Introducción :
hoy aprendemos la regresión logística. Todos sabemos que el modelo de regresión lineal es
, lo transformamos, obtenemos
, esto es "regresión lineal logit" (regresión lineal logit), que es lo que llamamos regresión logística. Deformarse de nuevo
, generalmente, poner
Forma, llamada modelo lineal generalizado.
1. Principios matemáticos
Porque X es continuo, entonces
El resultado de también es continuo: para poder hacer el problema de clasificación binaria, recurrimos a la función de paso unitario. Como se muestra a continuación:
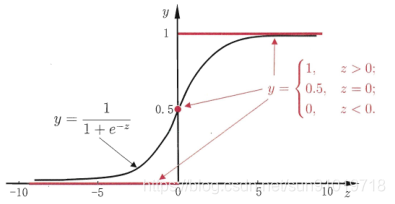
presentamos la función sigmoidea, la forma de regresión logística es
. Dejamos y ≥ el umbral, el resultado es un ejemplo positivo, de lo contrario, es un ejemplo negativo (el umbral es generalmente 1/2).
Nota: La regresión logística se basa en el pensamiento probabilístico, pero no es una probabilidad real, por lo que es diferente del algoritmo bayesiano.
Función de pérdida: , Cuando buscamos el modelo de regresión logística óptimo, encontramos un conjunto de parámetros θ, de modo que la función de pérdida J (θ) alcanza el valor mínimo.
Segundo, la implementación del código
1. Implementación manual del código El
proceso de implementación:
①, defina el método sigmoide, use el método sigmoide para generar el modelo de regresión logística;
②, defina la función de pérdida y use el método de descenso de gradiente para obtener los parámetros;
③, sustituya los parámetros en el modelo de regresión logística para obtener la probabilidad;
Probability Convierta la probabilidad en clasificación.
在这里插入代码片
2. Implementación de Sklearn En el
artículo anterior, aprendimos la regularización, que puede mejorar la capacidad de generalización del modelo. El algoritmo de regresión logística de sklearn se agrega directamente a la regularización, el parámetro es penalización y el valor predeterminado es L2. Además, se agrega un hiperparámetro C. Es decir, la forma de la función de pérdida es
Referencias: "Aprendizaje automático Zhou Zhihua" Capítulo 3 Modelo lineal Sección 3.2, Sección 3.3
Artículo de referencia:
https://mp.weixin.qq.com/s/xfteESh2bs1PTuO2q39tbQ
https://mp.weixin.qq.com/s / nZoDjhqYcS4w2uGDtD1HFQ
https://mp.weixin.qq.com/s/ex7PXW9ihr9fLOjlo3ks4w
https://mp.weixin.qq.com/s/97CA-3KlOofJGaw9ukVq1A
https://mp.weixin.qq.com/
