Directorio de artículos
1. Chispa inicial
1.1 Qué es Spark
Apache Spark es un motor informático rápido y versátil diseñado para el procesamiento de datos a gran escala. Spark es un marco de trabajo de computación de propósito general similar a Hadoop MapReduce que es de código abierto del laboratorio AMP de UC Berkeley (laboratorio AMP de la Universidad de California, Berkeley). Spark tiene las ventajas de Hadoop MapReduce; la única diferencia con MapReduce es que los resultados intermedios de Job se pueden almacenar en la memoria sin la necesidad de leer y escribir DHFS. Por lo tanto, Spark se aplica mejor a los algoritmos de MapReduce que requieren iteración, como la minería de datos y el aprendizaje automático.
1.2 La diferencia entre Spark y MapReduce
- Son marcos de computación distribuida
- Spark se basa en la memoria, MR se basa en HDFS
- La capacidad de procesamiento de datos de Spark es generalmente más de diez veces mayor que la de MR
- Spark divide el orden de ejecución de las tareas según el gráfico acíclico dirigido por DAG
1.3 Modo de funcionamiento Spark
-
Local
Se utiliza principalmente para pruebas locales, como escribir pruebas de programas en eclipse e idea.
-
Ser único
Standalone es un marco de programación de recursos que viene con Spark, que admite la distribución completa.
-
Hilo
El marco de programación de recursos en el ecosistema de Hadoop, Spark, también se puede calcular en función de Yarn.
-
meses
Marco de programación de recursos
Para realizar la programación de recursos basada en Yarn, se debe implementar la interfaz ApplicationMaster. Spark implementa esta interfaz y puede basarse en Yarn.
2. SparkCore
2.1 RDD
2.1.1 Concepto
RDD (Resilient Distributed Dateset), un conjunto de datos distribuidos flexible.
2.1.2 Cinco características de RDD
- RDD se compone de una serie de particiones.
- La función se aplica a cada partición.
- Hay una serie de dependencias entre los RDD.
- El particionador funciona en RDD en formato K, V.
- RDD proporciona una serie de posiciones de cálculo óptimas.
2.1.3 Diagrama RDD

Mirando de arriba hacia abajo:
-
La capa inferior del método textFile encapsula la forma en que MR lee el archivo. Dividir antes de leer el archivo. El tamaño de división predeterminado es un tamaño de bloque.
-
RDD en realidad no almacena datos. Para mayor comodidad de comprensión, se entiende temporalmente como almacenamiento de datos.
-
¿Qué es RDD en formato K y V?
Si los datos almacenados en el RDD son todos objetos binarios, entonces este RDD se llama RDD en formato K, V.
-
¿Dónde se refleja la resiliencia / tolerancia a fallas de RDD?
El número de paticiones y el tamaño de los RDD no limitan la flexibilidad del sistema RDD.
La dependencia entre RDD se puede volver a calcular en función del RDD anterior.
-
¿Dónde se refleja el RDD distribuido?
RDD se compone de particiones, que se distribuyen en diferentes nodos.
-
RDD proporciona la mejor ubicación para el cálculo y refleja la localización de datos. El concepto de "computación de datos móviles que no se mueven" en big data está estructurado.
2.2 Principio de ejecución de la tarea Spark
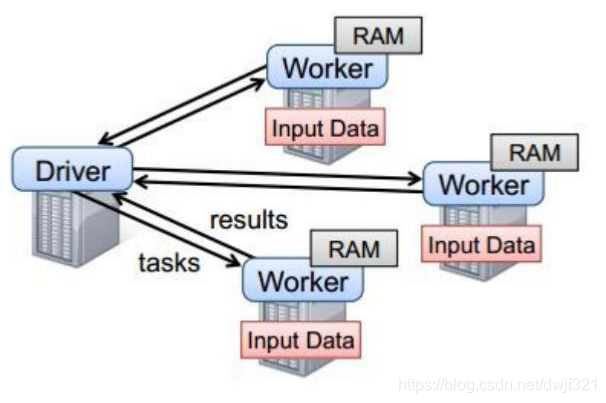
Los cuatro nodos de máquina en la figura anterior, controlador y trabajador, son procesos que se inician en los nodos y se ejecutan en la JVM.
- Comunicación frecuente entre el controlador y los nodos del clúster.
- El conductor es responsable de la distribución de tareas y los resultados del reciclaje, la programación de tareas. Si el resultado del cálculo de la tarea es muy grande, no es necesario reciclarlo, lo que provocará OOM.
- El trabajador es el nodo esclavo de la gestión de recursos en el marco de programación de recursos independiente. También es un proceso de JVM.
- Master es el nodo principal de la gestión de recursos en el marco de programación de recursos independiente. También es un proceso de JVM.
2.3 Flujo del código de chispa
-
Crear objeto SparkConf
Puede establecer appName
Puede configurar el modo de funcionamiento y los requisitos de recursos
-
Cree un objeto SparkContext.
-
Cree RDD basado en el contexto de Spark y procese RDD.
-
La aplicación debe tener un operador de clase Acción para desencadenar la ejecución del operador de clase Transformación.
-
Cierre el objeto de contexto Spark SparkContext.
2.4 Operador de conversión de transformaciones
2.4.1 Concepto
El operador de transformaciones es un tipo de operador (función), llamado operador de transformación. Tales como: map, flatMap, reduceByKey, etc. El operador de transformaciones retrasó la ejecución, también llamada ejecución de carga diferida.
2.4.2 Operador de clase de transformación
| Transformaciones 算 子 | efecto |
|---|---|
| mapa (func) | Devuelve un nuevo conjunto de datos distribuidos, donde cada elemento se convierte de un elemento en el RDD de origen a través de la función func |
| filtro (func) | Devuelve un nuevo conjunto de datos, que contiene elementos del resultado de filtrar los elementos en el RDD de origen a través de la función func (el resultado de la función func devuelve verdadero) |
| flatMap (func) | Similar al mapa, pero cada elemento se puede asignar a 0 an elementos de salida (la función func debe devolver una secuencia (Seq) en lugar de un solo elemento) |
| mapPartitions (func) | Similar al mapa, pero se basa en que cada partición (o bloque de datos) del RDD se ejecute de forma independiente, por lo que si el RDD contiene el tipo de elemento T, la función func debe ser una función de mapeo de Iterator => Iterator |
| mapPartitionsWithIndex (func) | Similar a mapPartitions, excepto que func tiene un índice de partición entero más, por lo que RDD contiene el tipo de elemento T, entonces la función func debe ser una función de mapeo de Iterator => Iterator |
| mapWith (func1, func2) | mapWith es otra variante de map, map solo necesita una función de entrada y mapWith tiene dos funciones de entrada. La primera función toma el índice de partición del RDD (el índice comienza desde 0) como entrada, y la salida es el nuevo tipo A; la segunda función f toma la tupla de dos (T, A) como entrada (donde T es el elemento en el RDD original, A es la salida de la primera función), el tipo de salida es U |
| reduceByKey (func, [numTasks]) | Si el RDD de origen contiene un par (K, V) de tipos de elementos, el operador también devuelve un RDD que contiene pares (K, V), excepto que el valor correspondiente a cada clave es el resultado de la agregación de la función func y la función func Es una función de mapeo de (V, V) => V. Además, y el tipo groupByKey. El número de tareas de reducción se puede especificar mediante el parámetro opcional numTasks |
| aggregateByKey (zeroValue, seqOp, combOp, [numTasks]) | Si el RDD de origen contiene pares (K, V), el RDD nuevo devuelto contiene pares (K, V), donde el valor correspondiente a cada clave se agrega mediante la función combOp y un valor "0" zeroValue. Después de ejecutar la agregación, el tipo de valor es diferente del tipo de valor de entrada, lo que evita gastos generales innecesarios. Similar a groupByKey. El número de tareas del reductor se puede especificar mediante el parámetro opcional numTasks |
| sortByKey ([ascendente], [numTasks]) | Si el RDD de origen contiene un par de elementos (K, V) y K se puede ordenar, el nuevo RDD que contiene pares (K, V) se devuelve y se ordena por K (el parámetro ascendente determina si es ascendente o descendente) |
| sortBy (func, [ascendente], [numTasks]) | Similar a sortByKey, excepto que sortByKey solo se puede ordenar por clave, y sortBy es más flexible y se puede ordenar por clave o valor. |
| randomSplit (Array [Double], Long) | Esta función divide un RDD en varios RDD de acuerdo con los pesos. El parámetro de peso es una matriz doble, y el segundo parámetro es la semilla de aleatorio, que básicamente se puede ignorar |
| glom () | Esta función convierte los elementos de tipo T en cada partición del RDD en Array [T], de modo que cada partición tenga solo un elemento de arreglo. |
| zip (otherDataSet) | Se utiliza para combinar dos RDD en RDD en forma de K y V. De forma predeterminada, el número de particiones y el número de elementos de los dos RDD son los mismos; de lo contrario, se lanzará una excepción. |
| partición por (particiones) | Esta función genera un nuevo ShuffleRDD de acuerdo con la función del particionador y reparte el RDD original. |
| unirse (otherDataset, [numTasks]) | Es equivalente a INNER JOIN de mysql. Solo regresa cuando existen los conjuntos de datos en los lados izquierdo y derecho de la combinación. El número de particiones después de unirse es el mismo que el que tiene más particiones RDD principales |
| leftOuterJoin (otherDataset) | Equivalente a LEFT JOIN de mysql, leftOuterJoin devuelve todos los datos en el lado izquierdo del conjunto de datos y los datos donde el lado izquierdo y el lado derecho del conjunto de datos tienen intersecciones, y los datos inexistentes se rellenan con Ninguno |
| rightOuterJoin (otherDataset) | Equivalente a RIGHT JOIN de MySQL, rightOuterJoin devuelve todos los datos en el lado derecho del conjunto de datos y los datos donde el lado derecho y el lado izquierdo del conjunto de datos se cruzan, y los datos no existentes se rellenan con Ninguno |
| fullOuterJoin (otherDataset) | Devuelva todos los datos de los conjuntos de datos izquierdo y derecho, y complete los datos que no existen en los lados izquierdo y derecho con Ninguno |
| Unión | Combine los dos conjuntos de datos. Los tipos de los dos conjuntos de datos deben ser coherentes. El número de particiones del nuevo RDD devuelto es la suma del número de particiones RDD fusionadas. |
| intersección | Tome la intersección de los dos conjuntos de datos y devuelva el nuevo RDD que tiene más particiones consistentes con el RDD principal |
| sustraer | Tome la diferencia de los dos conjuntos de datos, y el número de particiones del RDD de resultado es el mismo que el número de particiones del RDD antes de restar |
| distinto | Deduplicación, equivalente a (map + reduceByKey + map) |
| cogrupo | Cuando se llaman datos de tipos (K, V) y (K, W), se devuelve un conjunto de datos (K, (Iterable, Iterable)) y la partición del RDD secundario es más consistente con el RDD principal. |
2.5 Operador de acción
2.5.1 Concepto
El operador de acción también es un tipo de operador (función), llamado operador de acción, como foreach. recopilar, contar, etc. El operador de transformaciones se retrasa la ejecución, el operador de acción activa la ejecución. Hay varios operadores de clase de acción que se ejecutan en una aplicación de aplicación y se están ejecutando varios trabajos.
2.5.2 Operador de acción
| Operador de acción | efecto |
|---|---|
| reducir (func) | 将RDD中元素按func函数进行聚合,func函数是一个(T,T) ==> T 的映射函数,其中T为源RDD的元素类型,并且func需要满足交换律和结合律以便支持并行计算 |
| collect() | 将数据集集中,所有元素以数组形式返回驱动器(driver)程序。通常用于在RDD进行了filter或其他过滤后,将足够小的数据子集返回到驱动器内存中,否则会OOM。 |
| count() | 返回数据集中元素个数 |
| first() | 返回数据中首个元素(类似于take(1)) |
| take(n) | 返回数据集中前n个元素 |
| takeSample(withReplacement,num,[seed]) | 返回数据集的随机采样子集,最多包含num个元素,withReplacement表示是否使用回置采样,最后一个参数为可选参数seed,随机数生成器的种子。 |
| takeOrderd(n,[ordering]) | 按元素排序(可以通过ordering自定义排序规则)后,返回前n个元素 |
| foreach(func) | 循环遍历数据集中的每个元素,运行相应的逻辑 |
| foreachParition(func) | foreachParition和foreach类似,只不过是对每个分区使用函数,性能比foreach要高,推荐使用。 |
2.6 控制算子
2.6.1 概念
控制算子有三种:cache、persist、checkpoint。以上算子都是可以将RDD持久化,持久化单位是partition。cache和persist都是懒执行的,必须有一个action 类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
2.6.2 控制算子介绍
-
cache
默认将RDD的数据持久化到内存中。cache是懒执行。
cache() = persist(StorageLevel.MEMORY_ONLY()); -
persist
可以指定持久化的级别。最常用的是
StorageLevel.MEMORY_ONLY()和StorageLevel.MEMORY_AND_DISK()。"_2"表示有副本。持久化级别如下:
def useDisk : scala.Boolean = { /* compiled code */ } def useMemory : scala.Boolean = { /* compiled code */ } def useOffHeap : scala.Boolean = { /* compiled code */ } def deserialized : scala.Boolean = { /* compiled code */ } def replication : scala.Int = { /* compiled code */ }持久化级别 作用 NONE不做持久化 DISK_ONLY只持久化到磁盘 DISK_ONLY_2只持久化到磁盘,并且有2个副本 MEMORY_ONLYSolo persiste en la memoria MEMORY_ONLY_2Solo persiste en la memoria y tiene 2 copias MEMORY_ONLY_SERSolo persiste en la memoria y serializa MEMORY_ONLY_SER_2Solo persiste en la memoria, almacena 2 copias y serializa MEMORY_AND_DISKPersistir en la memoria y el disco, y almacenar en el disco cuando la memoria sea insuficiente MEMORY_AND_DISK_2Conservar en la memoria y el disco, almacenar en el disco cuando la memoria no es suficiente y tener 2 copias MEMORY_AND_DISK_SERConservar en la memoria y el disco, almacenar en el disco cuando la memoria sea insuficiente y serializar MEMORY_AND_DISK_SER_2Conservar en la memoria y en el disco, almacenar en el disco cuando la memoria no sea suficiente, tener 2 copias y serializar OFF_HEAPPersistir en la memoria del montón Precauciones para caché y persistencia:
- Tanto la caché como la persistencia se ejecutan de forma perezosa, y debe haber un operador de clase de acción para desencadenar la ejecución.
- El valor de retorno de los operadores de caché y persistencia se puede asignar a una variable. Usar esta variable directamente en otros trabajos es usar datos persistentes. La unidad de persistencia es la partición.
- Los operadores de caché y persistencia no pueden seguir inmediatamente al operador de acción.
- Los datos persistentes de la caché y los operadores persistentes se borrarán después de que se ejecute la aplicación.
Error: el RDD persistente implementado devuelto por rdd.cache (). Count () es un valor numérico.
-
control
Checkpoint conserva los RDD en el disco y también puede cortar la dependencia entre los RDD. Los datos del directorio de puntos de control no se borrarán después de que se ejecute la aplicación.
El principio de ejecución del punto de control:
- Cuando se ejecuta el trabajo RDD, retrocederá desde el RDD final hacia el frente.
- Cuando se llama al método de punto de control para un determinado RDD, se realizará una marca en el RDD actual.
- El marco de Spark iniciará automáticamente un nuevo trabajo y volverá a calcular los datos de este RDD. Conservar los datos en HDFS.
Optimización: antes de realizar el punto de control en el RDD, es mejor ejecutar primero la caché en este RDD, de modo que el trabajo recién iniciado solo necesite copiar los datos en la memoria a HDFS, eliminando la necesidad de recalcular el paso.
utilizar:
SparkSession spark = SparkSession.builder() .appName("JavaLogQuery").master("local").getOrCreate(); JavaSparkContext sc = new JavaSparkContext(spark.sparkContext()); JavaRDD<String> dataSet = sc.parallelize(exampleApacheLogs); dataSet = dataSet.cache(); sc.setCheckpointDir("/checkpoint/dir"); dataSet.checkpoint(); -
no persistir
Elimina los datos almacenados en la memoria y el disco.