arquitectura de planificación en el segundo de programación de dos niveles está programado para completar el marco, por lo general se calcula un marco, tal como Hadoop, Spark similares;
programadores a base de estos cálculos marco, pueden completar el cálculo de diferentes tipos y tamaños.
La naturaleza de la computación distribuida se encuentra en un entorno distribuido, la coordinación de varios procesos para completar un asunto complejo;
cada proceso de cumplimiento de sus funciones, después de la finalización de su trabajo, y luego a los demás procesos a otra obra completa;
pues no hay dependencia trabajo, entre procesos puede ejecutar en paralelo.
1 MapReduce
La idea central: divide y vencerás, de JDK-Tenedor de Ingreso es en este marco de pensamiento
pasos:
1 una vista despiezada problema original (mapa): problema original se descompone en una serie de pequeños, independientes entre sí, y los mismos problemas en la forma de los originales sub-problemas;
2 subproblemas: Si subproblemas más pequeños para ser resueltos directa y fácilmente resueltos, de lo contrario de forma recursiva la solución de cada sub-problema;
3 La solución combinada (Reducir): La solución de los problemas de varios sub-fusionaron en la solución problema original
MapReduce incluye principalmente los siguientes tres componentes:
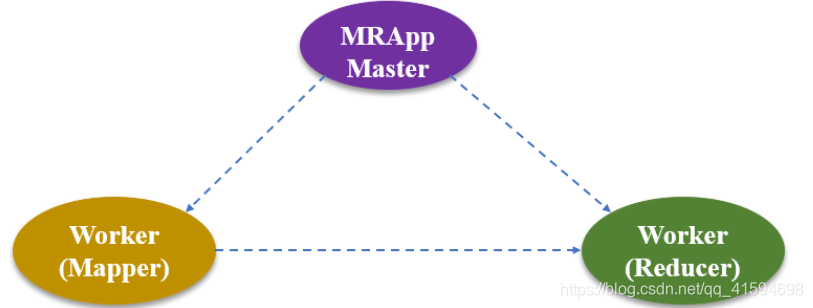
Maestro (MRAppMaster): responsables de la asignación de tareas, la ejecución de tareas de coordinación y el mapa de asignación es la función Mapper () para manipular, para asignar Reductor reducir la operación de la función ();
trabajador Mapper: función de mapa es responsable de la función, es decir, y es responsable de la ejecución de sub-tareas
resultados función Reducir es responsable de la función, que es responsable de la síntesis de cada sub-tarea: trabajador Reductor
diagrama de flujo de trabajo:
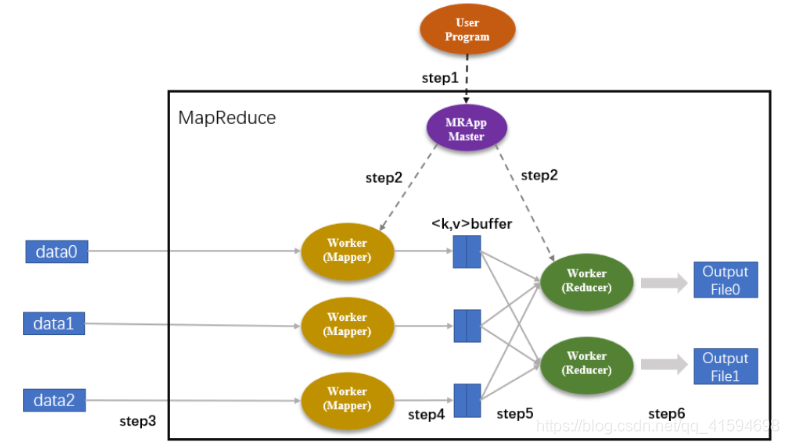
Después de ejecutar tareas de MapReduce para completar todo el proceso de la tarea ha terminado, es un modo de misión corta;
inicio y proceso de la tarea parada es muy lento, por lo MapReduce no es adecuado para tareas de procesamiento en tiempo real: lo hará de datos primero recoger y su caché, espera hasta que la caché son datos completos de procesamiento de inicio. Por lo tanto, un inconveniente es que el grueso calculado, a partir de la adquisición de datos para el momento de los resultados del cálculo obtenido por un largo tiempo
2 Stream
La tarea principal es hacer frente a la en tiempo real para la transmisión de datos, requisitos de retardo de procesamiento, por lo general requiere un proceso de servicio permanente, a la espera de la llegada de los datos en cualquier momento, en cualquier momento, con el fin de asegurar una baja latencia;
calcular la modalidad de la tarea Flujo de datos, en campo distribuido llamado Stream.
En el que el flujo de datos: como los datos de audio y vídeo en directo corriente generada
Los datos continuos llegar rápidamente;
datos a gran escala (TB, PB);
altos requerimientos en tiempo real, con el tiempo, reducirá significativamente el valor de los datos
Los datos no pueden garantizar el orden, lo que significa que el sistema no puede controlar el orden de los elementos de datos a ser procesados.
Una vez que los datos serán procesados inmediatamente, cuando se procesa un conjunto de datos, almacenados en la memoria caché se serializan, y luego transmitidos por la red inmediatamente al siguiente nodo, continúa para procesar el siguiente nodo;
cálculo de flujo, no se almacenará cualquier dato, habría estado en circulación
pasos:

Con el fin de procesamiento oportuno de la secuencia de datos, la corriente se debe calcular la latencia marco, escalable y altamente fiable
3 Actor
modo de cálculo MapReduce y corriente, mientras que los datos se trata de manera diferente, pero son un tipo específico de datos (correspondientes a los datos estáticos y datos dinámicos) se calcula como una dimensión
tubería Actor y el proceso o procesos se calculan como una dimensión de
Actor representa un paralelo distribuido modelo de computación;
este modelo tiene su propio conjunto de reglas que la lógica interna del cálculo de una Actor, y una comunicación entre la pluralidad de reglas Actor;
en el modelo Actor, cada sistema corresponde Actor de un componente, es la unidad de cálculo de base;
Modelo de cálculo con la programación orientada a objetos convencional (OOP) es similar a un objeto recibe una solicitud de invocación de método (similar a un mensaje), de este modo para realizar el método;
sin embargo, porque los datos se encapsula en un objeto OOP, no se puede acceder fuera cuando, es decir, de una manera sincronizada accesible por una pluralidad de invocación de método objeto externo, no habrá puntos muertos, los problemas raciales, sistemas distribuidos no puede satisfacer la demanda de alta concurrencia;
el modelo Actor a través de una comunicación de mensajes utilizando el modo asíncrono (cola), supera las limitaciones de programación orientada a objetos, el sistema distribuido adecuado para altamente concurrente.
modelo Actor es tres elementos del estado, de comportamiento y de mensajes: modelo Actor = (+ comportamiento estado) mensaje +
Estado (Estado): Información sobre el componente Actor sí mismo, el equivalente de objetos POO atributos;
el estado será afectada Actor Actor su propio comportamiento, y puede ser cambiado sólo su propiaComportamiento (comportamiento): cálculo Actor operaciones de procesamiento, que corresponde al objeto función OOP miembro;
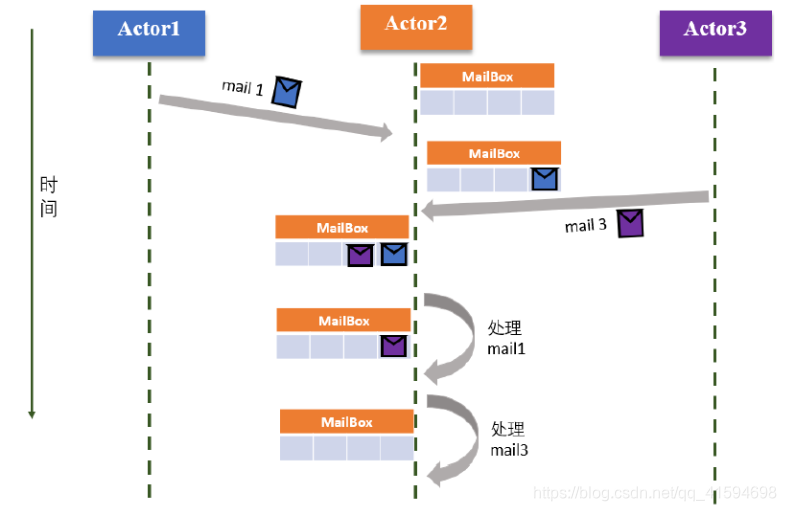
no puede cargar la lógica de cálculo entre otros Actor Actor. Actor recibir mensajes sólo dará lugar a su comportamiento de computaciónMensaje (Mail): Actor mensaje de entrega por la comunicación de correo entre una pluralidad de Actor, Actor tienen cada uno su propio buzón (el buzón de correo), para recibir un mensaje de otro Actor por lo tanto los mensajes modelo Actor, también conocido como correo;
en general, para el mensaje dentro del buzón de correo, leer el Actor se consigue de acuerdo con el mensaje de la orden (FIFO) y se procesa
Principio de funcionamiento: ver la cola de la figura para el procesamiento utilizando Actor2
ventajas:
Para lograr un mayor nivel de abstracción que POO: la comunicación asíncrona entre Actor, Actor múltiple puede funcionar de forma independiente y no se verá afectado, para resolver los problemas de competencia en programación orientada a objetos
Sin bloqueo: Modelo Actor introduciendo el mensaje mecanismo de paso, a fin de evitar la obstrucción
Sin el uso de cerraduras: El agente sólo puede leer un mensaje del buzón de correo, es decir, Actor interna sólo puede ocuparse de un mensaje al mismo tiempo, es un mutex natural, por lo que no bloqueo código adicional
alta concurrente: Cada Actor Buzón solamente de procesamiento de mensajes local, y por lo tanto una pluralidad de trabajo Actor paralelo, mejorando de este modo todo el sistema de procesamiento paralelo distribuido
Fácil expansión: cada actor puede crear múltiples Actor, reduciendo así la carga de trabajo de un solo actor;
cuando el mango Actor local, sin embargo, se puede iniciar Actor en el nodo remoto reenvía el mensaje en el pasado.
desventajas:
Actor falta de herencia y la estratificación, pequeño código reutilización
Actor crear dinámicamente múltiples Actor, hace que el comportamiento de todo el cambio de modelo de actor, no es fácil de lograr
aumento actor, sino que también aumentaría la sobrecarga del sistema
No se aplica a los sistemas de requisitos estrictos para la secuencia de procesamiento de mensajes,
ya que los mensajes son mensajes asíncronos, no se puede determinar el orden de ejecución de cada mensaje;
mejoras: Se puede pedir a resolver el problema mediante el bloqueo de actor, pero afectará seriamente el modelo de tarea de la eficiencia Actor
Escena: Akka
4 líneas
Una gran tarea en varios pasos, procesos diferentes pueden ser empleados en diferentes etapas llevadas a cabo, por lo que las diferentes tareas se pueden realizar en paralelo, mejorando así la eficiencia del sistema
Escena: procesamiento en paralelo de aprendizaje automático
modo de MapReduce y el modo de canalización, habrá una gran tarea en múltiples subtareas, la diferencia es que la relación entre el tamaño de partícula y subtareas divisorias:
tarea granularidad MapReduce, la tarea se divide en una gran pluralidad de tareas más pequeñas, cada tarea tiene que realizar una, el mismo paso completo, la misma tarea se puede ejecutar en paralelo, puede decirse que es un paralelo de computación modelo de tarea;
tubería computación modo de tamaño de paso, una tarea en múltiples pasos, cada uno realizado por un diferentes tipos de lógica de la pluralidad de tareas por el mismo paso para solapar la aplicación paralela de diferentes tareas de computación, puede decirse que es un patrón paralelo de datos .MapReduce respectiva sub-tarea puede ser realizada de forma independiente, sin molestar a los otros, una pluralidad de subtareas ejecutado, los resultados combinados para dar los resultados generales de la tarea, y por lo tanto no se requiere entre las dependencias sub-tareas;
el modo de canalización se encuentra entre la pluralidad de subtareas tienen una relación de dependencia, la salida de una subtarea de entrada anterior después de una subtarea
MapReduce paralelismo de tareas para el escenario de modo de cálculo, el modo de cálculo pipeline para la escena del mismo tipo de tarea de procesamiento de datos en paralelo.
