Nebula Graph es una base de datos de gráficos distribuidos con alto rendimiento, alta disponibilidad y gran consistencia. Dado que Nebula Graph adopta una arquitectura de separación de almacenamiento y computación, la capa de almacenamiento en realidad expone una interfaz kv simple, usa RocksDB como máquina de estado y usa el protocolo de consistencia Raft para garantizar la consistencia de múltiples copias de datos. Aunque el protocolo Raft es más fácil de entender que Paxos, todavía hay muchas áreas que necesitan atención y optimización en la implementación de ingeniería.
Además, la forma de probar el sistema distribuido basado en Raft también es un problema que afecta a la industria.En la actualidad, Nebula utiliza principalmente Jepsen como una herramienta de verificación de consistencia. Mi pequeño amigo ya ha dado una introducción detallada en " La práctica del marco de prueba de Jepsen en el gráfico de la nebulosa de la base de datos gráfica ". Los estudiantes que no saben mucho sobre Jepsen pueden pasar a este artículo primero.
En este artículo, nos centraremos en cómo usar Jepsen para verificar la consistencia del kv distribuido de Nebula Graph.
Definición muy consistente
En primer lugar, lo que debemos entender se llama consistencia fuerte, que en realidad es linealización, también conocida como consistencia lineal. Para citar la definición en el libro "Diseño de aplicaciones intensivas en datos":
En un sistema linealizable, tan pronto como un cliente complete con éxito una escritura, todos los clientes que lean de la base de datos deben poder ver el valor recién escrito.
Es decir, aunque un sistema distribuido muy consistente puede tener múltiples copias adentro, está expuesto como si solo hubiera una copia, y cualquier solicitud de lectura del cliente obtiene los últimos datos escritos.
¿Cómo verifica Jepsen si el sistema cumple con una fuerte consistencia?
Tomando como ejemplo un cronograma de prueba de Jepsen, el modelo utilizado es de registro único , es decir, todo el sistema tiene un solo registro (el valor inicial está vacío) y el cliente solo puede leer o escribir en este registro (todas las operaciones son atómicas Sexo, no hay estado intermedio). Al mismo tiempo, cuatro clientes envían solicitudes al sistema. Los bordes superior e inferior de cada cuadro en la figura representan el momento en que se envía la solicitud y el momento en que se recibe la respuesta.

Desde la perspectiva del cliente, para cualquier solicitud, el servidor que procesa la solicitud puede ocurrir en cualquier momento desde el momento en que el cliente envía la solicitud para recibir el resultado correspondiente. Se puede ver que con el tiempo, las tres operaciones 1/3/4 del cliente escribir 1 / escribir 4 / leer 1 en realidad se superponen en el tiempo, pero podemos determinar a través de las respuestas recibidas por diferentes clientes El verdadero estado del sistema.
Como el valor inicial está vacío, la solicitud de lectura del cliente 4 obtiene 1, lo que indica que la operación de lectura del cliente 4 debe ser posterior a la escritura 1 del cliente 1, y la escritura 4 ocurre antes de la escritura 1 (de lo contrario, leerá 4), Puede confirmar que el orden en que ocurrieron las tres operaciones es escribir 4-> escribir 1-> leer 1. Aunque desde una perspectiva global, la solicitud de lectura 1 se emite primero, en realidad se procesa en último lugar. Las siguientes operaciones no tienen una superposición en el tiempo y ocurren en secuencia. Finalmente, el cliente 2 finalmente lee 4 de la última escritura. Todo el proceso no violó la definición fuerte y consistente y pasó la verificación.
Si el valor obtenido por la lectura del cliente 3 es 4, entonces todo el sistema no es muy consistente, porque de acuerdo con el análisis anterior, el valor de la última escritura exitosa es 1, mientras que el cliente 3 lee 4, Es un valor caducado, que viola la consistencia lineal. De hecho, Jepsen también usa un algoritmo similar para verificar si el sistema distribuido cumple con una fuerte consistencia.
Encuentre el problema correspondiente a través de la verificación de coherencia de Jepsen
Primero, presentemos brevemente el proceso de procesamiento de una solicitud en Nebula Raft (tomando tres copias como ejemplo) para comprender mejor los problemas posteriores. La solicitud de lectura es relativamente simple, ya que el cliente solo enviará la solicitud al líder, el nodo líder solo necesita obtener el resultado correspondiente directamente de la máquina de estado y devolverlo al cliente bajo la premisa de asegurarse de que es el líder.
El proceso de solicitud de escritura es más complicado, como se muestra en el diagrama de Raft Group:
Leader (círculo verde en la figura) recibe la solicitud enviada por el cliente y la escribe en su propio wal (registro de escritura anticipada).
El Líder envía la entrada de registro correspondiente en wal al seguidor, y entra en la espera.
Después de que el seguidor recibe la entrada de registro, la escribe en su propio wal (no espera a que se aplique a la máquina de estado) y devuelve el éxito.
Después de que el Líder recibe al menos un seguidor y devuelve el éxito, se aplica a la máquina de estado y envía una respuesta al cliente.
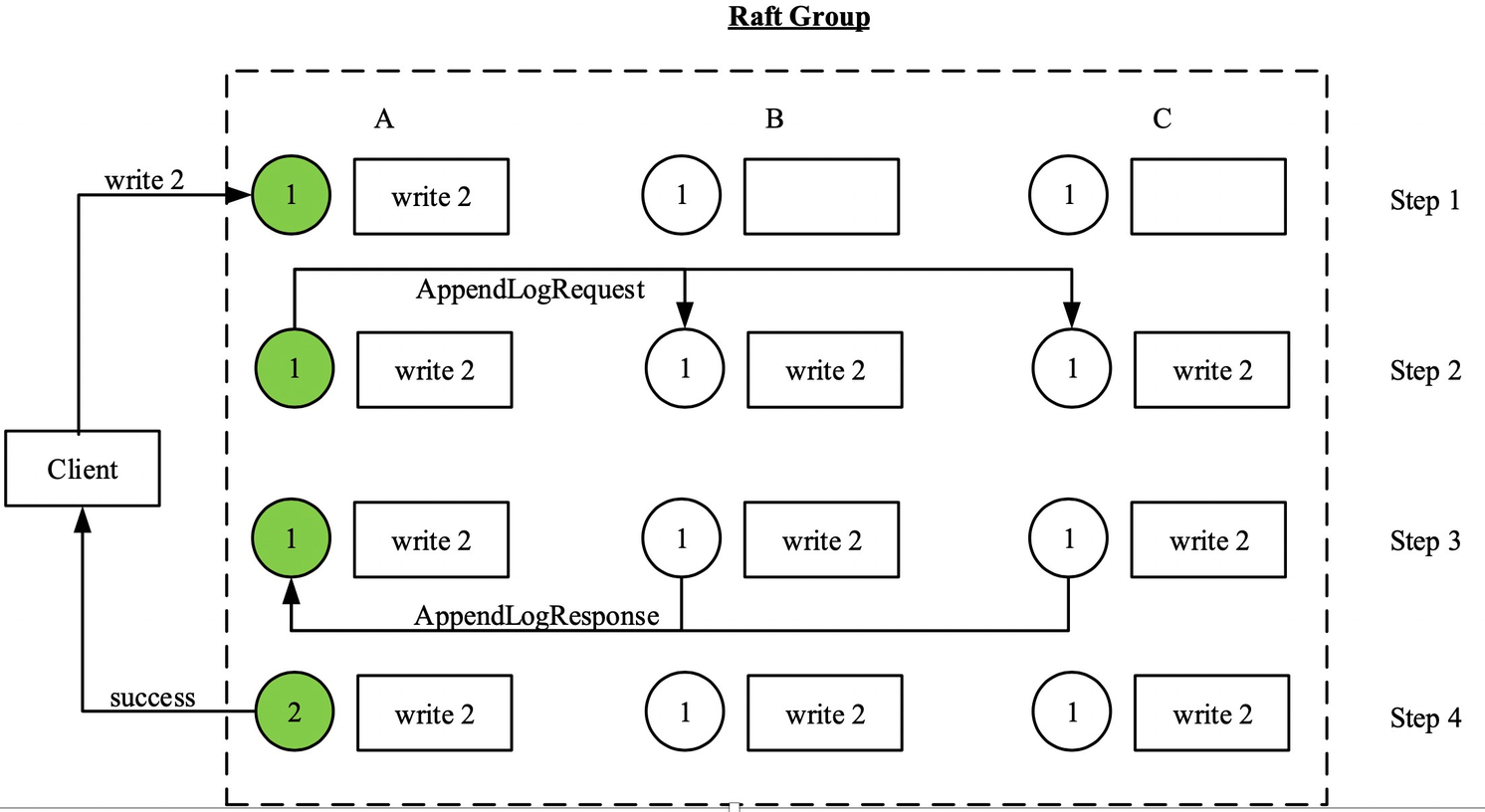
A continuación, usaré ejemplos para ilustrar los problemas de consistencia encontrados en la implementación anterior de Raft a través de las pruebas de Jepsen:
Como se muestra en la figura anterior, ABC forma un grupo de balsa de tres copias, el círculo es la máquina de estados (por simplicidad, se supone que es un registro único) y la entrada de registro correspondiente se guarda en el cuadro.
En el estado inicial, las máquinas de estado en las tres copias son todas 1, el Líder es A y el término es 1
El cliente envía una solicitud de escritura 2, y el líder la procesa de acuerdo con el proceso anterior, y se cancela después de notificar al cliente que la escritura fue exitosa. (Después de completar el paso 4)
Después de eso, C fue seleccionado como el líder del término 2, pero debido a que C puede no haber aplicado la entrada de registro de la escritura 2 anterior a la máquina de estado en este momento (la máquina de estado sigue siendo 1). Si C recibe una solicitud de lectura del cliente en este momento, C devolverá directamente 1. Esto viola la definición de coherencia fuerte y ha escrito correctamente 2 antes, pero leyó el resultado expirado.
El problema es que después de que C se selecciona como el líder del término 2, es necesario enviar el latido para garantizar que la mayoría de los nodos acepten la entrada del registro del término anterior. Antes de que este latido tenga éxito, no puede proporcionar una lectura externa (de lo contrario, puede leer datos caducados) . Los estudiantes interesados pueden consultar la Figura 8 y la sección 5.4.2 en balsa parer.
A partir de la pregunta anterior, encontramos otra pregunta relacionada a través de Jepsen: ¿cómo se asegura el líder de que sigue siendo el líder? Este problema a menudo ocurre en particiones de red. Cuando el líder no puede comunicarse con otros nodos debido a problemas de red y está aislado, en este momento, si la solicitud de lectura aún se puede procesar, es posible leer el valor caducado. Para esto introdujimos el concepto de arrendamiento líder.
Después de seleccionar un nodo como líder, el nodo debe enviar latidos a otros nodos regularmente. Si el latido confirma que la mayoría de los nodos lo han recibido, obtendrá un contrato de arrendamiento por un período de tiempo y se asegurará de que no aparezca un nuevo líder durante este tiempo. , Lo que garantiza que los datos del nodo deben estar actualizados, de modo que las solicitudes de lectura puedan procesarse normalmente durante este tiempo.
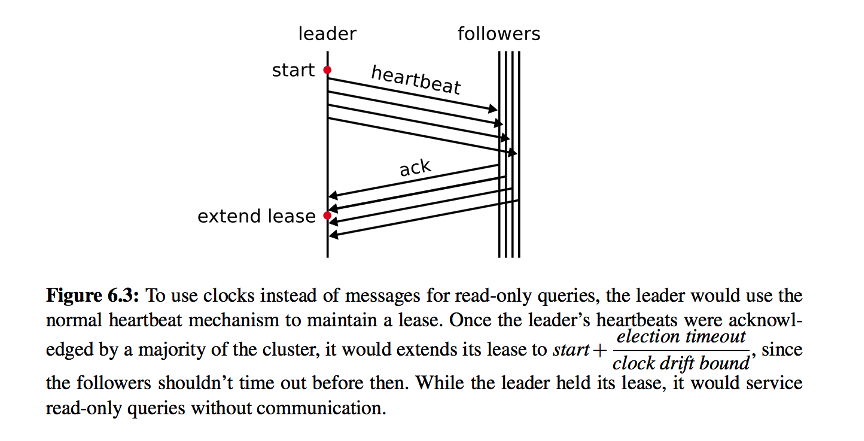
A diferencia del método de procesamiento de TiKV, no tomamos el intervalo de latido multiplicado por el coeficiente como el tiempo de arrendamiento, considerando principalmente el problema de la deriva del reloj diferente de las diferentes máquinas. En cambio, ahorra el costo de tiempo del último latido exitoso o appendLog, y resta el costo del intervalo de latidos para que sea la duración del tiempo de arrendamiento. Hospital de Inseminación Artificial de Zhengzhou: http://jbk.39.net/yiyuanfengcai/tsyl_zztjyy/3102/
Cuando se produce la partición de red, el líder todavía está aislado, pero aún puede manejar las solicitudes de lectura durante este tiempo de arrendamiento (para las solicitudes de escritura, el cliente será notificado de la falla de escritura debido al aislamiento), y fallará después del tiempo de arrendamiento. Cuando el seguidor no recibe un mensaje del líder durante al menos un intervalo de latidos, iniciará una elección y seleccionará un nuevo líder para procesar las solicitudes posteriores de los clientes.
Conclusión
Para un sistema distribuido, muchos problemas requieren mucho tiempo de prueba de esfuerzo y simulación de fallas para descubrirlo. A través de Jepsen, el sistema distribuido puede verificarse bajo diferentes fallas de inyección. Más adelante también consideraremos el uso de otras herramientas de ingeniería del caos para verificar Nebula Graph y mejorar continuamente el rendimiento bajo la premisa de garantizar una alta confiabilidad de los datos.
Hospital de infertilidad de Zhengzhou: http://mobile.03913882333.com/