Hace unos días, me comuniqué con Ao Bing. Dijo que nuestros escritores se están quemando constantemente, por lo que necesitamos repostar constantemente. Desde su punto de vista, ya no puedo estar de acuerdo, así que comencé a adquirir conocimientos básicos de informática, que incluyen mi estructura de datos relativamente débil.
La definición de estructura de datos de Baidu Baike es: una colección de elementos de datos que tienen una o más relaciones específicas entre sí. La definición es muy abstracta y es necesario leerla en voz alta varias veces para sentir un poco. ¿Cómo hacer que este sentimiento sea más fuerte e íntimo? Permítanme enumerar 8 estructuras de datos comunes, matrices, listas vinculadas, pilas, colas, árboles, montones, gráficos y tablas hash.
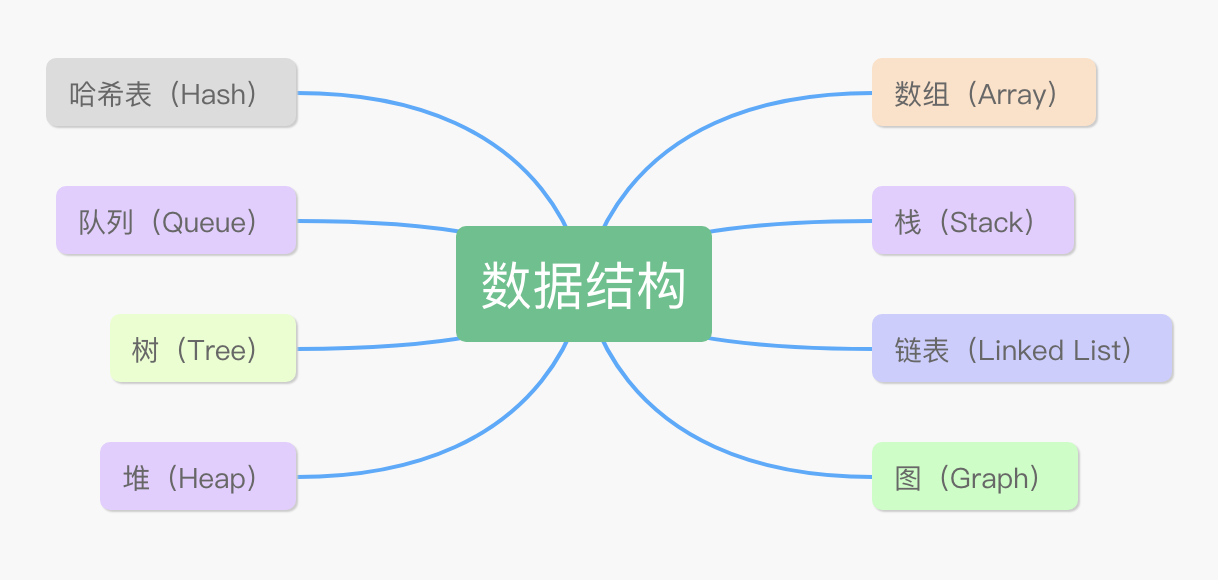
¿Cuál es la diferencia entre estas 8 estructuras de datos?
①, matriz
ventaja:
- La velocidad de consulta de elementos según el índice es muy rápida;
- También es conveniente recorrer la matriz por índice.
Desventajas:
- El tamaño de la matriz se determina después de la creación y no se puede expandir;
- La matriz solo puede almacenar un tipo de datos;
- La operación de agregar y eliminar elementos lleva mucho tiempo porque es necesario mover otros elementos.
②, lista vinculada
El libro "Algoritmo (4ª edición)" define la lista enlazada de la siguiente manera:
Una lista enlazada es una estructura de datos recursiva, está vacía (nula) o es una referencia a un nodo. El nodo también tiene un elemento y una referencia a otra lista enlazada.
La clase LinkedList de Java puede expresar vívidamente la estructura de una lista vinculada en forma de código:
public class LinkedList<E> {
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
Esta es una lista doblemente vinculada. El elemento actual tiene prev y next, pero el anterior del primero es nulo y el siguiente del último es nulo. Si se trata de una lista enlazada individualmente, solo hay siguiente y no anterior.
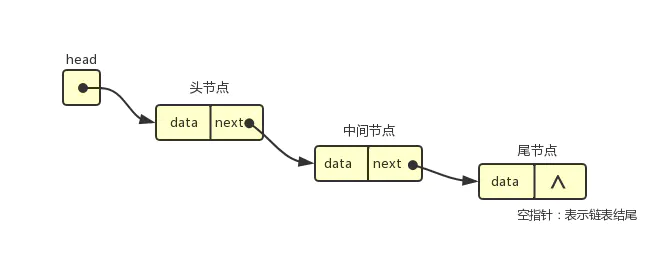
La desventaja de una lista enlazada individualmente es que solo se puede recorrer secuencialmente de principio a fin, mientras que una lista enlazada doble se puede avanzar o retroceder, y puede encontrar la siguiente y la anterior; cada nodo necesita asignar un espacio de almacenamiento más.
Los datos de la lista enlazada se almacenan en una estructura de "cadena", por lo que puede lograr el efecto de memoria no continua, y la matriz debe ser una memoria continua.
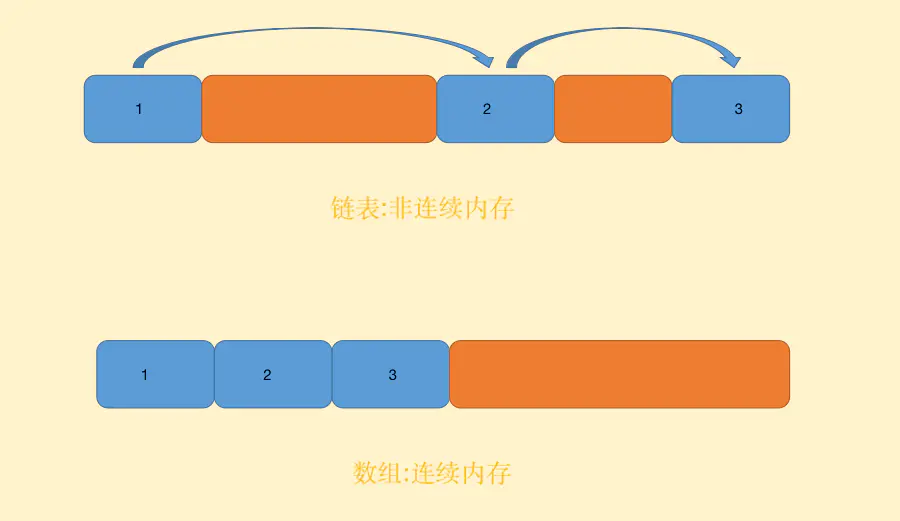
Dado que no tiene que almacenarse de manera secuencial, la lista enlazada puede alcanzar una complejidad de tiempo O (1) al insertar y eliminar (solo es necesario apuntar a la referencia nuevamente, no es necesario mover otros elementos como una matriz). Además, la lista enlazada supera la desventaja de que el tamaño de los datos de la matriz debe conocerse de antemano, de modo que se pueda realizar una gestión de memoria dinámica flexible.
ventaja:
- No es necesario inicializar la capacidad;
- Se puede agregar cualquier elemento;
- Solo necesita actualizar la referencia al insertar y eliminar.
Desventajas:
- Contiene una gran cantidad de referencias y ocupa un gran espacio de memoria;
- Encontrar un elemento requiere recorrer toda la lista vinculada, lo que requiere mucho tiempo.
③, apilar
La pila es como un cubo, el fondo está sellado, la parte superior está abierta, el agua puede entrar y salir. Los amigos que han usado baldes deben entender esta verdad: el agua que entra primero está en el fondo del balde, y el agua que entra después está en la parte superior del balde; el agua que entra más tarde se vierte primero y el agua que entra primero se vierte más tarde.
De la misma manera, la pila almacena los datos de acuerdo con los principios de "último en entrar, primero en salir" y "primero en entrar último en salir". Los datos que se insertan primero se colocan en la parte inferior de la pila y los datos que se insertan más tarde se encuentran en la parte superior de la pila. Al leer datos, comience desde la parte superior de la pila. Leer secuencialmente.

④, cola
La cola es como una sección de tubería de agua, ambos extremos están abiertos, el agua entra por un extremo y luego sale por el otro. El agua que entra primero sale primero y el agua que entra luego sale.
Algo diferente de la pipa de agua es que la cola definirá los dos extremos, un extremo se llama cabeza del equipo y el otro extremo se llama cola. Solo se permiten operaciones de eliminación (sacar de la cola) en la cabeza del equipo, y solo se permiten operaciones de inserción (ingresar a la cola) al final del equipo.

Tenga en cuenta que la pila es el primero en entrar, el último en salir, y la cola es el primero en entrar, primero en salir, aunque ambas son tablas lineales, los principios son diferentes y la estructura es diferente.
⑤, árbol
El árbol es una estructura no lineal típica, es una colección jerárquica compuesta por n (n> 0) nodos finitos.

Se llama "árbol" porque esta estructura de datos parece un árbol al revés, excepto que las raíces están en la parte superior y las hojas en la parte inferior. La estructura de datos de árbol tiene las siguientes características:
- Cada nodo tiene solo un número limitado de nodos secundarios o ningún nodo secundario;
- Un nodo sin un nodo padre se llama nodo raíz;
- Cada nodo no raíz tiene uno y solo un nodo padre;
- A excepción del nodo raíz, cada nodo hijo se puede dividir en múltiples subárboles disjuntos.
La siguiente figura muestra algunos términos del árbol:

El nodo raíz es el nivel 0, sus nodos secundarios son el nivel 1, los nodos secundarios de los nodos secundarios son el nivel 2, y así sucesivamente.
- Profundidad: para cualquier nodo n, la profundidad de n es la única longitud de la ruta desde la raíz an, y la profundidad de la raíz es 0.
- Altura: para cualquier nodo n, la altura de n es la longitud del camino más largo desde n hasta una hoja, y la altura de todas las hojas es 0.
Hay muchos tipos de árboles, los más comunes son:
- Árbol desordenado: no existe una relación de orden entre los nodos secundarios de ningún nodo del árbol. Entonces, ¿cómo entiendes el árbol desordenado y cómo se ve?
Si hay tres nodos, uno es un nodo principal y dos son nodos secundarios del mismo nivel, entonces hay tres situaciones:

Si hay tres nodos, uno es un nodo principal y dos son nodos secundarios de diferentes niveles, entonces hay seis situaciones:

Un árbol desordenado compuesto por tres nodos se puede combinar en nueve situaciones.
- Árbol binario: cada nodo contiene como máximo dos subárboles. Los árboles binarios se pueden dividir en varios tipos de acuerdo con diferentes manifestaciones.
Árbol binario completo: para un árbol binario, suponga que su profundidad es d (d> 1). A excepción de la capa d-ésima, el número de nodos en las otras capas ha alcanzado el máximo, y todos los nodos de la capa d-ésima están dispuestos de manera continua y ajustada de izquierda a derecha. Este árbol binario se denomina árbol binario completo.

Tome la figura anterior como ejemplo, d es 3. Excepto por la tercera capa, la primera y la segunda capa han alcanzado el valor máximo (2 nodos secundarios), y todos los nodos de la tercera capa están estrechamente conectados de izquierda a derecha (H , I, J, K, L), de acuerdo con los requisitos de un árbol binario completo.
Árbol binario completo: un árbol binario con el número máximo de nodos en cada capa. Hay dos manifestaciones: la primera, como se muestra en la figura siguiente (cada capa está llena), satisface el número máximo de nodos en cada capa de 2.

El segundo, como en la siguiente figura (aunque cada capa no está llena), pero el número de nodos en cada capa aún alcanza el máximo de 2.

Árbol de búsqueda binaria: el nombre en inglés es Árbol de búsqueda binaria, o BST, que debe cumplir las siguientes condiciones:
- El subárbol izquierdo de cualquier nodo no está vacío y los valores de todos los nodos del subárbol izquierdo son menores que el valor de su nodo raíz;
- El subárbol derecho de cualquier nodo no está vacío y los valores de todos los nodos del subárbol derecho son mayores que el valor de su nodo raíz;
- Los subárboles izquierdo y derecho de cualquier nodo también son árboles de búsqueda binarios.

Basado en las características del árbol de búsqueda binaria, su ventaja en comparación con otras estructuras de datos es que la complejidad temporal de la búsqueda y la inserción es relativamente baja, que es O (logn). Si queremos encontrar 5 elementos de la figura anterior, partimos del nodo raíz 7. 5 debe estar a la izquierda de 7, y 4 debe encontrarse, y 5 debe estar a la derecha de 4, y 6 debe encontrarse a la izquierda de 6. Side, lo encontré.
Idealmente, para encontrar nodos a través de BST, la cantidad de nodos que deben verificarse se puede reducir a la mitad.
Árbol binario equilibrado: un árbol binario cuya diferencia de altura entre dos subárboles de cualquier nodo no es mayor que 1. El árbol binario altamente equilibrado propuesto por los matemáticos Adelse-Velskil y Landis de la ex Unión Soviética en 1962 también se llama árbol AVL según el nombre en inglés de los científicos.
Un árbol binario balanceado es esencialmente un árbol de búsqueda binario. Sin embargo, para limitar la diferencia de altura entre los subárboles izquierdo y derecho, y evitar inclinar árboles que están sesgados hacia la evolución de la estructura lineal, los subárboles izquierdo y derecho de cada nodo en el árbol de búsqueda binaria son Debido a la limitación, la diferencia de altura entre los subárboles izquierdo y derecho se denomina factor de equilibrio, y el valor absoluto del factor de equilibrio de cada nodo del árbol no es mayor que 1.
La dificultad de equilibrar un árbol binario radica en cómo mantener el equilibrio de izquierda a derecha para zurdos o diestros cuando se eliminan o agregan nodos.
El árbol binario equilibrado más común en Java es el árbol rojo-negro. Los nodos son rojos o negros. El equilibrio del árbol binario se mantiene mediante restricciones de color:
1) Cada nodo solo puede ser rojo o negro
2) El nodo raíz es negro
3) Cada nodo hoja (nodo NIL, nodo vacío) es negro.
4) Si un nodo es rojo, entonces sus dos nodos secundarios son negros. Es decir, dos nodos rojos adyacentes no pueden aparecer en un camino.
5) Todos los caminos desde cualquier nodo a cada hoja contienen el mismo número de nodos negros.

- Árbol B: un árbol de búsqueda binario autoequilibrado optimizado para operaciones de lectura y escritura, que puede mantener los datos en orden y tiene más de dos subárboles. El árbol B se utiliza en la tecnología de índices de bases de datos.

⑥, montón
El montón se puede considerar como un objeto de matriz de un árbol, con las siguientes características:
- El valor de un nodo en el montón no es siempre mayor o menor que el valor de su nodo padre;
- Heap es siempre un árbol binario completo.
El montón con el nodo raíz más grande se llama el montón más grande o el montón raíz grande, y el montón con el nodo raíz más pequeño se llama el montón más pequeño o el montón raíz pequeño.

⑦ 、 Imagen
Un gráfico es una estructura no lineal compleja, compuesta por un conjunto finito no vacío de vértices y un conjunto de aristas entre vértices, generalmente expresado como: G (V, E), donde G representa un gráfico y V es un gráfico en G El conjunto de vértices, E es el conjunto de aristas en el gráfico G.

La figura anterior tiene 4 vértices V0, V1, V2, V3 y hay 5 aristas entre los 4 vértices.
En una estructura lineal, los elementos de datos satisfacen una relación lineal única, y cada elemento de datos (excepto el primero y el último) tiene un "precursor" y un "sucesor" únicos;
En la estructura de árbol, existe una relación jerárquica obvia entre los elementos de datos, y cada elemento de datos solo está relacionado con un elemento en la capa superior (nodo principal) y varios elementos (nodos secundarios) en la siguiente capa;
En la estructura del gráfico, la relación entre los nodos es arbitraria y dos elementos de datos cualesquiera en el gráfico pueden estar relacionados.
⑧, tabla hash
Hash Table, también llamada Hash Table, es una estructura de datos a la que se puede acceder directamente a través de un valor clave. Su característica más importante es que puede encontrar, insertar y eliminar rápidamente.
La característica más importante de una matriz es que es fácil de encontrar, pero difícil de insertar y eliminar; por el contrario, la lista vinculada es difícil de encontrar, pero fácil de insertar y eliminar. La tabla hash combina perfectamente las ventajas de los dos, el HashMap de Java también agrega las ventajas del árbol sobre esta base.

La función hash juega un papel muy crítico en la tabla hash. Puede transformar una entrada de cualquier longitud en una salida de longitud fija, y la salida es el valor hash. La función hash hace que el proceso de acceso a una secuencia de datos sea más rápido y eficaz, ya que a través de la función hash se pueden localizar rápidamente elementos de datos.
Si la palabra clave k, el valor almacenado en la hash(k)ubicación de almacenamiento. Por tanto, el valor correspondiente a k se puede obtener directamente sin recorrido.
Para dos bloques de datos diferentes, la posibilidad del mismo valor hash es extremadamente pequeña, es decir, para un bloque de datos dado, es extremadamente difícil encontrar un bloque de datos con el mismo valor hash. Además, para un bloque de datos, incluso si solo se cambia un bit, el cambio en su valor hash será muy grande: ¡este es el valor de Hash!
Aunque la posibilidad es extremadamente pequeña, todavía sucede. Si el hash entra en conflicto, HashMap de Java agregará una lista vinculada en la misma posición en la matriz. Si la longitud de la lista vinculada es mayor que 8, se convertirá en un árbol rojo-negro para su procesamiento, esto Es el llamado método de cremallera (matriz + lista vinculada).
Para ser honesto, de acuerdo con este progreso, me siento como un ritmo calvo, pero si puede hacerse más fuerte, vale la pena, sí, vale la pena. También hay algunos amigos que me pidieron que les recomendara algunos libros sobre algoritmos y estructuras de datos. He recopilado algunos populares en GitHub y puedes descargarlos haciendo clic en el enlace. Espero que mi corazón pueda ayudarte.

Enlace: https://pan.baidu.com/s/1rB-CCjjpKPidOio7Ov_0YA Contraseña: g5pl
Soy el segundo rey del silencio, un programador silencioso pero interesante, y la atención puede mejorar la eficiencia del aprendizaje. Amigos a los que les gusta este artículo, no se olviden de Quad, me gusta, marcan, reenvían, dejan un mensaje, ¡son los más hermosos y los más guapos!