Este capítulo comenzará con el problema de clasificación en el aprendizaje automático.Aunque el nombre es regresión, es para clasificación. La forma más básica de pensar en problemas de clasificación: por ejemplo, para reconocer números escritos a mano, el modelo predecirá diez categorías de imágenes de entrada y dará 10 probabilidades. Seleccione el que tenga la mayor probabilidad como resultado de la predicción, que es clasificación múltiple.
Aquí utilizamos un conjunto de datos clásico: minist, que se puede descargar desde pytorch, el código es el siguiente:
import torchvision
train_set = torchvision.datasets.MNIST(root=’../dataset/mnist',train=FTrue,download=True)
test_set = torchvision.datasets.MNIST(root='../dataset/mnist',train=False,download=True)
El conjunto de datos CIFAR-10 también se proporciona en pytorch, que es un conjunto de imágenes pequeñas de 32 × 32, que incluyen 50.000 conjuntos de entrenamiento y 10.000 conjuntos de prueba, con 10 categorías.
Dado que la predicción y = wx + b, y∈R, pero la probabilidad de salida debe ser [0, 1], debemos asignar el resultado de la predicción a [0, 1] . Aquí usaremos la función logística , la imagen de la función se muestra en la Figura 1, ubicada en [0, 1].
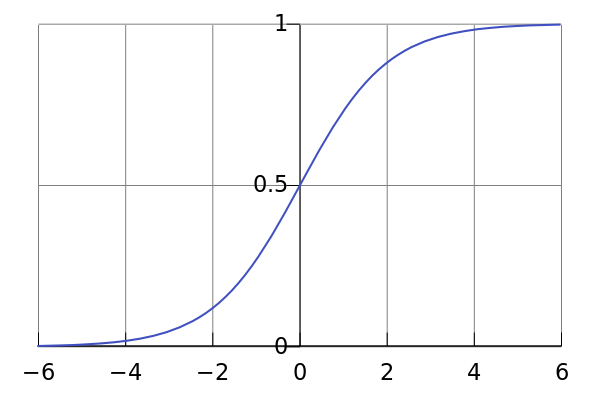
Utilice esta función para asignar y_hat al intervalo requerido. La logística también se llama sigmoide y la logística se llama sigmoide en la biblioteca de pytorch. En artículos de aprendizaje profundo, si ve σ(), está activando con la función sigmoidea. La única diferencia entre esta y la regresión lineal es la adición de un sesgo σ . La diferencia en el código se muestra en la Figura 2:

La fórmula necesaria para la función de pérdida en el problema de clasificación binaria es:
Esta función se llama BCE Loss y se usa en el código como:
criterion = torch.nn.BCELoss(size_average = False)
Solo hay dos cambios en todo el código y dicha estructura de marco puede escribir una gran cantidad de modelos.

La siguiente sección tratará la entrada de características multidimensionales.