
Enlace original:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Dian_SHAO_Find_and_Focus_ECCV_2018_paper.pdf
Motivación
Recuperar video basado en texto en lenguaje natural es una de las tecnologías clave en la actualidad. El surgimiento de plataformas de video cortas ha traído más desafíos a esta tarea: la duración del video y la diversidad de contenido han aumentado significativamente. El método de recuperación tradicional codifica todo el video en un vector de características, ignorando las características locales y, por lo tanto, no tiene la capacidad de realizar una localización temporal basada en el texto.
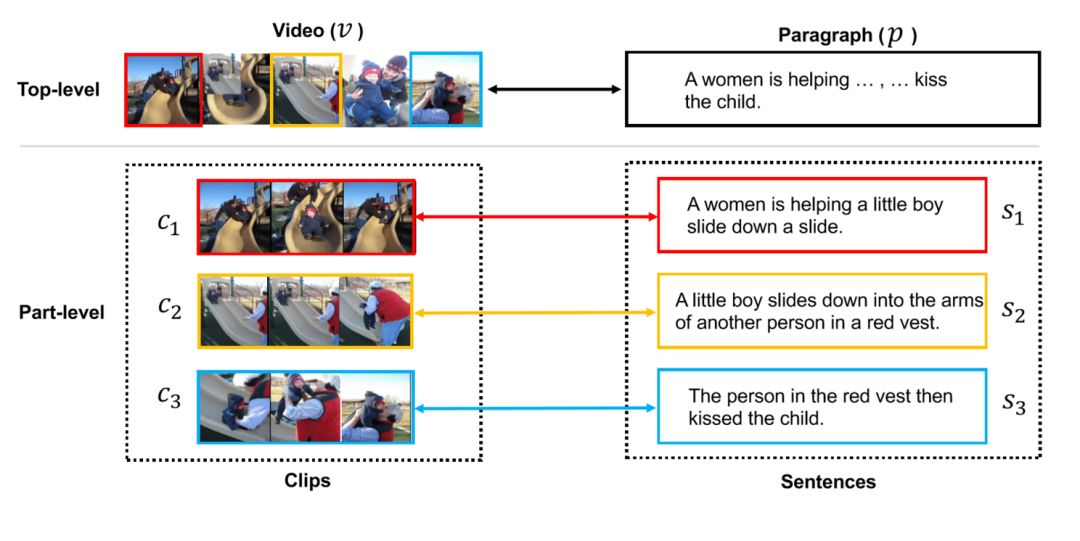
La figura anterior explica los conceptos de nivel superior y parcial. A nivel global, un video completo se combina con un párrafo de texto; a nivel local, cada oración en el párrafo corresponde a un clip en el video.
Descripción general del marco


El autor propone una red FIFO. La tarea principal es: primero seleccionar un cierto número de videos candidatos (Buscar, global) de acuerdo con el párrafo de texto, y luego realizar la localización del clip en cada video candidato para identificar la conexión entre cada oración y el video clip (Enfoque, parcial), y finalmente ajuste el resultado de recuperación inicial de acuerdo con el resultado del cálculo de Enfoque.
Localización de clips
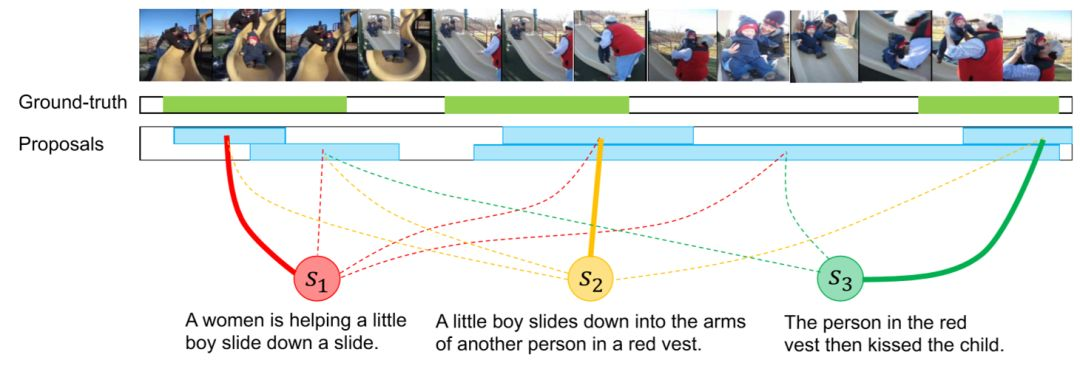
La figura anterior muestra el proceso de posicionamiento del segmento. Dado el video y el texto, se utiliza un método semánticamente sensible para seleccionar los clips candidatos (propuesta de clip). Cada oración puede asociarse con varios clips, de los cuales los más relevantes se indican con líneas gruesas.
Extracción de características

Los párrafos de video y texto están representados por las características de los fragmentos T (pequeños videoclips de 6 cuadros consecutivos) y las características de las oraciones M, que son generadas por la CNN de dos secuencias.
Propuesta de clip

Para la oración Si y el fragmento j, el coseno del ángulo incluido se usa como la correlación semántica entre Fj y Si. Use este método para seleccionar el fragmento asociado con cada oración del párrafo. Algunos fragmentos consecutivos se convierten en un clip, generando así una serie de clips candidatos.
Cross-domain Matching
Como se muestra en la figura, el objetivo es maximizar la expresión a la izquierda, donde Xij es si la oración i y el segmento j están relacionados (parámetro objetivo a optimizar), y Rij es la relevancia semántica de la oración i y el segmento j.
Al optimizar Xij, se deben cumplir dos condiciones: (1) cada oración específica está relacionada con, como máximo, segmentos Umax; (2) cada segmento está relacionado con, como máximo, una oración.
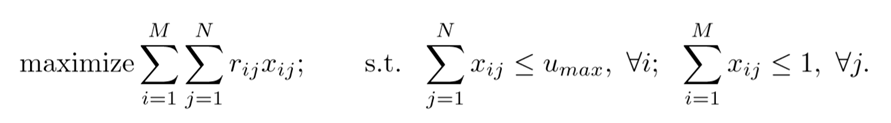
Rij se define por el tipo izquierdo en la figura a continuación, donde Gj es la característica del videoclip j y se define por el tipo correcto, Cj es el fragmento establecido en el clip actual y Ft es la característica del fragmento t-th.
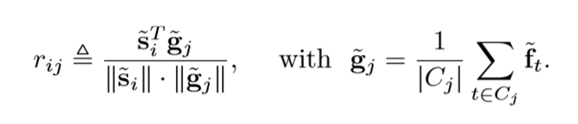
El puntaje objetivo de optimización en esta sección se llama Sp (V, P), que es una correlación de nivel parcial.
FIFO
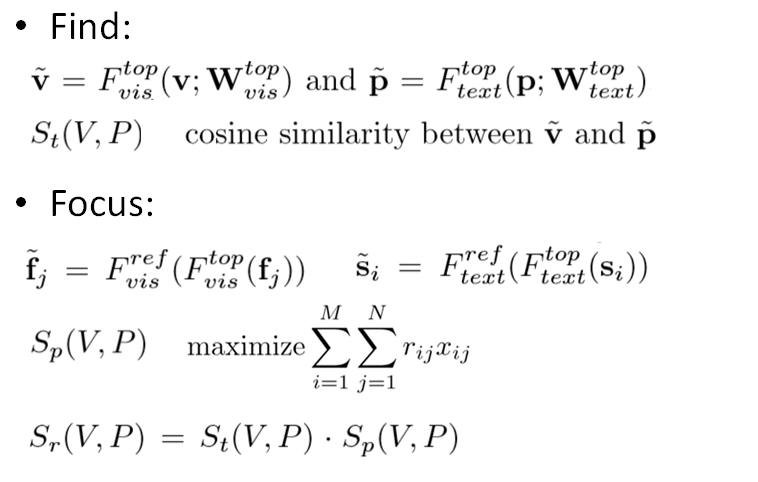
A continuación se describe la estructura general de la red FIFO. En la sección de búsqueda de nivel superior, para el video v y el párrafo p, use las dos redes F_top_vis y F_top_text para incrustar para obtener las características v ~ y p ~. La puntuación de objetivo de optimización de nivel superior St (V, P) se establece en el coseno del ángulo entre v ~ y p ~.
Las características se ajustan a nivel de parte, para lo cual se entrenan las redes F_ref_vis y F_ref_text, y luego los fj ~ y si ~ obtenidos se sustituyen en la expresión Sp (V, P) en la parte anterior para la optimización. Finalmente, el objetivo de optimización del nivel superior se ajusta a Sr (V, P), definido como el producto de los puntajes de los dos objetivos de optimización anteriores, para ajustar el resultado de Buscar.
Entre ellos, la red utilizada como incrustación se entrena optimizando la siguiente función de pérdida. α y β como hiperparámetros se establecen en 0.2 y 0.1, respectivamente. c + es cualquier segmento candidato con IoU mayor que 0.7, L es el número de muestras negativas con IoU menor que 0.3, y tanto St como sr son similitudes de coseno.
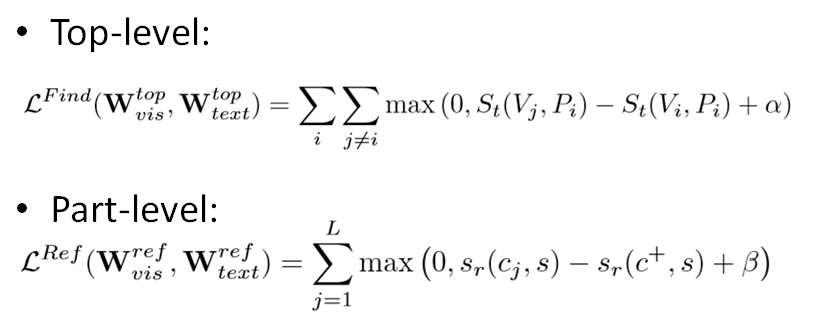
Los experimentos
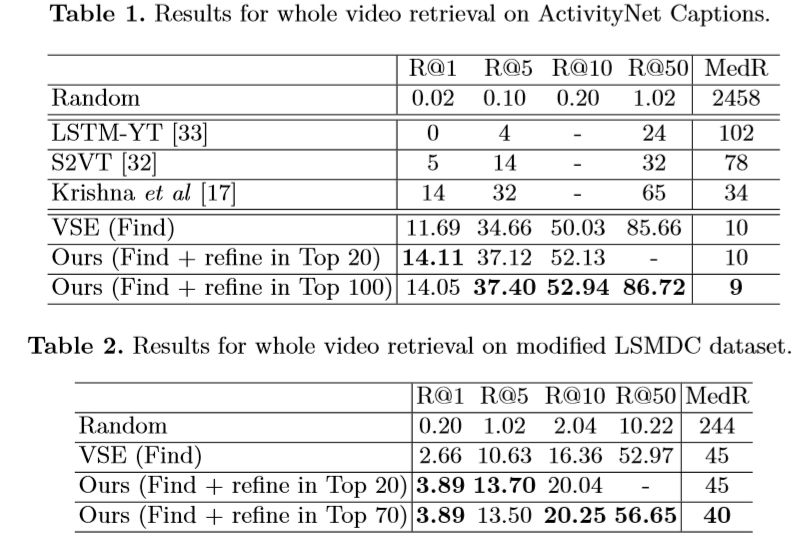
En los dos conjuntos de datos de ActivityNet Captions y LSMDC, el autor compara los efectos de nivel superior de la red FIFO con otros modelos en el mismo período y los modelos que no se han sometido a pasos de refinamiento (es decir, solo Buscar). Donde R @ N representa (después de múltiples experimentos) la proporción de muestras de verdad fundamental en los N fragmentos de candidatos superiores, y MedR representa la mediana de la clasificación de las muestras de verdad fundamental.
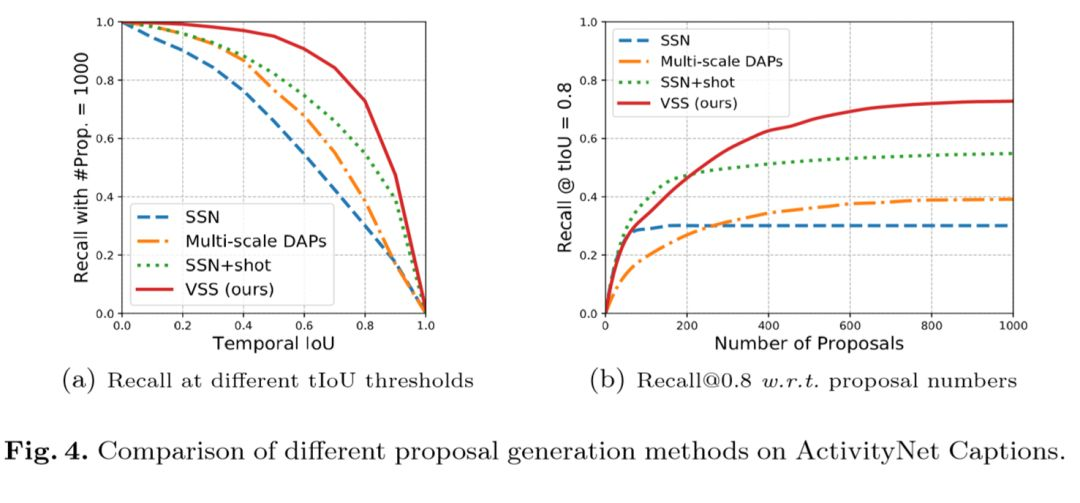
Luego, los autores evaluaron la efectividad de su método de generación de región semántica candidato (similitud semántica visual, VSS). El gráfico de la izquierda muestra las tasas de recuperación de diferentes modelos bajo diferentes umbrales de IoU. El gráfico de la derecha muestra la tendencia de la tasa de recuerdo a medida que aumenta el número de candidatos. Se puede ver que el efecto de VSS excede el de otros modelos.
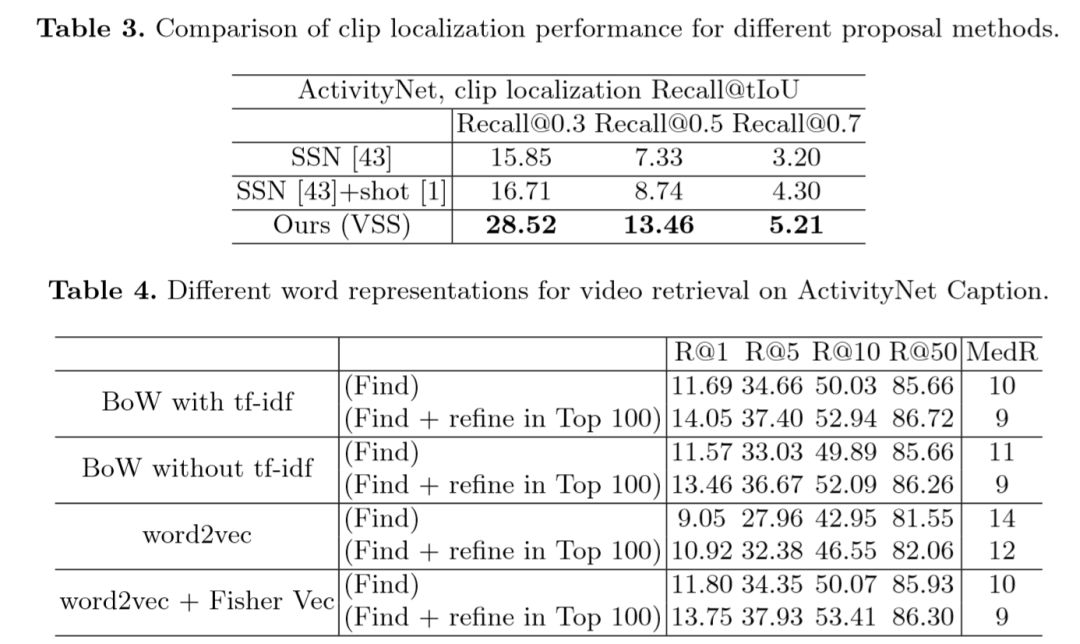
En la Tabla 3, el autor compara los efectos de los diferentes métodos de generación de regiones candidatas, y VSS logró los mejores resultados. La Tabla 4 compara los efectos de diferentes métodos de incrustación de texto y se puede ver que Fisher Vector y tf-idf ofrecen mejores resultados.
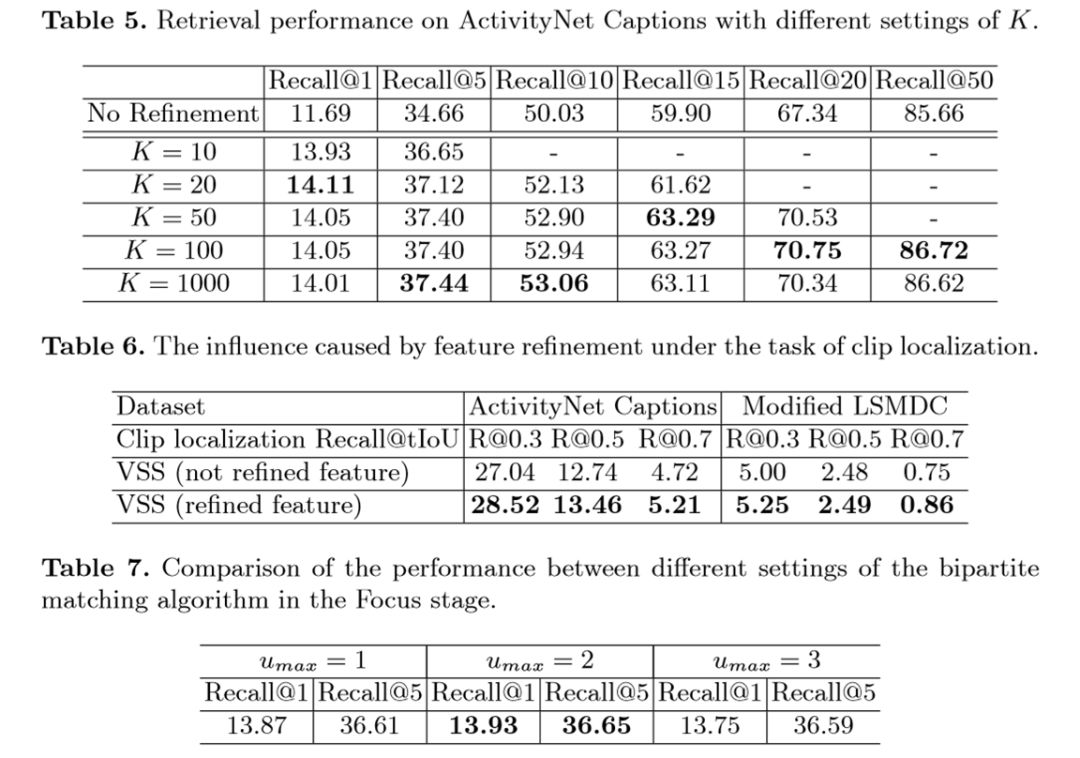
La Tabla 5 muestra el efecto del hiperparámetro K en la tasa de recuperación. K representa la cantidad de videos candidatos generados en el paso Buscar. Una K mayor generalmente trae mejores resultados, pero también genera mayores costos computacionales. El experimento encontró que a medida que K aumenta, la tasa de recuperación se satura gradualmente.
La Tabla 6 muestra que la función de ajuste (usando F_ref_vis y F_ref_text) en el paso de enfoque brinda mejores resultados.
La Tabla 7 compara el efecto de diferentes valores de Umax en el paso Propuesta de Clip. La tasa de recuperación más alta es cuando Umax = 2 (es decir, una oración está relacionada con, como máximo, dos videoclips).
Resultados cualitativos

Finalmente, el autor mostró el efecto de cuantificación del posicionamiento del segmento: los diferentes segmentos están representados por diferentes colores. En el primer ejemplo, el resultado es más preciso, y en el segundo ejemplo, el segmento rojo se desvía.