Python experimento básico uno
Tarea 1:
Ingrese un conjunto de datos desde el teclado, escriba un programa y calcule el promedio, la desviación estándar y la mediana del conjunto de datos. El resultado de salida conserva
un lugar decimal.
Muestra de entrada 1
99 98 97 96 95
Muestra de salida 1
promedio: 97.0 varianza: 1.6 mediana: 97.0
Muestra de entrada 2
99 98 97 96 95 94
muestra de salida 2
promedio: 96.5 varianza: 1.9 mediana: 96.5
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
import numpy as np
list1 = []
list2 = []
list1 = str(input()).split(' ')
for i in list1:
list2.append(int(i))
a = np.array(list2)
print(a)
# avg = sum(list2)/(len(list2))
print('avg:{0:.1f} variance:{1:.1f} median:{2:.1f}'.format(np.average(a), np.std(a), np.median(a)))
Tarea 2:
Requisitos de programación Una
barra de progreso es un medio importante comúnmente utilizado por las computadoras para procesar tareas o ejecutar software para mejorar la experiencia del usuario. Puede mostrar el
progreso de tareas o software en tiempo real .
En su forma más simple, puede usar la función print () para implementar una barra de progreso de texto simple y no refrescante. La idea básica es
dividir la tarea completa en 100 unidades de acuerdo con el porcentaje de ejecución de la tarea , y generar una barra de progreso cada vez que se ejecuta N%. Cada línea de salida contiene un porcentaje de progreso
, dos caracteres que
representan la parte completada ( ) y la parte incompleta (...), y una pequeña flecha que sigue el grado de finalización , el estilo es el siguiente: % 10 [**** - > ...] en curso de reclamación de la barra de progreso teclado utilizado para bucle y de impresión () cuerpo del procedimiento de configuración de la función, la salida de un centenar de puntos de los que el más alto (100%) de los datos de 3 bits, para la mirada de salida ordenada, que se puede utilizar {: 3.0f} Formatea la parte de porcentaje. Muestra de entrada 1 10 Muestra de salida 1 % 0 [->…] % 10 [ ->…]
% 20 [ ->…]
% 30 [ ->…]
% 40 [ ->…]
% 50 [ ->… ]
% 60 [ ->…]
% 70 [ ->…]
% 80 [ ->…]
% 90 [->…]
% 100 [ ************ ->]
El proceso ha finalizado, código de salida 0
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
# 非刷新的文本进度条
import time
x = eval(input())
for i in range(x + 1):
a = "**" * i
b = ".." * (x - i)
c = i / x * 100
print("%{:3.0f}[{}->{}]".format(c, a, b))
Tarea tres:
la programación de los requisitos
estadísticos Inglés frecuencia de palabras, leer un artículo de un archivo Text_word_frequency_statistics.txt, la salida del artículo es las más
palabras que ocurren comúnmente y aparece 10 veces, para el mismo número de veces que una palabra aparece, entonces lexicográfico claves Para
ordenar, debe excluir, y, de, a, i, in, you, my, he y his. El formato de salida es "{0: <10} {1:> 5}".
Consejo: El
primer paso: descomponer y extraer palabras de artículos en inglés. La misma palabra puede tener diferentes formas de mayúsculas y minúsculas, pero el recuento no distingue entre mayúsculas y
minúsculas. Todas las letras se pueden convertir a minúsculas, para excluir la interferencia del caso de texto original en las estadísticas de frecuencia de palabras. Las
palabras en inglés se pueden separar por espacios, signos de puntuación o símbolos especiales. Para un método de separación uniforme, puede reemplazar varios caracteres especiales
y signos de puntuación con espacios y luego extraer palabras.
Paso 2: cuenta cada palabra.
Parte 3: Ordene las estadísticas de palabras de mayor a menor. Si las estadísticas son las mismas, ordénelas en orden ascendente por valor de clave.
文件 Text_word_frequency_statistics.txt :
Café salado La
conoció en una fiesta. Ella fue sobresaliente; muchos tipos la perseguían, pero nadie le prestó atención. Después de la fiesta, la invitó a tomar un café. Ella estaba sorprendida. Para no parecer grosero, ella siguió.
Mientras estaban sentados en una bonita cafetería, él estaba demasiado nervioso para decir algo y ella se sintió incómoda. De repente, le preguntó al camarero: "¿Podrías darme un poco de sal?" Me gustaría ponerlo en mi café.
Lo miraron fijamente. Se puso rojo, pero cuando llegó la sal, la puso en su café y bebió. Curiosa, preguntó: "¿Por qué poner sal en el café?" Explicó: “Cuando era niño, vivía cerca del mar. Me gustaba jugar en la playa ... podía sentir su sabor salado, como el café salado. Ahora, cada vez que lo bebo, pienso en mi infancia y en mi ciudad natal. Lo extraño y mis padres, que todavía están allí ".
Ella estaba profundamente conmovida. Un hombre que puede admitir que siente nostalgia debe amar su hogar y preocuparse por su familia. Él debe ser responsable.
También habló sobre su lejana ciudad natal, su infancia, su familia. Ese fue el comienzo de su historia de amor.
Continuaron saliendo. Ella descubrió que cumplía con todos sus requisitos. Era tolerante, amable, cálido y cuidadoso. ¡Y pensar que se habría perdido la pesca si no hubiera sido por el café salado!
Entonces se casaron y vivieron felices juntos. Y cada vez que le preparaba café, le ponía un poco de sal, como a él le gustaba.
Después de 40 años, falleció y le dejó una carta que decía:
Querida, perdona mi mentira de toda la vida. Recuerdas la primera vez que salimos? Estaba tan nervioso que pedí sal en lugar de azúcar.
Fue difícil para mí pedir un cambio, así que seguí adelante. Nunca pensé que nos llevaríamos bien. Muchas veces, intenté decirte la verdad, pero temía que arruinara todo.
Cariño, no me gusta exactamente el café salado. Pero como te importó tanto, aprendí a disfrutarlo. Tenerte conmigo fue mi mayor felicidad. Si pudiera vivir por segunda vez, espero que podamos volver a estar juntos, incluso si eso significa que tengo que tomar café salado por el resto de mi vida.
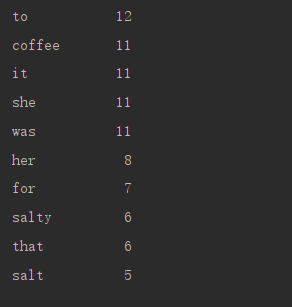
输出 样例 1
a 12
cafés 11
it 11
ella 11
tenía 11 años
8
por 7
salados 6
que 6
sal 5
"""
# @Time : 2020/4/9
# @Author : JMChen
"""
with open('Text_word_frequency_statistics.txt', 'r')as f:
f = f.read().lower()
for ch in '!,".:?;':
f = f.replace(ch, '')
l = f.split()
l.sort()
countDict = {}
for word in l:
if word in ['the', 'and', 'of', 'a', 'i', 'in', 'you', 'my', 'he', 'his']:
continue
else:
countDict[word] = countDict.get(word, 0) + 1
cList = list(countDict.items())
cList.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
w, c = cList[i]
print('{0:<10}{1:>5}'.format(w, c))
Nota: Si los valores estadísticos son los mismos, se organizan en orden ascendente de acuerdo con el valor clave.
