Escribir en frente
El código o seudocódigo del artículo es un extracto en línea, ¡y mi código es privado!
hw2
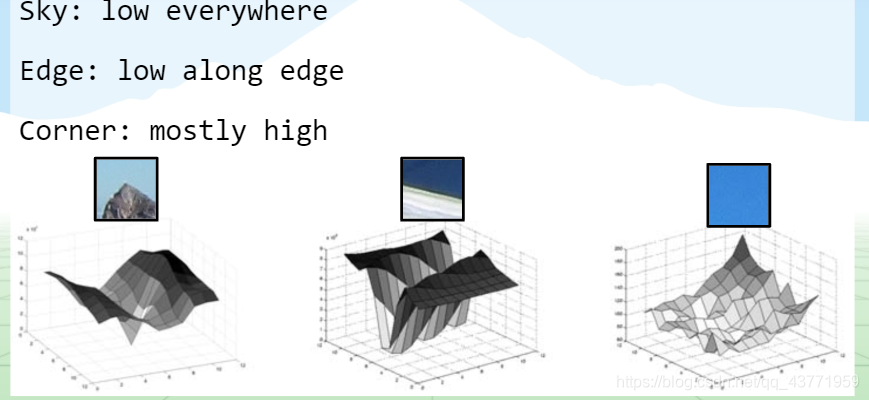
1. Detección de la esquina de Harris
Cálculo del punto de característica

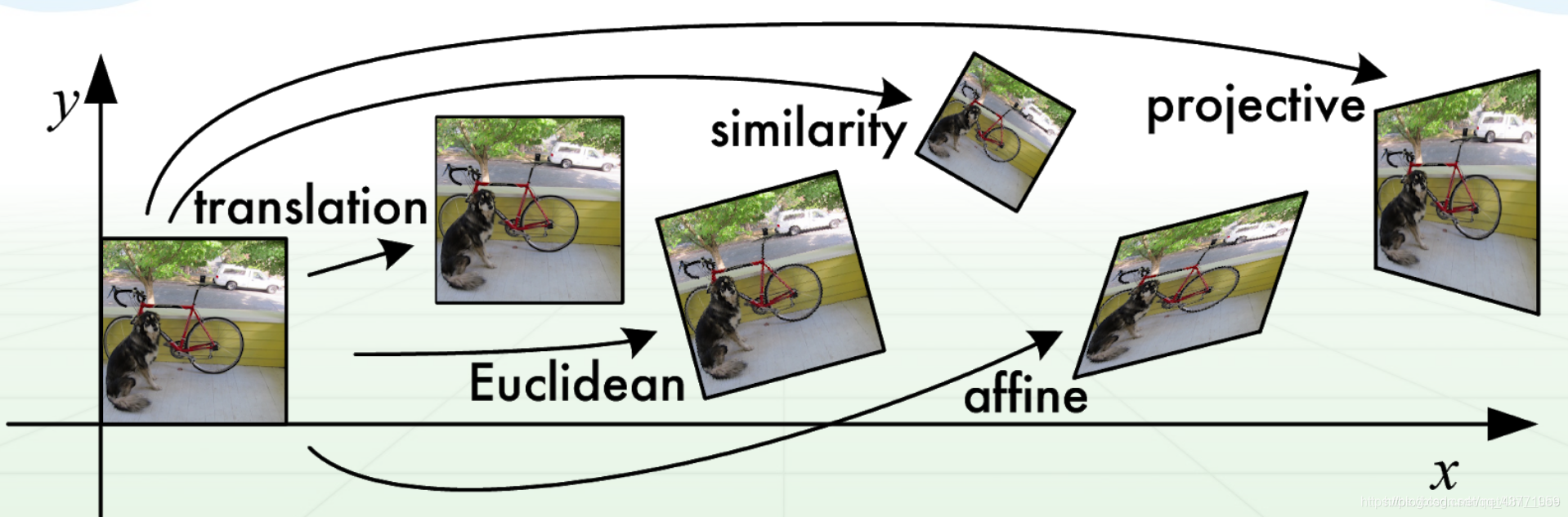
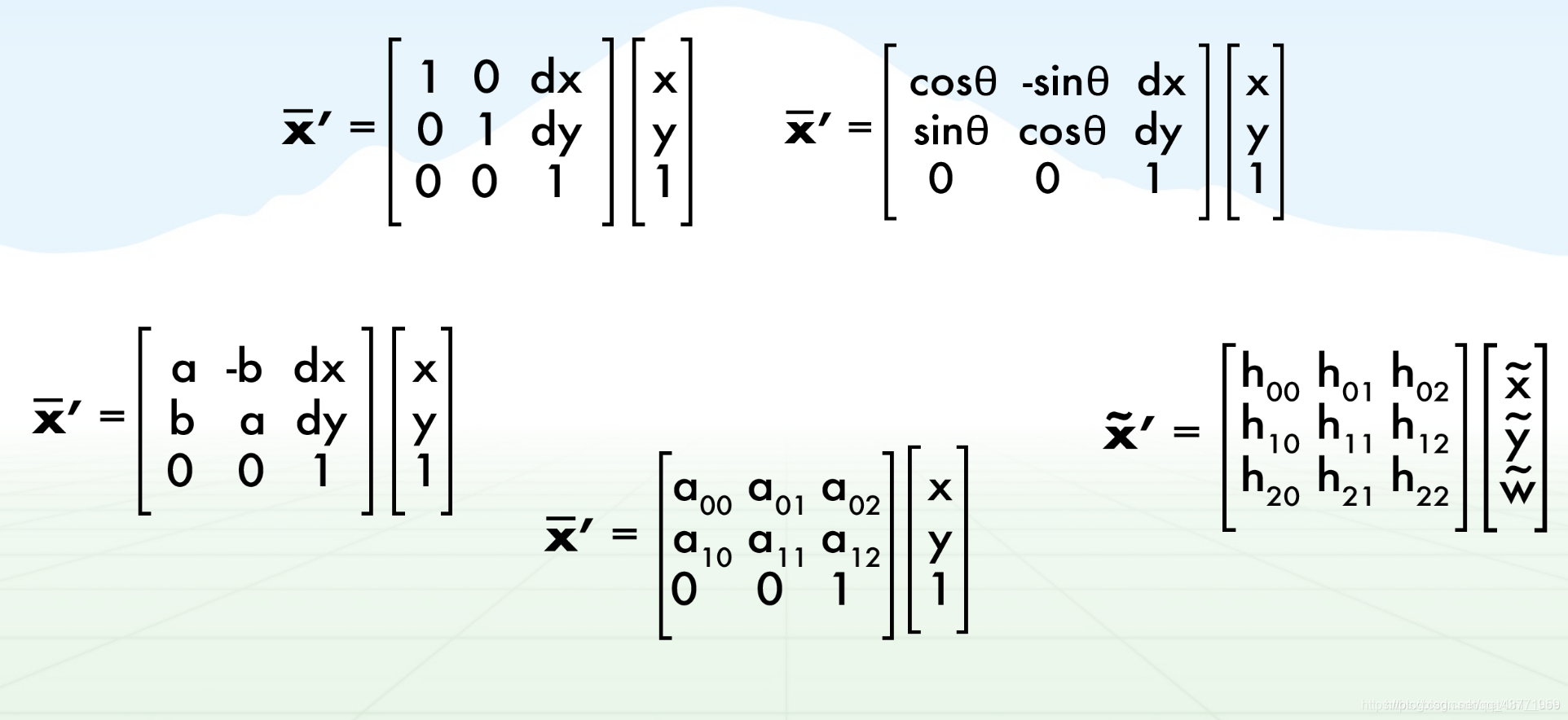
Afín: (transformación de coordenadas esencial)

supresión no máxima (NMS)
Cuando se realiza la detección de objetivos, generalmente se adopta un método de deslizamiento de ventana para generar muchos cuadros candidatos en la imagen, y luego estos cuadros candidatos se someten a extracción de características y luego se envían al clasificador. En general, se obtiene una puntuación, como la detección de rostros , Habrá puntajes en muchos cuadros y luego todos estos puntajes se ordenarán. Seleccione el cuadro con la puntuación más alta y luego calcule el grado de superposición (iou) de los otros cuadros con el cuadro actual. Si el grado de superposición es mayor que un cierto umbral, elimínelo, porque puede haber varios cuadros con puntuaciones altas en la misma cara Es un rostro humano pero no necesita ser enmarcado. Solo necesitamos uno.
Atraviese el resto de los cuadros, si el área de superposición (IOU) con el subtrama más alto actual es mayor que un cierto umbral, eliminaremos el cuadro
Código MATLAB encontrado en línea
%% NMS:non maximum suppression
function pick = nms(boxes,threshold,type)
% boxes: m x 5,表示有m个框,5列分别是[x1 y1 x2 y2 score]
% threshold: IOU阈值
% type:IOU阈值的定义类型
% 输入为空,则直接返回
if isempty(boxes)
pick = [];
return;
end
% 依次取出左上角和右下角坐标以及分类器得分(置信度)
x1 = boxes(:,1);
y1 = boxes(:,2);
x2 = boxes(:,3);
y2 = boxes(:,4);
s = boxes(:,5);
% 计算每一个框的面积
area = (x2-x1+1) .* (y2-y1+1);
%将得分升序排列
[vals, I] = sort(s);
%初始化
pick = s*0;
counter = 1;
% 循环直至所有框处理完成
while ~isempty(I)
last = length(I); %当前剩余框的数量
i = I(last);%选中最后一个,即得分最高的框
pick(counter) = i;
counter = counter + 1;
%计算相交面积
xx1 = max(x1(i), x1(I(1:last-1)));
yy1 = max(y1(i), y1(I(1:last-1)));
xx2 = min(x2(i), x2(I(1:last-1)));
yy2 = min(y2(i), y2(I(1:last-1)));
w = max(0.0, xx2-xx1+1);
h = max(0.0, yy2-yy1+1);
inter = w.*h;
%不同定义下的IOU
if strcmp(type,'Min')
%重叠面积与最小框面积的比值
o = inter ./ min(area(i),area(I(1:last-1)));
else
%交集/并集
o = inter ./ (area(i) + area(I(1:last-1)) - inter);
end
%保留所有重叠面积小于阈值的框,留作下次处理
I = I(find(o<=threshold));
end
pick = pick(1:(counter-1));
end
2. Parche a juego
Medida de distancia:
Σx, y (I (x, y) -J (x, y)) 2

encuentra la mejor coincidencia
Algoritmo de consenso de muestra aleatoria (RANSAC)
Estime iterativamente los parámetros del modelo matemático a partir de un conjunto de datos observados que contienen valores atípicos.
① Considere un modelo con un potencial mínimo de conjunto de muestreo de n (n es el número mínimo de muestras requerido para inicializar los parámetros del modelo) y un conjunto de muestra P, el número de muestras en el conjunto P # §> n, seleccione aleatoriamente n muestras de P El subconjunto S de P inicializa el modelo M;
② El conjunto de muestra cuyo error en el conjunto residual SC = P \ S es menor que un determinado umbral de conjunto t y S constituye S *. S se considera un conjunto de puntos interiores, y constituyen un conjunto consistente de S (Conjunto de consenso);
#Si # (S ) ≥N, se considera que se obtienen los parámetros correctos del modelo y se utiliza el método de mínimos cuadrados utilizando el conjunto S * (inliers) Vuelva a calcular el nuevo modelo M *; extraiga aleatoriamente una nueva S y repita el proceso anterior.
④ Después de completar un cierto número de muestreos, si no se encuentra el conjunto consistente, el algoritmo falla; de lo contrario, el conjunto consistente más grande obtenido después del muestreo se usa para juzgar los puntos internos y externos, y el algoritmo finaliza.
El algoritmo de pseudocódigo es el siguiente: (en línea)
输入:
Data 一组观测数据
Model 适应于数据的模型
n 适应于模型的最小数据个数
k 算法的迭代次数
t 用于决定数据是否适应于模型的阈值
d 判定模型是否适用于数据集的数据数目
参考链接:http://blog.csdn.net/pi9nc/article/details/26596519
Best_model 与数据最匹配的模型参数(没有返回null)
Best_consensus_set 估计出模型的数据点
Best_error 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
Algoritmo de SIFT detallado
https://blog.csdn.net/zddblog/article/details/7521424
