxima vez que Eden está lleno, surge el problema. En este momento, se realiza Minor GC. Eden y Survivor tienen algunos objetos supervivientes. Si los objetos supervivientes en el área de Eden están colocados en el área de Superviviente en este momento, es obvio que este La memoria ocupada por las dos partes del objeto no es continua, lo que conduce a la fragmentación de la memoria.
Un espacio de Superviviente siempre está vacío, y el otro espacio de Superviviente no vacío no tiene fragmentos.
¿Por qué Eden: S1: S2 8: 1: 1 pertenece a la nueva generación?
Memoria disponible en la nueva generación: la memoria utilizada por el algoritmo de copia para garantizar es 9: 1.
El área Eden: S1 es 8: 1
, es decir, Eden: S1: S2 = 8: 1: 1 en la nueva generación.
Las máquinas virtuales comerciales modernas son Usando este algoritmo de recopilación para recuperar la nueva generación, una investigación especial de IBM muestra que alrededor del 98% de los objetos de la nueva generación están "muriendo".
¿Están todas las áreas compartidas por subprocesos en la memoria de pila?
De forma predeterminada, JVM abre un área de búfer en Eden para cada subproceso para acelerar la asignación de objetos, llamado TLAB, nombre completo: búfer de asignación local del subproceso.
El objeto se asignará primero en la TLAB, pero el espacio de la TLAB suele ser relativamente pequeño. Si el objeto es relativamente grande, todavía se asigna en el área compartida.
4. Recolección de basura (recolección de basura)
Hay recolecciones de basura en la memoria del montón, como Minor GC en el área Young, Major GC en el área Old, Full GC en el área Young y Old area.
Pero para un objeto, ¿cómo determinar que es basura? ¿Necesita ser reciclado? ¿Cómo reciclarlo?
Aún necesitamos explorar estos temas en detalle.
Debido a que Java es una gestión automática de la memoria y la recolección de basura para hacer, y si no entiendo el conocimiento de todos los aspectos de la recolección de basura, si hay problemas que
tengo son difíciles de solucionar y resolver, la recolección de basura automática es encontrar objetos en el montón de Java y objetos Clasificación y discriminación,
averigüe los objetos que están en uso y los que ya no están en uso, y luego elimine del montón los que no se usarán.
4.1 ¿Cómo determinar que un objeto es basura?
Para realizar la recolección de basura, primero debe saber qué tipo de objeto es basura.
4.1.1 Método de recuento de referencia
Para un objeto, siempre que la aplicación tenga una referencia al objeto, significa que el objeto no es basura. Si un objeto no tiene ningún puntero, es basura.
Desventajas: si AB tiene referencias entre sí, nunca se puede reciclar.
4.1.2 Análisis de accesibilidad
A través del objeto de GC Root, comience a mirar hacia abajo para ver si un objeto es accesible a
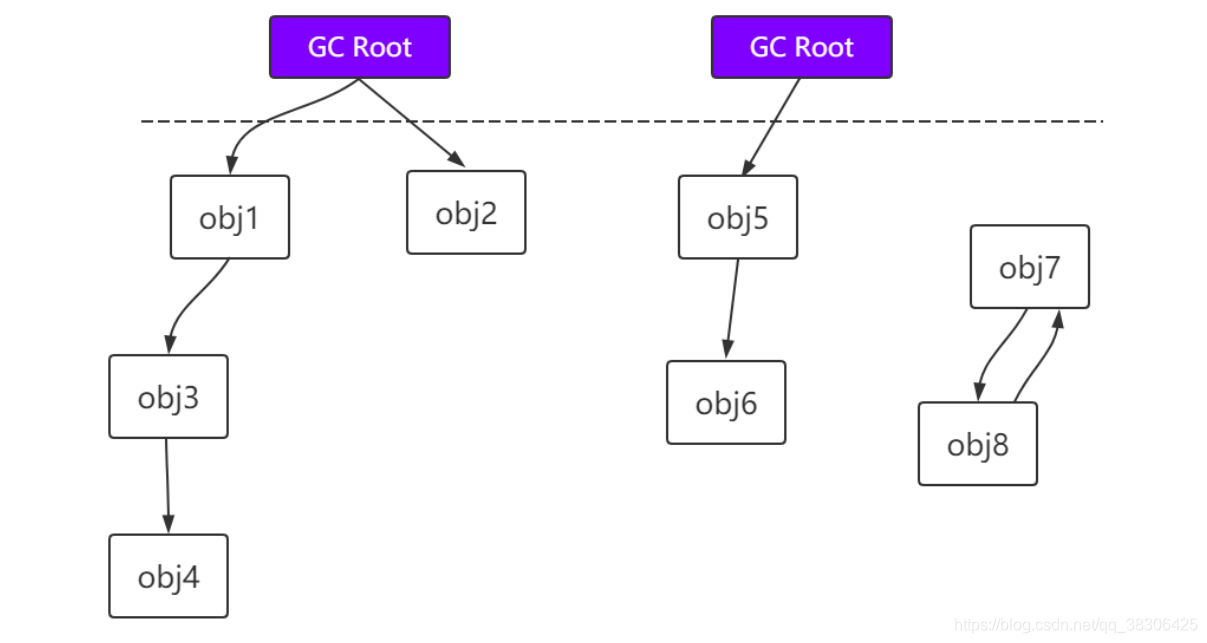
GC Root (no es un objeto, sino una referencia al objeto):
1. El objeto al que se hace referencia en la pila de la máquina virtual (tabla de variables locales en el marco de la pila).
2. El objeto al que hace referencia la propiedad estática de la clase en el área de métodos.
3. Objetos referenciados por constantes en el área de métodos.
4. El objeto al que hace referencia JNI (el método nativo en general) en la pila de métodos nativos.
4.2 ¿Cuándo se recogerá la basura?
La JVM completa automáticamente la GC, según el entorno del sistema JVM, por lo que la sincronización es incierta.
Por supuesto, podemos realizar la recolección de basura manualmente, como llamar al método System.gc () para notificar a la JVM que realice una recolección de basura, pero el
tiempo específico de la operación no se puede controlar. Es decir, System.gc () solo le informa que debe reciclar y la JVM decide cuándo reciclar
. Sin embargo, no se recomienda llamar manualmente a este método porque GC consume más recursos.
Escenario
1. Cuando el área Eden o el área S no es suficiente,
2. El espacio de la generación anterior no es suficiente,
3. El espacio del área del método no es suficiente
4. System.gc ()
4.3 Algoritmo de recolección de basura
4.3.1 Barrido de marcas
Marcar:
descubre los objetos en la memoria que necesitan ser reciclados y márcalos
En este momento, todos los objetos del montón se escanearán una vez, de modo que se puedan determinar los objetos que necesitan reciclarse, lo que lleva mucho tiempo.

Limpiar:
Limpiar los objetos marcados para reciclar y liberar el espacio de memoria correspondiente.
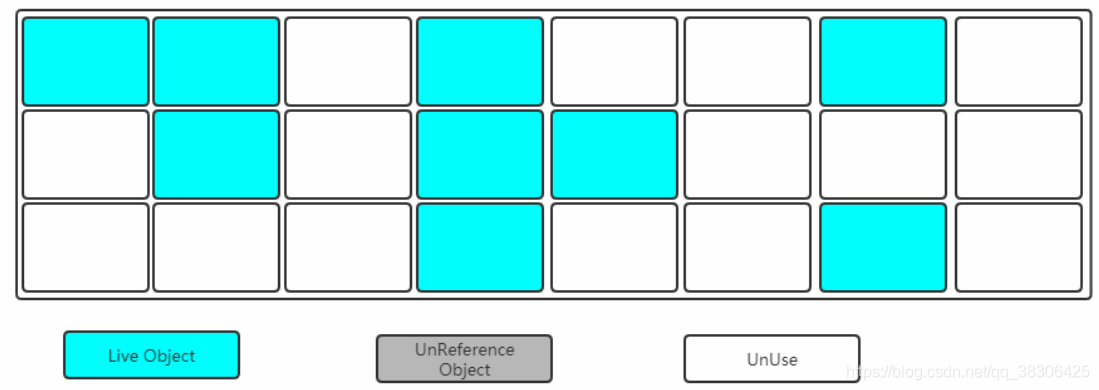
Desventajas:
1. Tanto el proceso de marcado como el de borrado requieren mucho tiempo y son ineficientes
. 2. Se generará una gran cantidad de fragmentos de memoria discontinuos y habrá demasiados fragmentos de espacio. Puede causar que cuando sea necesario asignar un objeto más grande durante la ejecución del programa, no se pueda encontrar suficiente memoria continua y deba activarse otra acción de recolección de basura por adelantado.
4.3.2 Copia de marcas
Divida la memoria en dos áreas iguales, usando solo una de ellas a la vez, como se muestra en la siguiente figura:
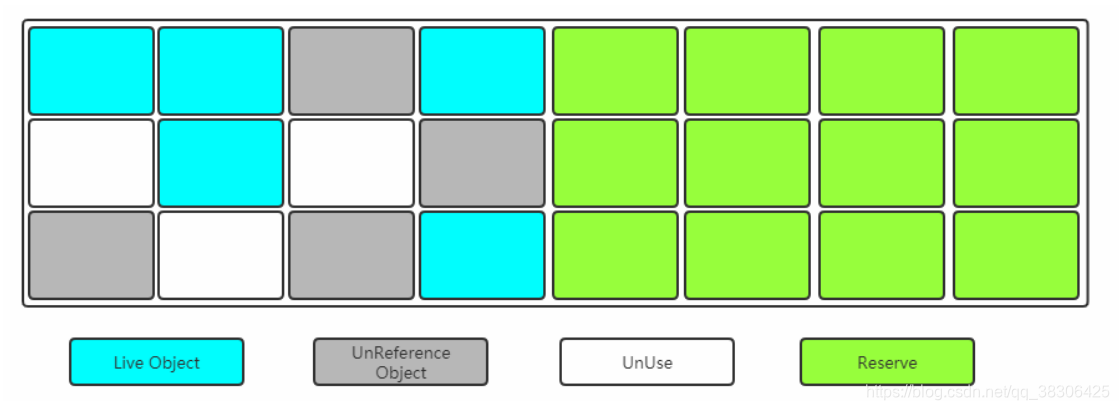
Cuando una de las memorias se agote, copie los objetos supervivientes en la otra y luego use el espacio de memoria usado una vez Quitar.
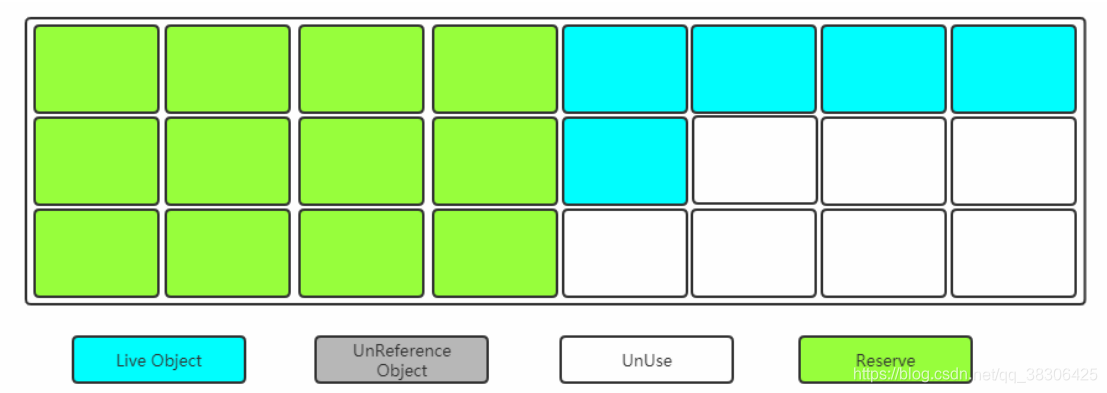
Desventajas: uso
reducido del espacio.
4.3.3 Mark-Compact
El algoritmo de recopilación de replicación realizará más operaciones de replicación cuando la tasa de supervivencia del objeto sea alta y la eficiencia será menor. Más importante aún, si
no desea desperdiciar el 50% del espacio, necesita tener espacio adicional para las garantías de asignación para hacer frente a
la situación extrema de que todos los objetos en la memoria utilizada tienen un 100% de supervivencia, por lo que la generación anterior generalmente no puede elegir directamente esto. algoritmo.
El proceso de marcado sigue siendo el mismo que el algoritmo de "marcado-barrido", pero los pasos posteriores no son para limpiar directamente los objetos reciclables, sino para mover todos los objetos supervivientes a un extremo y luego limpiar directamente la memoria fuera del límite final.
De hecho, el proceso anterior tiene un "área reservada" menos en comparación con el "algoritmo de copia".
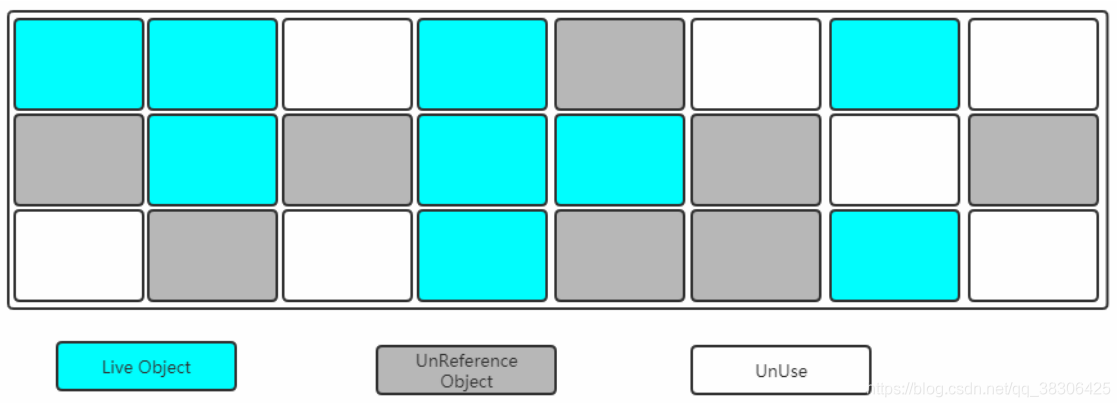
Deje que todos los objetos supervivientes se muevan hacia un extremo y limpie los recuerdos inesperados en el límite.
4.3.4 Algoritmo de recopilación generacional
1. Área joven: algoritmo de replicación (después de que se asigna el objeto, el ciclo de vida puede ser relativamente corto y la eficiencia de copia del área joven es relativamente alta)
2. Área antigua: eliminación de marcas o clasificación de marcas (los objetos del área antigua tienen un tiempo de supervivencia más largo, copia y copia No es necesario, es mejor marcar y limpiar)
4.4 Recolector de basura
Si el algoritmo de recolección es la metodología de recuperación de memoria, entonces el recolector de basura es la implementación específica de la recuperación de memoria.
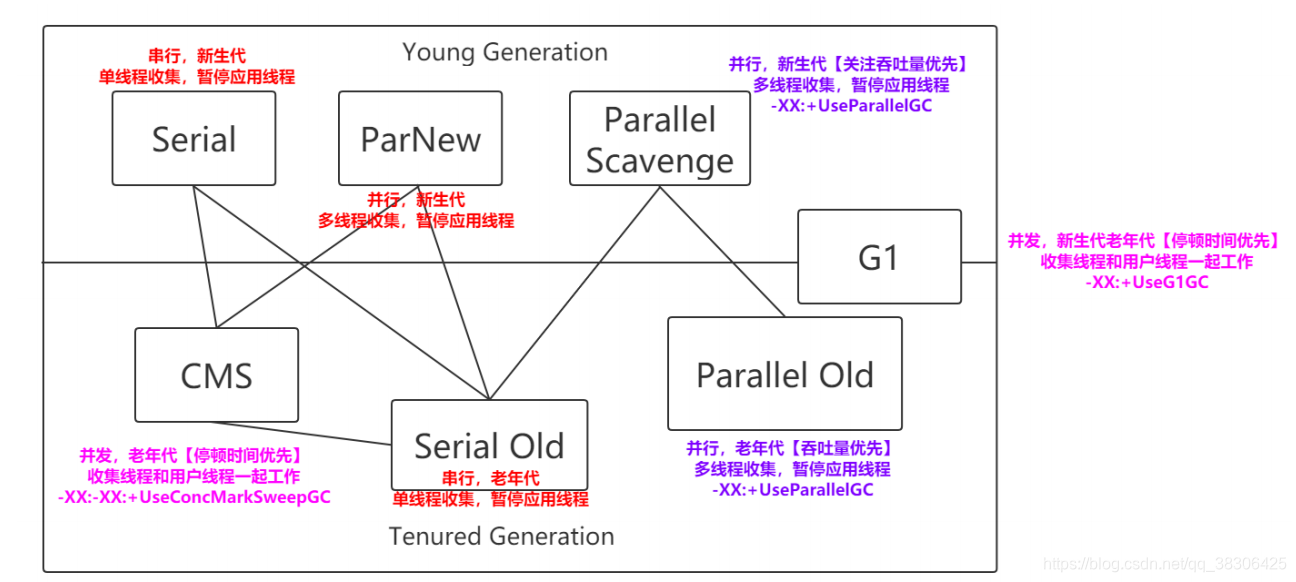
4.4.1 Serie
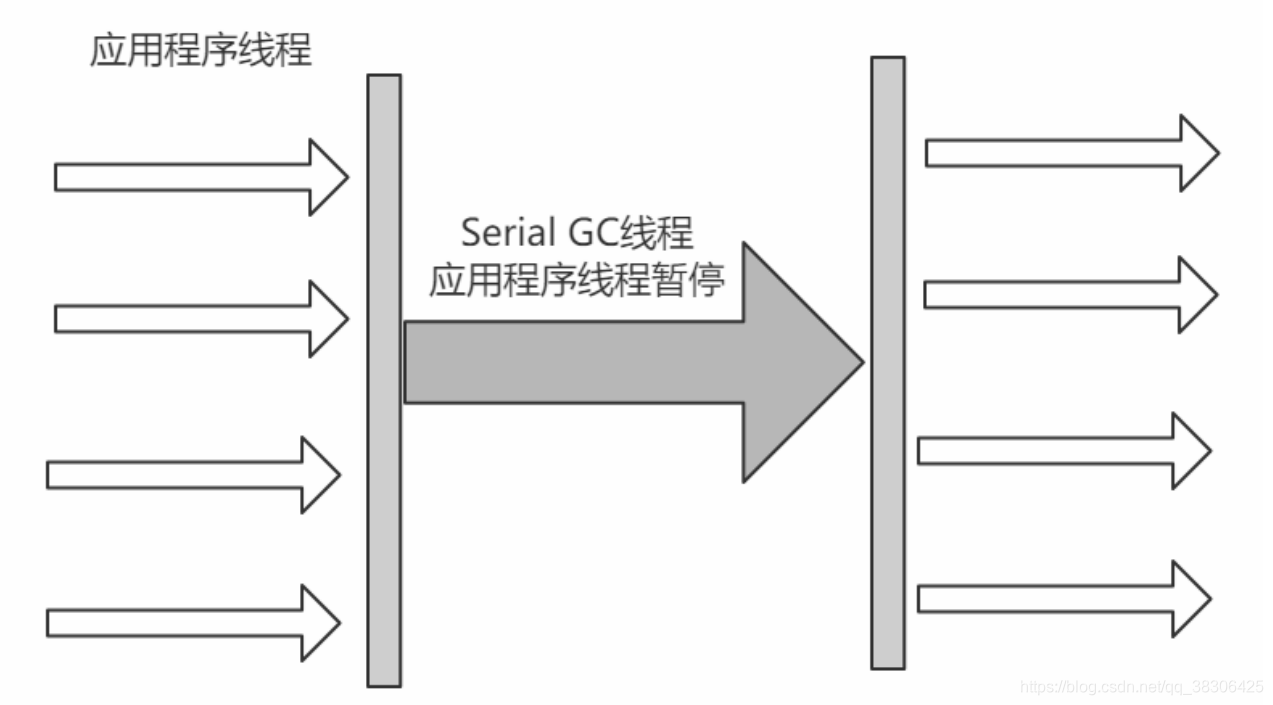
El recopilador en serie es el recopilador más básico con el historial de desarrollo más largo. Solía ser (antes de JDK1.3.1) la única
opción para la nueva generación de recopilación de máquinas virtuales .
Es un recolector de un solo subproceso, lo que no solo significa que solo usará una CPU o un subproceso de recolección para completar la recolección de basura, sino que, lo que es más importante, necesita suspender otros subprocesos durante la recolección de basura.
Ventajas: simple y eficiente, con alta eficiencia de recopilación de un solo subproceso.
Desventajas: todos los subprocesos deben detenerse durante el proceso de recopilación.
Algoritmo: algoritmo de copia. Ámbito de
aplicación: nueva generación. Aplicación: recopilador de nueva generación predeterminado en modo Cliente
4.4.2 Serial Antiguo
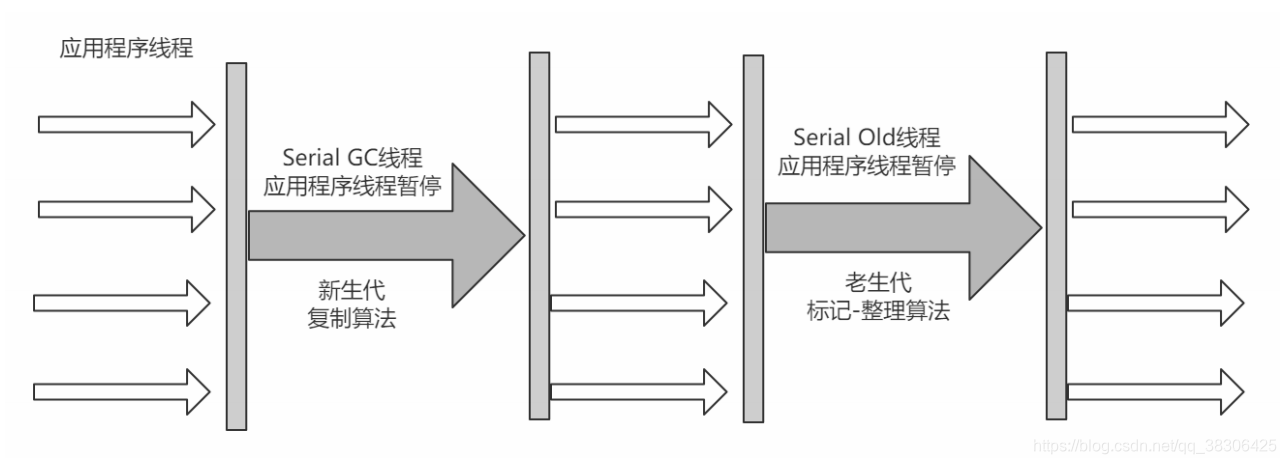
El colector Serial Old es la versión antigua del colector Serial, y también es un colector de un solo subproceso. La diferencia es que usa el "algoritmo de marcar y ordenar
", y el proceso de operación es el mismo que el del colector Serial.
4.4.3 ParNew
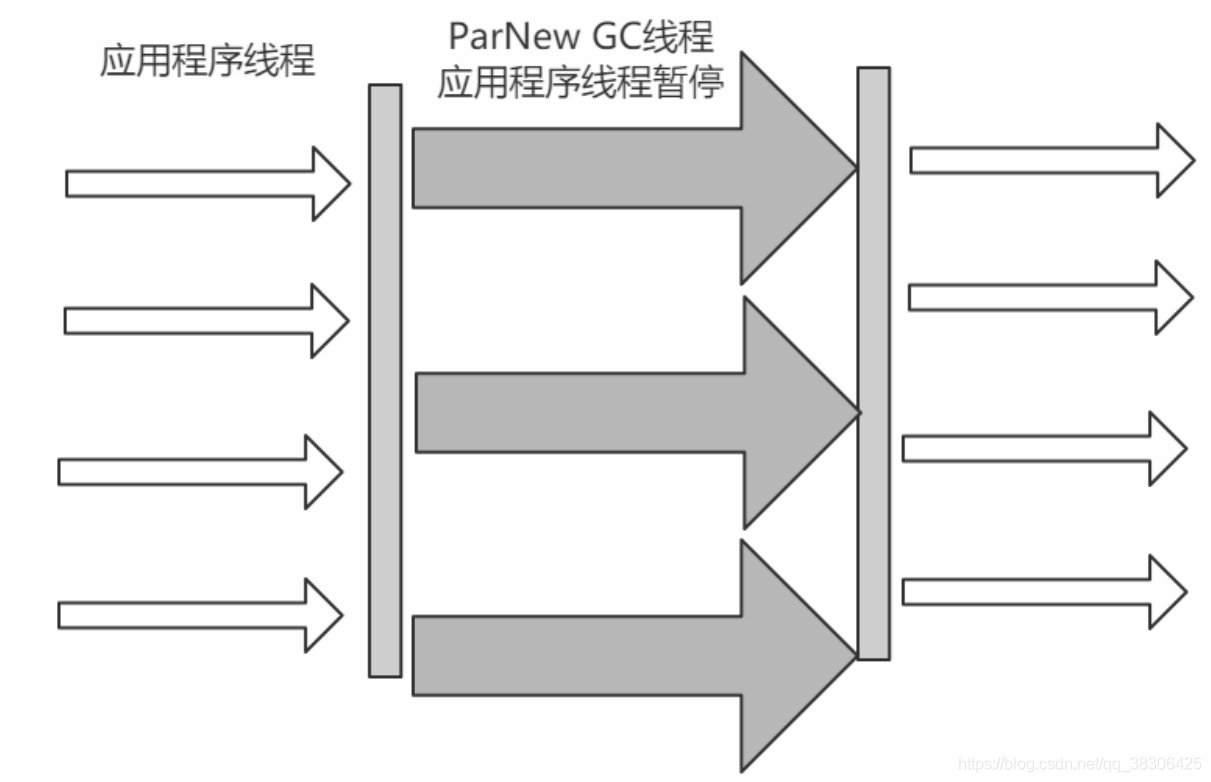
Este recopilador puede entenderse como una versión multiproceso del recopilador serial.
Ventajas: Cuando hay varias CPU, es más eficiente que Serial.
Desventajas: el proceso de recopilación suspende todos los subprocesos de la aplicación, que es menos eficiente que Serial cuando se usa una sola CPU.
Algoritmo: Algoritmo de copia
Alcance aplicable:
Aplicación de nueva generación: El recopilador de nueva generación preferido en máquinas virtuales que se ejecutan en modo Servidor
4.4.4 Barrido paralelo
El recopilador Parallel Scavenge es un recopilador de nueva generación. También es un recopilador que utiliza un algoritmo de replicación. También es un recopilador paralelo de múltiples subprocesos. Tiene el mismo aspecto que ParNew, pero Parallel Scanvenge presta más atención al rendimiento del sistema.
Rendimiento = tiempo para ejecutar el código de usuario / (tiempo para ejecutar el código de usuario + tiempo de recolección de basura) Por
ejemplo, la máquina virtual se ejecuta durante 100 minutos en total y el tiempo de recolección de basura es de 1 minuto, rendimiento = (100-1) / 100 = 99% .
Si el rendimiento es mayor, significa que el tiempo de recolección de basura es más corto y el código de usuario puede hacer un uso completo de los recursos de la CPU y completar las
tareas computacionales del programa lo antes posible .
-XX: MaxGCPauseMillis controla el tiempo máximo de pausa de recolección de basura,
-XX: GCRatio establece directamente el tamaño del rendimiento.
4.4.5 Antiguo paralelo
El recopilador Parallel Old es la versión anterior del recopilador Parallel Scavenge. Utiliza un algoritmo de subprocesos múltiples y marcar y ordenar para la recolección de basura
y presta más atención al rendimiento del sistema.
4.4.6 CMS
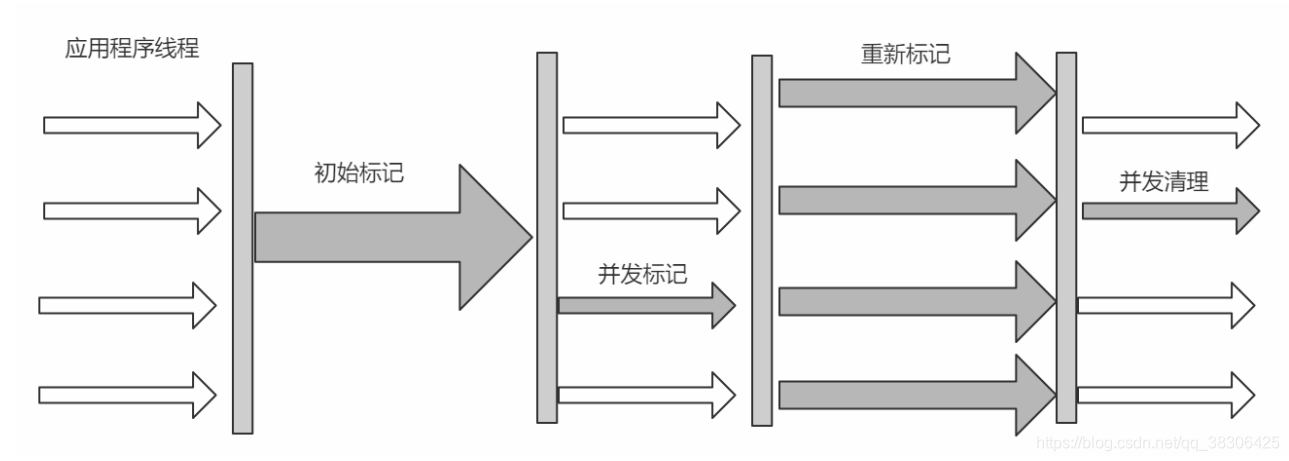
El recopilador CMS (Concurrent Mark Sweep) es un recopilador que tiene como objetivo obtener el tiempo de pausa de recuperación más corto . CMS utiliza un algoritmo de barrido de marcas. Debido a la marca concurrente y el borrado concurrente en todo el proceso, el subproceso del recopilador puede trabajar con el subproceso del usuario. Por lo tanto, en general, el proceso de recuperación de memoria del recopilador de CMS se ejecuta al mismo tiempo que el subproceso del usuario. de.
- Marca inicial Marca inicial de CMS Marca GC Roots para asociar directamente objetos sin Tracing, que es muy rápido.
- Marque simultáneamente la marca CMS concurrente para GC Roots Tracing.
- Observación Observación de CMS Modifique el contenido del marcado simultáneo debido a cambios en el programa del usuario.
- El barrido concurrente de CMS limpia los objetos inalcanzables y recupera espacio. Al mismo tiempo, se genera nueva basura. Se llama basura flotante si está reservada para la próxima limpieza.
Ventajas: recopilación simultánea, pausa baja
Desventajas: una gran cantidad de fragmentación del espacio, la fase simultánea reducirá el rendimiento
4.4.7 G1 (basura primero)
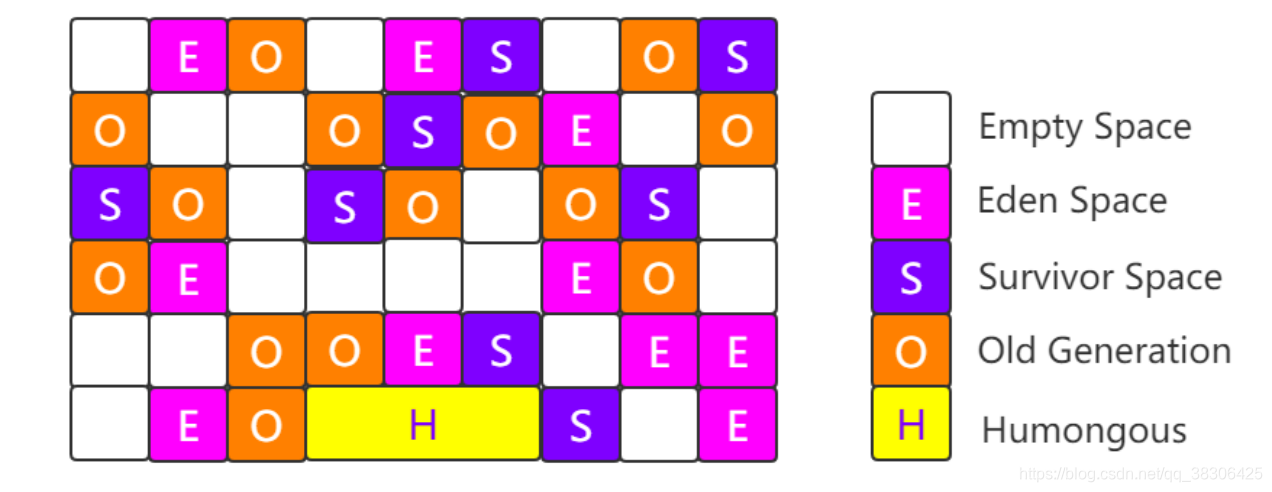
Cuando se utiliza el recopilador G1, el diseño de memoria del montón de Java es muy diferente al de otros recopiladores. Divide todo el montón de Java en varias
regiones independientes de igual tamaño (Región), aunque la nueva generación y la generación anterior todavía se conservan Concepto, pero la generación joven y la generación vieja ya no están
físicamente separadas, son todas una colección de una parte de regiones (no necesariamente continuas).
El tamaño de cada Región es el mismo, que puede ser un valor entre 1M y 32M, pero debe garantizarse que sea 2
elevado a n. Si el objeto es demasiado grande y una Región no puede caber [más del 50% del tamaño de la región ], será directamente
Póngalo en H. Establezca el tamaño de la región: -XX: G1HeapRegionSize = M. El
llamado Garbage-Frist es en realidad la región con más basura primero.
(1) Colección generacional (aún conserva el concepto de generaciones)
(2) Integración espacial (en general pertenece al algoritmo "marcar-organizar", que no provocará fragmentación espacial)
(3) Pausa predecible (más avanzada que CMS El lugar es permitir al usuario especificar claramente un segmento de tiempo de M milisegundos de duración, y el tiempo dedicado a la recolección de basura no debe exceder N milisegundos)

Proceso de trabajo:
- Marcado inicial Marque los siguientes objetos que se pueden asociar con GC Roots y modifique el valor de TAMS, debe suspender el hilo del usuario.
- Marcado concurrente Realice un análisis de accesibilidad desde GC Roots, descubra los objetos supervivientes y ejecútelo al mismo tiempo que los subprocesos de usuario.
- Marcado final (Marcado final) Modifique la fase de marcado concurrente debido a la ejecución concurrente del programa de usuario para cambiar los datos, el hilo del usuario debe suspenderse.
- Detección y reciclaje (recuento y evacuación de datos en vivo) Clasifique el valor y el costo del reciclaje de cada región y elabore un plan de reciclaje según el tiempo de pausa del GC que espera el usuario.
4.4.8 ZGC

El nuevo colector ZGC introducido por JDK11, ya sea física o lógicamente, ya no existe un concepto de generaciones antiguas y nuevas en ZGC. Se
dividirá en páginas. Al realizar operaciones GC, las páginas se comprimirán, por lo que no habrá problema de fragmentación. Solo se puede usar en Linux de 64 bits y actualmente se usa menos.
(1) El requisito de tiempo de pausa dentro de los 10 ms se puede lograr
(2) Se admite la memoria de nivel de TB
(3) Una vez que la memoria del montón aumenta, el tiempo de pausa todavía está dentro de los 10 ms
4.4.9 Clasificación del recolector de basura
- Serial collector- > Serial y Serial Old
solo pueden ser ejecutados por un hilo de recolección de basura, y el hilo del usuario está suspendido. - Colector paralelo [prioridad de rendimiento] -> Parallel Scanvenge, Parallel Old.
Varios subprocesos de recolección de basura funcionan en paralelo, pero el subproceso del usuario todavía está esperando.
Es adecuado para escenarios interactivos como la informática científica y el procesamiento en segundo plano. - Recopilador concurrente [prioridad de tiempo de pausa] -> CMS,
el subproceso de usuario G1 y el subproceso de recolección de basura se ejecutan al mismo tiempo (pero no necesariamente en paralelo, se pueden ejecutar alternativamente), el subproceso de recolección de basura no pausará el subproceso de usuario durante la ejecución Ejecutar, adecuado para escenarios que requieren un tiempo relativo, como Web.
4.4.10 Preguntas frecuentes
Rendimiento y tiempo de pausa
Tiempo de pausa -> Terminal de recolección de basura del recolector de basura Tiempo de respuesta de ejecución de la aplicación
Rendimiento -> Tiempo de ejecución del código de usuario / (Tiempo de ejecución del código de usuario + Tiempo de recolección de basura)
Cuanto más corto sea el tiempo de pausa, más adecuado será el programa que necesita interactuar con el usuario. Una buena velocidad de respuesta puede mejorar la experiencia del usuario; un alto rendimiento puede usar de manera eficiente el tiempo de la CPU para completar las tareas informáticas del programa lo antes posible. Es principalmente adecuado para la computación en segundo plano sin demasiada necesidad. Tareas multi-interactivas
Cómo elegir el recolector de basura adecuado
Priorice el ajuste del tamaño del montón y deje que el servidor elija por sí mismo.
Si la memoria es inferior a 100 M, utilice un colector en serie.
Si es un solo núcleo y no hay un requisito de tiempo de pausa, utilice serie o JVM.
Si se permite que el tiempo de pausa supere 1 segundo, seleccione paralelo o JVM Elija el suyo propio
Si el tiempo de respuesta es lo más importante y no puede exceder 1 segundo, use un recolector concurrente
Para la colección G1
JDK 7 comenzó a usarse, JDK 8 es muy maduro y el recolector de basura predeterminado de JDK 9 es adecuado para generaciones nuevas y antiguas.
¿Utiliza el colector G1?
(1) Más del 50% del montón está ocupado por objetos supervivientes
(2) La velocidad de asignación y promoción de objetos ha cambiado mucho
(3) El tiempo de recolección de basura es relativamente largo