Comprensión y práctica de hashing consistente
El algoritmo hash consistente se define en Wikipedia de la siguiente manera:
El hashing consistente es un algoritmo de hashing especial. Después de usar el algoritmo de hash coherente, cambiar el número de ranuras en la tabla hash (tamaño) solo requiere una
K/nnueva asignaciónKde palabras clave , donde el número de palabras clave es el númeronde ranuras. Sin embargo, en una tabla hash tradicional, agregar o eliminar un espacio requiere la reasignación de casi todas las claves.
Bueno, por primera vez, no entiendo. Comencemos con el algoritmo hash tradicional.
Algoritmo hash tradicional
A medida que el negocio se desarrolla y la cantidad de datos aumenta, necesitamos agregar nodos de servidor. Para la solicitud enviada por el cliente, primero pasamos una capa de Proxy, que procesa las solicitudes de lectura y escritura del cliente. Después de recibir la solicitud de lectura y escritura, seleccionamos la clave para encontrar el nodo correspondiente. Como se muestra a continuación:

A través del algoritmo hash, cada clave se puede direccionar al servidor correspondiente, suponiendo que la solicitud enviada por el cliente es clave-01, la fórmula de cálculo es hash (clave-01)% 3, y la dirección es la número 1 después del cálculo El nodo del servidor A se muestra en la figura a continuación.
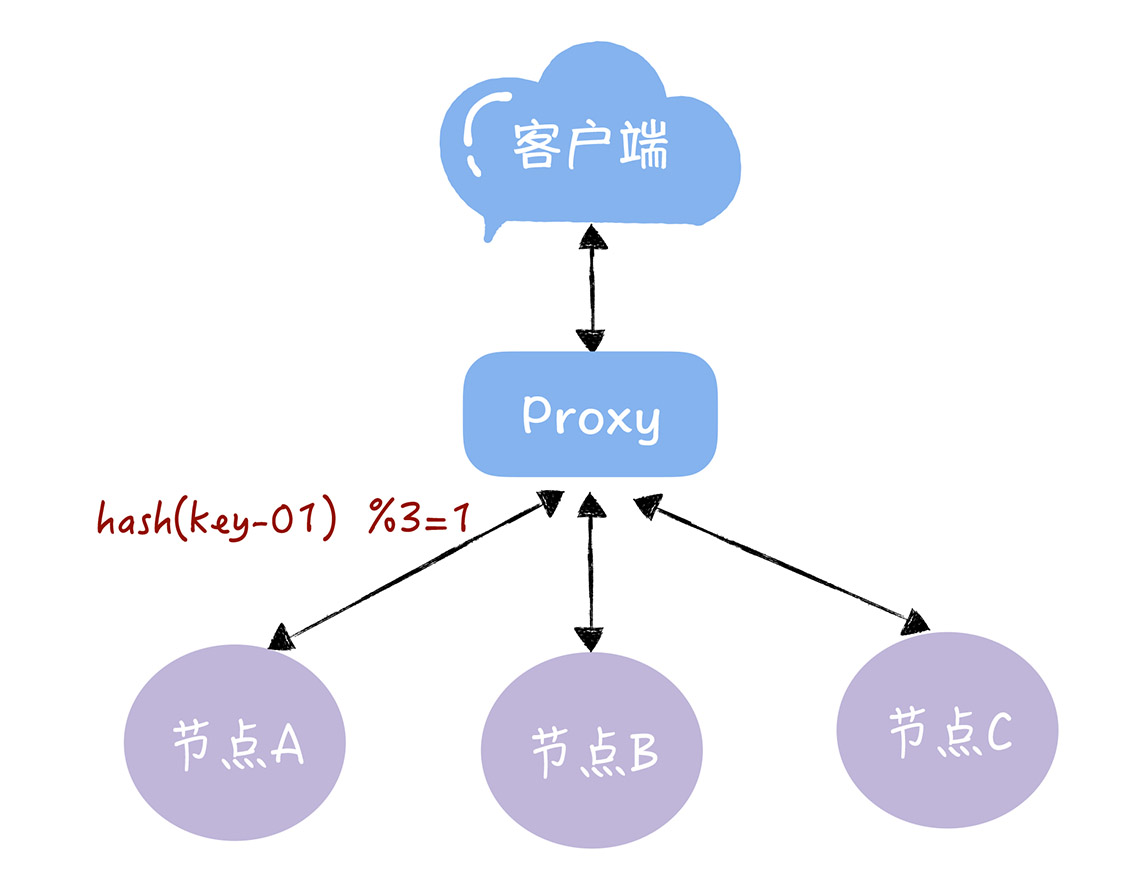
Sin embargo, si el número de servidores cambia y el algoritmo hash se ejecuta en función del nuevo número de servidores, el direccionamiento de enrutamiento fallará y el Proxy no puede encontrar el nodo del servidor que se abordó anteriormente. Imagine que si 3 nodos no pueden satisfacer las necesidades comerciales, agregamos un nodo, el número de nodos cambia de 3 a 4, luego el hash anterior (clave-01)% 3 = 1, se convierte en hash ( clave-01)% 4 = X, porque la operación del módulo ha cambiado, por lo que la probabilidad de X no es 1. En este momento, si vuelve a consultar, no encontrará los datos, porque los datos correspondientes a la clave-01 se almacenan en el nodo A, no el nodo B. Por la misma razón, si necesitamos cerrar sesión en 1 nodo del servidor (es decir, reducir el tamaño), también habrá un problema similar por el que los datos no pueden consultarse.
Para resolver este problema, necesitamos migrar los datos y reasignar los datos y los nodos en función de la nueva fórmula de cálculo hash (clave-01)% 4 . Cabe señalar que el costo de la migración de datos es muy alto . Esto se explica por un escenario específico:
Supongamos que hay 10 millones de datos que se almacenaron originalmente en 3 nodos. Si agregamos 1 nodo, ¿cuántos datos necesitamos para migrar?
La siguiente verificación de código: (código completo aquí )
// 传统的哈希映射
func hash(key int, nodes int) int {
return key % nodes
}
// migrate:需要迁移的数据量
// keys:数据量(1000万)
// nodes:旧集群的节点个数
// newNodes:新集群的节点个数
// migrateRatio:数据迁移率
migrate := 0
for i := 0; i < keys; i++ {
if hash(i, nodes) != hash(i, newNodes) {
migrate++
}
}
migrateRatio := float64(migrate) / float64(keys)
Al ejecutar:
$ go run ./hash.go -keys 10000000 -nodes 3 -new-nodes 4
74.999980%
Como puede ver, necesitamos migrar el 75% de los datos. Debido a que el mapeo de hash ordinario depende en gran medida del número de nodos en el clúster, cuando el número de nodos aumenta o disminuye, la relación de mapeo cambiará turbulentamente, lo que no es tolerable en el entorno de producción.
Para resolver este problema, se introdujo un algoritmo hash consistente .
Algoritmo de hash consistente
Principio: Hash Ring
El algoritmo hash consistente también usa la operación de módulo, pero a diferencia del algoritmo hash que realiza la operación de módulo en el número de nodos, el algoritmo hash consistente realiza la operación de módulo en 2 ^ 32. Como puede imaginar, el algoritmo hash consistente organiza todo el espacio de valores hash en un anillo virtual, es decir, un anillo hash.
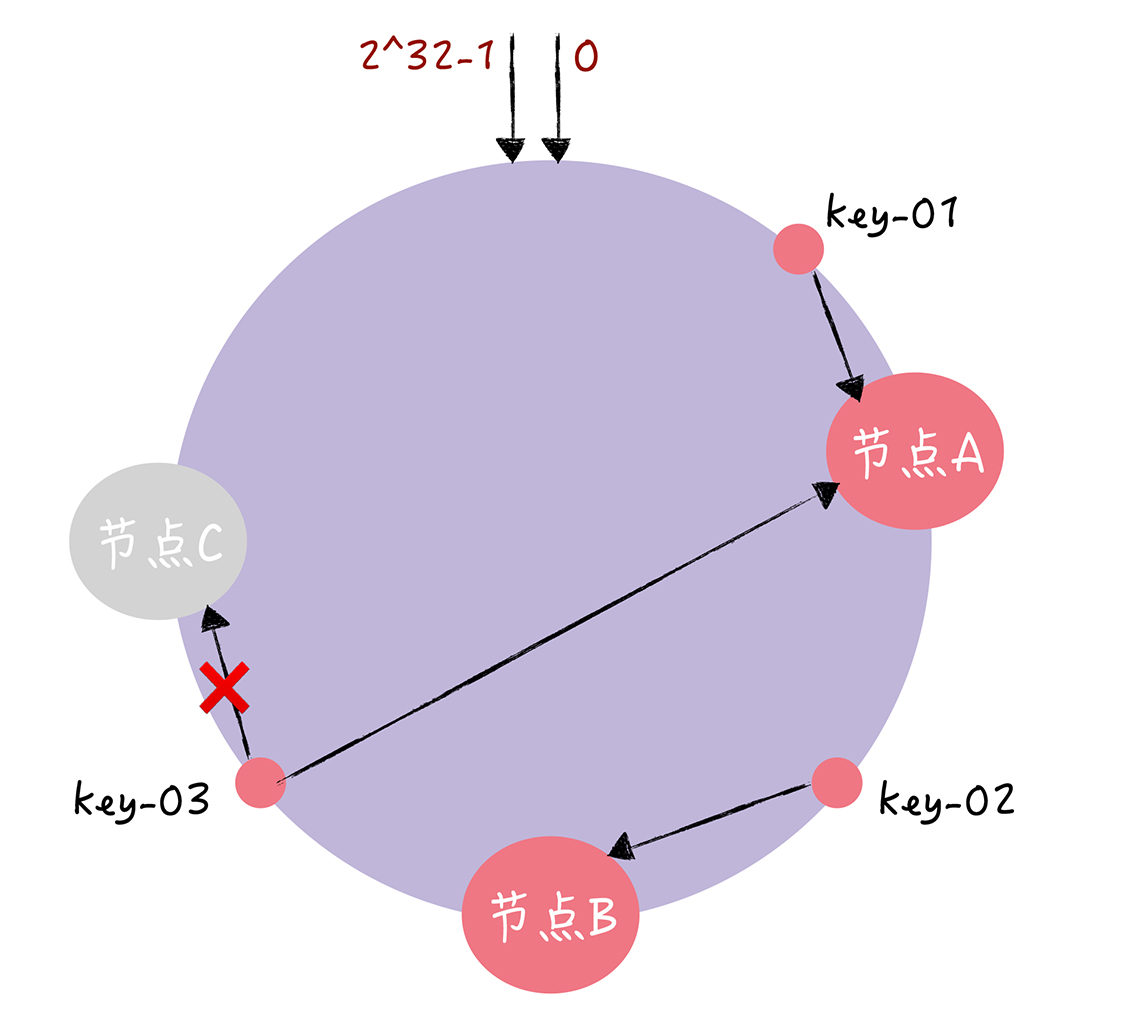
En el hash coherente, al ejecutar un algoritmo hash (para la conveniencia de la demostración, suponga que la función del algoritmo hash es "c-hash ()"), asigne el nodo al anillo hash (generalmente seleccione el nombre de host del nodo, la dirección IP, etc. Ejecute c-hash () como parámetro, como se muestra en la siguiente figura:

Cuando necesite leer y escribir el valor de la clave especificada, puede abordarlo a través de los siguientes 2 pasos:
- Primero, realice c-hash () con la tecla como parámetro para calcular el valor de hash y determinar la posición de esta tecla en el anillo;
- Luego, desde esta posición, "camine" en el sentido de las agujas del reloj a lo largo del anillo hash , y el primer nodo encontrado es el nodo correspondiente a la clave.
Este proceso se muestra a continuación:

Como puede ver, en la figura anterior, la clave 01 se asigna al nodo A, la clave 02 se asigna al nodo B y la clave 03 se asigna al nodo C. Si el nodo C está inactivo, de acuerdo con las reglas de direccionamiento, solo la clave-03 necesita ser reubicada en el nodo A, y la clave-01 y la clave-02 no necesitan ser cambiadas. En otras palabras, el algoritmo hash consistente solo necesita reubicar una pequeña parte de los datos cerca del nodo al agregar / reducir un nodo, en lugar de reubicar todos los nodos. Esto resuelve efectivamente el problema de la "migración de datos a gran escala al agregar / reducir nodos".
Problema: sesgo de datos
Cuando hay pocos nodos de servidor, es fácil causar una distribución desigual de las posiciones de los nodos, lo que puede causar un sesgo de datos. Como se muestra en la figura a continuación, debido a la distribución desigual de los nodos, una gran cantidad de solicitudes de acceso se concentra en el nodo A, lo que resulta en una carga desigual en los nodos de caché. Este es el problema de sesgo de datos .

Para resolver el problema de sesgo de datos, se introduce el concepto de nodos virtuales .
Mejora: Introducir nodos virtuales
El llamado nodo virtual es calcular múltiples valores hash para cada nodo del servidor , colocar un nodo virtual en cada posición del resultado del cálculo y asignar el nodo virtual al nodo real. Suponiendo que 1 nodo real corresponde a 2 nodos virtuales, los nodos virtuales correspondientes al nodo A son nodo-A-01 y nodo-A-02 (generalmente implementados mediante la suma de números), y los nodos restantes son similares. Como resultado, se forman 6 nodos virtuales, como se muestra en la siguiente figura:
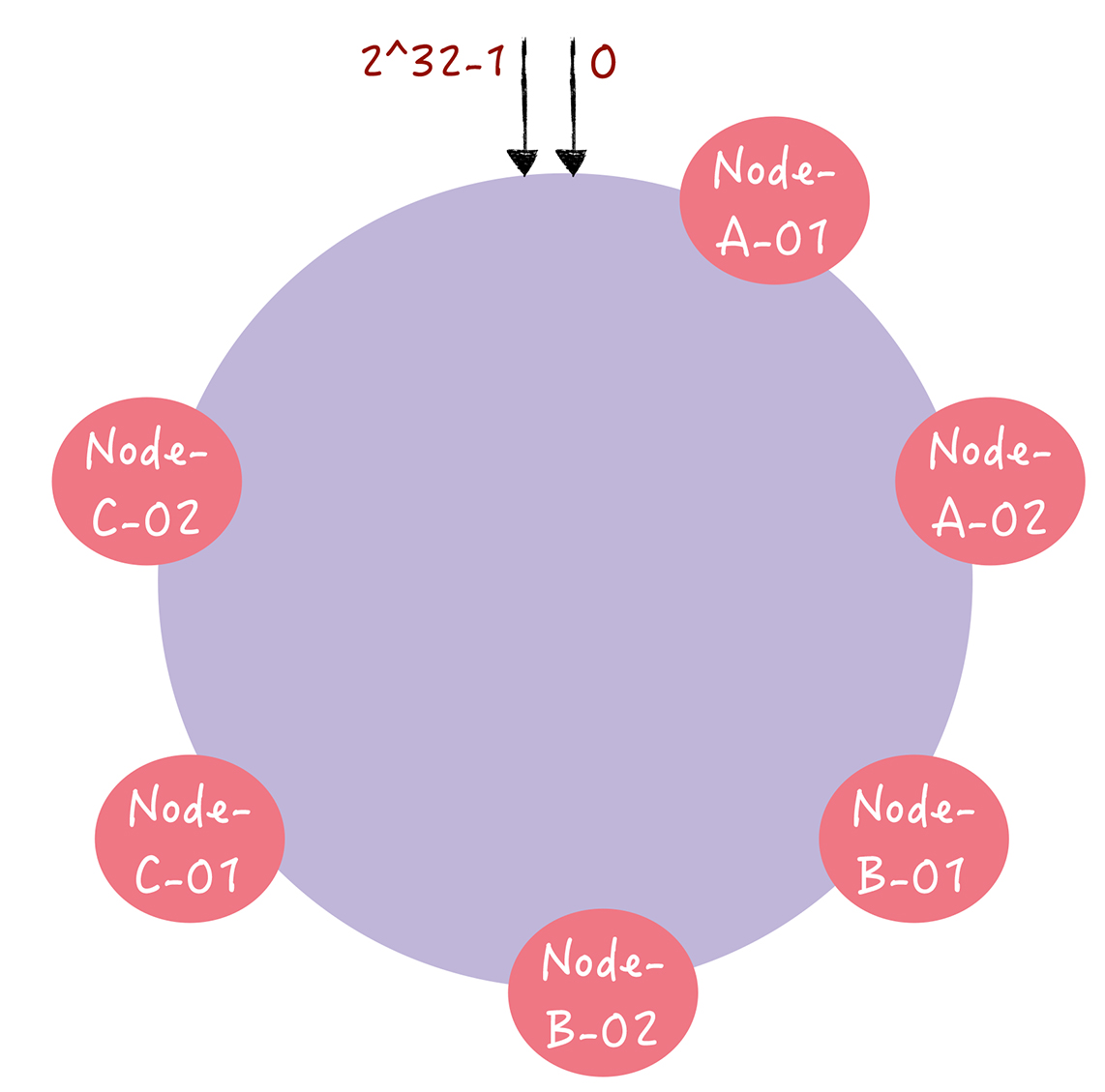
A medida que aumenta el número de nodos, la distribución será naturalmente pareja. Al direccionar, se calcula el valor hash de la clave y se busca el nodo virtual que debe seleccionarse en el sentido de las agujas del reloj en el anillo. Por ejemplo, la clave 01 selecciona el nodo virtual nodo B-02, luego la solicitud se asigna al nodo real B.
Los nodos virtuales expanden el número de nodos y resuelven el problema de que los datos se inclinan fácilmente cuando hay pocos nodos y el costo es muy pequeño. Solo necesita agregar un diccionario para mantener la relación de mapeo entre nodos reales y nodos virtuales.
Darse cuenta:
Referencia:
- Columna de tiempo geek: https://time.geekbang.org/column/article/207426