little_by_little_2 Crea una clase de conjunto de datos para un conjunto de datos. (Basado en pytorch)
Prólogo
Recientemente, caí en la ansiedad y finalmente me perdí en la confusión. No quiero mencionarlo.
Tarea
Cree un pytorch.dataset para un conjunto de datos de 100 yuanes y 1 yuanes para que lea el cargador de datos
Código fuente
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_label = {"1": 0, "100": 1}
#1
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
#2
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
#3
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
Interpretación
# 1 parte
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
Los datos de inicialización no se repiten aquí.
# 2 parte
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
-
¿Por qué se define en _get_ item? Debido a que la clase del cargador de datos se usa en pytorch para llamar a la clase del conjunto de datos de esta manera:
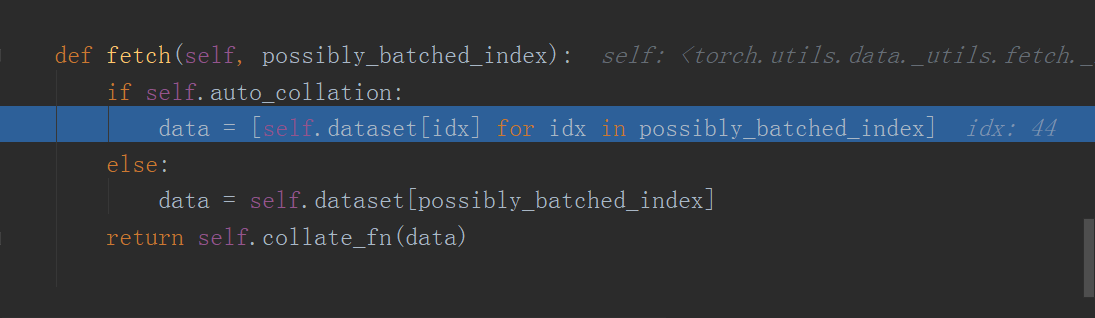
-
path_img, label = self.data_info[index]Reciba datos de datos y etiquetas -
img = Image.open(path_img).convert('RGB') # 0~255Convertir img a modo de tres canales -
if self.transform is not None: img = self.transform(img) # 在这里做transform,转为tensor等等
Determine si se pasa la transformación. Si se pasa la transformación, transform.compounds se transformará.
return img, labelDevolver datos y etiquetas
# 3 sección
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
- La función de esta función es obtener los datos de todas las imágenes en la ruta y etiquetarlas
for root, dirs, _ in os.walk(data_dir):La función os.walk está involucrada aquí,
def walk(top: T,
topdown: bool = True,
onerror: Optional[(Exception) -> None] = None,
followlinks: bool = False) -> Iterator[Tuple[T, List[T], List[T]]]
top -- 是你所要遍历的目录的地址,
return--返回的是一个三元组(root,dirs,files)。
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
topdown --可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
onerror -- 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
followlinks -- 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。
-
for sub_dir in dirs: img_names = os.listdir(os.path.join(root, sub_dir)) img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))Primero explique la estructura del directorio:

Hay fotos de 1 y 100 yuanes en 1 y 100.
img_names = os.listdir(os.path.join(root, sub_dir)) Extracto ... / 1
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) Extraiga todos los nombres de archivo que terminan en .jpg en ... / 1 y devuelva una lista, es decir, img_names se convierte en una lista llena de los nombres de todas las imágenes en el directorio ... / 1
-
for i in range(len(img_names)): img_name = img_names[i] path_img = os.path.join(root, sub_dir, img_name) label = rmb_label[sub_dir] data_info.append((path_img, int(label)))La función principal de esta función es extraer la ruta de todas las imágenes en img_names y la etiqueta. Vale la pena mencionar que
label = rmb_label[sub_dir]debido a que el nombre de la carpeta en sí es la etiqueta, el método para extraer la etiqueta es extraer el nombre de la carpeta.Finalmente, devuelva una lista data_info donde cada elemento tiene la forma de una tupla (img_path, label).