El algoritmo K-means es un algoritmo de agrupamiento.
Clasificación: Conocer el tipo de datos por adelantado, usar datos conocidos para entrenar a un clasificador y luego clasificar los datos no clasificados pertenece al aprendizaje supervisado.
Agrupación: el tipo de datos no se conoce de antemano, y los datos se agrupan de acuerdo con la similitud de las características, que pertenece al aprendizaje no supervisado.
La idea básica del algoritmo K-means:
- Seleccione aleatoriamente K puntos iniciales como centroide (categoría)
- Recorre cada pieza de datos y calcula su distancia de los centroides K
- Seleccione el centroide más cercano a él como la categoría a la que pertenecen los datos
- El centroide de cada grupo se actualiza al promedio de todos los puntos en el grupo
- Repita los pasos 2, 3 y 4 hasta que la función de costo converja al mínimo
El pseudocódigo del proceso anterior se expresa de la siguiente manera:
创建k个点作为起始质心(经常是随机选择)
当任意一个点的簇分配结果发生改变时:
对数据集中的每个数据点:
对每个质心:
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将均值作为质心
La función de costo de K-means (también conocida como función de distorsión) es:
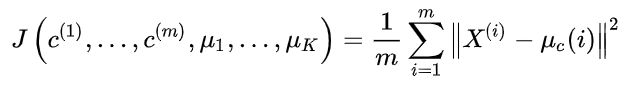
SSE (suma de errores al cuadrado)
对误差取了平方,因此更加重视那些远离中心的点。
Que μ_c(i)representa el x^(i)punto central del grupo más cercano. Nuestro objetivo de optimización es encontrar el que minimice la función de costo
迭代的过程一定会是每一次迭代都在减小代价函数,不然便是出现了错误。
Las principales ventajas de K-Means son:
- Fácil de lograr
- El principio es simple y la velocidad de convergencia es rápida.
- El procesamiento de grandes conjuntos de datos es más eficiente.
La complejidad del espacio es O (N), la complejidad del tiempo es O (IKN) ——N为样本点个数,K为中心点个数,I为迭代次数 - Solo se debe ajustar el número de clúster K.
Las principales desventajas de K-Means son:
-
Sensible a los valores iniciales, para diferentes valores iniciales, puede conducir a resultados diferentes.
-
Solo se puede usar cuando se define el valor promedio del clúster, que no es adecuado para procesar los datos del atributo de símbolo.
-
Difícil de converger en conjuntos de datos que no son convexos
-
Para datos no balanceados, el efecto de agrupamiento no es bueno.
-
Sensible al ruido y puntos anormales.
Materiales de referencia: tutorial de aprendizaje automático Wu Enda, "Combate de aprendizaje automático"
