Tabla de contenido
concat () , concat_ws () , group_concat ()
concat () : concatena varias cadenas en una sola y devuelve el resultado como la cadena generada por los parámetros de conexión. Si algún parámetro es nulo, el valor de retorno es nulo.
SELECT CONCAT(1,',',2,',',3,',',4) result;
Resultado de la operación: 1, 2, 3, 4
SELECT CONCAT(1,',',NULL,',',3,',',4) result;
Resultado de la operación: NULL
concat_ws () : (concat con separador) Igual que concat (), concatena varias cadenas en una sola, pero puedes especificar el separador a la vez. Si el separador es nulo, el resultado es todo nulo. Si el parámetro después del separador es nulo, se omitirá el valor nulo.
SELECT CONCAT_WS(',',1,2,3,4) result;
Resultado de la operación: 1, 2, 3, 4
SELECT CONCAT_WS(',',1,NULL,3,4) result;
Resultado de la operación: 1,3,4
SELECT CONCAT_WS(',',1,2,3,4) result;
Resultado de la operación: NULL
group_concat () : en la instrucción group by query, concatena varias filas de datos del mismo grupo en una sola cadena.
Sintaxis : group_concat ([distinto] el campo que se conectará [ordenar por campo de clasificación asc / desc] [separador'separador '])
Descripción : Los valores duplicados se pueden excluir utilizando distinto; si desea ordenar los valores en el resultado, puede usar La cláusula order by; el separador es un valor de cadena, el valor predeterminado es una coma.

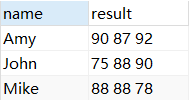
Use group_concat () para enumerar las calificaciones de cada persona con un espacio como separador
SELECT `name`,GROUP_CONCAT(mark SEPARATOR ' ') result
FROM score1 GROUP BY `name`;
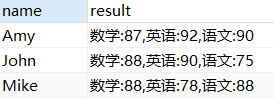
Utilice group_concat () para enumerar las calificaciones de todos en forma de pares clave-valor
SELECT `name`,GROUP_CONCAT(`subject`,':',mark ORDER BY `subject`) result
FROM score1 GROUP BY `name`;
Nota para group_concat () :
- Después de usar group_concat, si se usa limit en select, no funcionará
- Existe un límite de longitud al conectar campos con group_concat. Utilice la variable de sistema group_concat_max_len para establecer la longitud máxima permitida. SET [SESSION | GLOBAL] group_concat_max_len = val;
- El separador predeterminado del sistema es la coma
COALESCE () , IFNULL ()
COALESCE () se utiliza principalmente para el procesamiento de valores nulos, y su formato de parámetro: COALESCE (expresión, valor1, valor2 ……, valorn)
La primera expresión de parámetro de la función COALESCE () es la expresión que se va a probar, y los siguientes parámetros son El número es incierto.
La función COALESCE () devolverá la primera expresión no vacía en todos los parámetros, incluida la expresión.
Si expresión no es un valor nulo, devuelve expresión; de lo contrario, determina si valor1 es un valor nulo,
si valor1 no es un valor nulo, devuelve valor1; de lo contrario, determina si valor2 es un valor nulo,
si valor2 no es un valor nulo, devuelve valor2;
si todas las expresiones Si la fórmula es nula, se devuelve NULL.
SELECT COALESCE(1,2,3) result1,
COALESCE(NULL,2,3) result2,
COALESCE(NULL,NULL,3) result3;
Resultado de la operación: 1, 2, 3
La función COALESCE () se puede utilizar para completar casi todo el procesamiento de valores nulos, pero en muchos sistemas de bases de datos se proporciona una versión simplificada. Estas versiones simplificadas solo aceptan dos variables, como IFNULL ()
SELECT IFNULL(NULL,666) result;
Resultado corriente: 666
SUM () calcula varias columnas
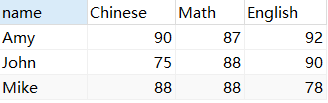
SELECT *,SUM( Chinese + Math + English ) sum
FROM score2 GROUP BY `name`
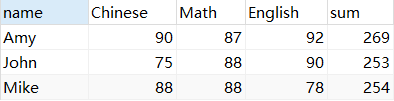
Columna a fila y fila a columna
Columna a fila, columna a fila
SELECT `name`,
MAX(IF(`subject`='语文',mark,0)) Chinese,
MAX(IF(`subject`='数学',`mark`,0)) Math,
MAX(IF(`subject`='英语',`mark`,0)) English
FROM score1
GROUP BY `name`;
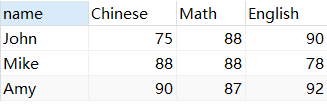
Fila a columna, fila a columna
SELECT `name`,'语文' `subject`,Chinese mark FROM score2
UNION
SELECT `name`,'数学' `subject`,Math mark FROM score2
UNION
SELECT `name`,'英语' `subject`,English mark FROM score2
ORDER BY `name`;
Conversión DISTINCT y GROUP BY
Hay las siguientes tablas, id es el id del registro, user_id es el id del usuario y cuenta el número de registros y usuarios.
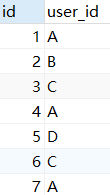
El enfoque de DISTINCT
SELECT COUNT(id) sum_id,COUNT(DISTINCT user_id) sum_user FROM t1;
La práctica de GROUP BY
SELECT sum(sum) sum_id,COUNT(user_id) sum_user FROM (
SELECT user_id,COUNT(1) sum FROM t1 GROUP BY user_id ) temp;

El nombre de la subconsulta
Se debe establecer el nombre de la subconsulta; si no se establece, se informará un error.
Subconsulta asociada y subconsulta existente
SELECT product_type, product_name, sale_price
FROM product t1 WHERE sale_price > (
SELECT avg(sale_price) FROM product t2
WHERE t1.product_type = t2.product_type);
La lógica de ejecución es la siguiente:
(1) Ejecute el ciclo externo primero, luego tome el primer valor de la columna _type del producto, ingrese la subconsulta, juzgue las condiciones de la cláusula where y, si coincide, calcule el valor promedio y devuelva el resultado.
(2) Repita la operación anterior hasta que se recuperen todos los registros en la columna de tipo de producto de la tabla Producto en la consulta principal.
Busque los datos en la tabla de artículos, pero el uid debe existir en la tabla de usuarios. La declaración SQL es la siguiente:
SELECT * FROM article WHERE EXISTS (
SELECT * FROM user WHERE article.uid = user.uid);
Coloque los datos de la consulta principal en la subconsulta para la verificación condicional y determine si el resultado de los datos de la consulta principal se puede retener de acuerdo con el resultado de la verificación (VERDADERO o FALSO, por lo que seleccionar puede ser arbitrario).
como coincide con caracteres especiales
escape puede especificar cuál es el carácter de escape usado en like, y el carácter después del carácter de escape se considerará como el carácter original
select * from table where name like '1\_%' escape '\'
select * from table where name like '%\%%' escape '\'