En el primer capítulo, la descripción general de IP menciona que Internet es una red de redes . Solo cuando la red y la red están conectadas entre sí, los datos en la red pueden compartirse y los hosts pueden conectarse. Sabemos que Internet se compone de muchas redes conectadas entre sí, entonces, ¿cómo pueden los paquetes de datos enviados por los usuarios llegar a sus destinos con precisión? Aquí debe comprender el protocolo de la capa IP.
Comunicación en la capa IP
Comunicación de capa IP
La comunicación orientada a la conexión significa que la conexión se establece antes de que las dos partes se comuniquen (es decir, se establece un circuito virtual en el intercambio de paquetes) para reservar todos los recursos de red necesarios para la comunicación entre las dos partes, y la comunicación entre las dos partes se transmite a lo largo del circuito virtual establecido. Agrupación, la necesidad de liberar el circuito virtual establecido después de la comunicación. Este modo se basa en la comunicación de la red de telecomunicaciones. Como se muestra en la figura, los paquetes intercambiados entre los hosts H1 y H2 deben transmitirse en el circuito virtual establecido de antemano.
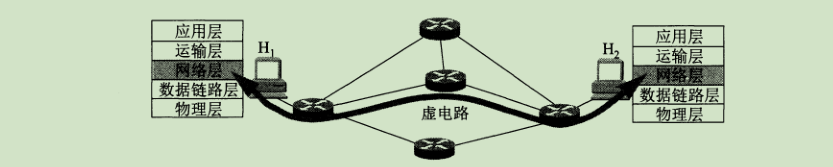
- La comunicación sin conexión sin
conexión significa que no hay necesidad de establecer una conexión cuando se envían paquetes. Cada paquete se envía de forma independiente, independientemente de los paquetes anteriores y posteriores. Este método de transmisión no es confiable. Como se muestra en la figura, cuando se intercambian paquetes entre los hosts H1 y H2, cada paquete puede seleccionar un enlace diferente para la transmisión, y el orden de llegada puede ser diferente.
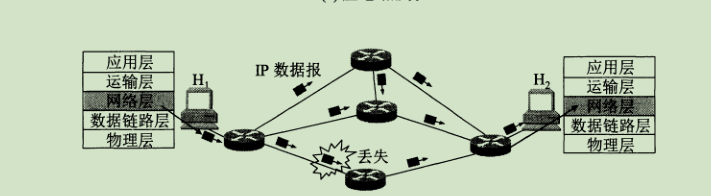
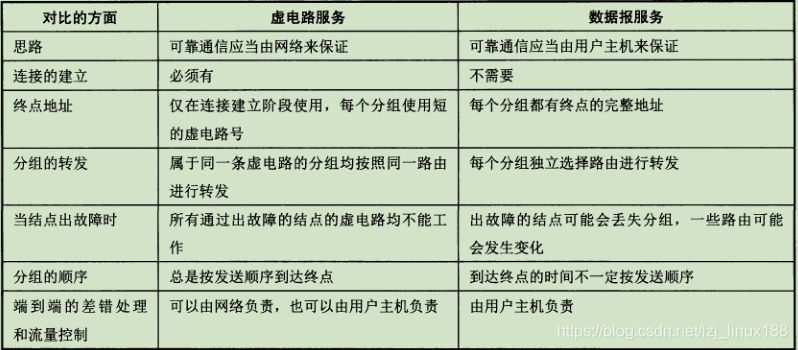
La siguiente figura es una comparación entre orientado a conexión y sin conexión.
Los protocolos actuales de la capa de red utilizan la transmisión de datos sin conexión. Es decir, no es necesario establecer un circuito virtual por adelantado para intercambiar paquetes entre hosts, por lo que la capa de red no ofrece una promesa de calidad de servicio, y la capa de red solo proporciona servicios de datagramas simples, flexibles, sin conexión y de mejor esfuerzo . La razón por la cual se adopta el método sin conexión es porque el host en el sistema de red tiene inteligencia (es decir, puede manejar errores), y el teléfono en la red de telecomunicaciones tradicional no tiene capacidad. Además, el uso de un método sin conexión puede ahorrar costos y el modo de operación es muy flexible y puede adaptarse a una variedad de aplicaciones.
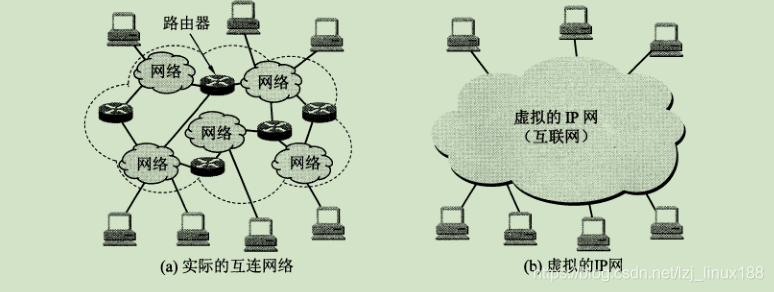
De lo anterior se puede ver que los paquetes de datos en la red usan conmutación sin conexión en la capa de red, por lo que existen diferencias entre varias redes (como diferentes tipos de red, como Ethernet, red de anillo de token, red inalámbrica, etc.; El esquema de direccionamiento y el enrutamiento también pueden ser diferentes), ¿cómo se comunican los datos? Esto se maneja de esta manera, ** Las redes de computadoras que participan en la interconexión usan el mismo protocolo de Internet IP, por lo que la red de computadoras después de la interconexión puede considerarse como una red de interconexión virtual (la red de interconexión virtual también es una red de interconexión lógica) ** La diferencia entre las diversas redes físicas interconectadas de esta manera originalmente existía objetivamente, pero podemos usar el protocolo IP para hacer que estas redes con diferentes rendimientos se vean como una red unificada en la capa de red (ignorando las diversas Detalles heterogéneos específicos de la red física).
Cuando muchas redes heterogéneas están interconectadas por enrutadores, si todas las redes usan el mismo protocolo IP, es muy conveniente discutir problemas en la capa de red. Como se muestra en la figura, el host H1 desea enviar un datagrama IP al host H2 de destino, aunque existen diferentes redes físicas, como enlaces satelitales, enlaces inalámbricos y cables ópticos. Pero todos usan el protocolo IP, por lo que pueden comunicarse normalmente.
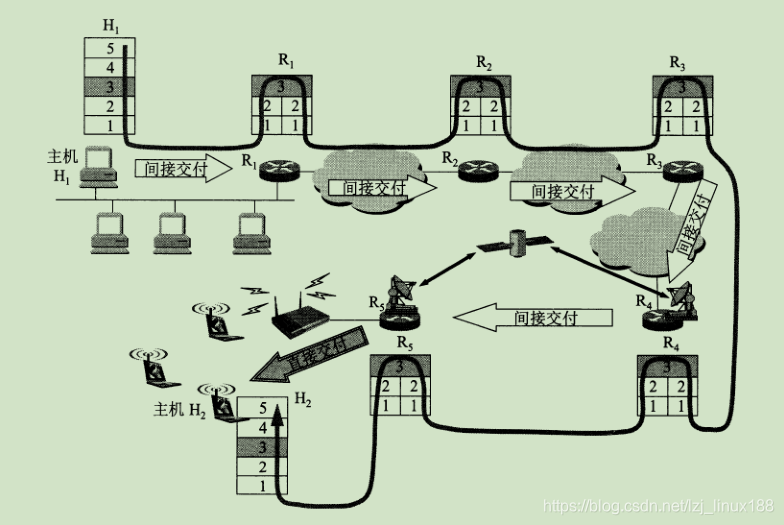
Al comunicarse en Internet, ¿cómo identifica el paquete el host de destino en la red? ¿Cómo puede identificar el paquete H2 enviado por H1 en la figura anterior? Un concepto importante en la comunicación es la dirección del dispositivo. Asigne una dirección única a cada dispositivo en la red para que el grupo sepa a qué dispositivo debe entregar. Se llama una dirección IP en la capa de red. La dirección IP es asignar un identificador de 32 bits que sea único en el mundo a cada interfaz de cada host (o enrutador) en Internet (debido a que la dirección IP es de 32 bits, usará puntos por escrito Descrito en decimal ). La estructura de la dirección IP nos permite abordar fácilmente en Internet. Debe solicitar al ISP para utilizar la IP pública.
Clasificación de direcciones IP
El método de direccionamiento de las direcciones IP ha pasado por tres etapas históricas.
Dirección IP clasificada
Inicialmente, se consideró que las diversas redes son muy diferentes, y algunas redes tienen muchos hosts, mientras que otras tienen pocos hosts, por lo que las direcciones IP se dividen en categorías A, B y C para satisfacer mejor a los diferentes usuarios. Requerimientos
La dirección IP clasificada es dividir la dirección IP en varias categorías fijas (A, B, C, D, E cinco categorías), cada categoría se compone de dos campos de longitud fija, a saber, el número de red y el número de host. El número de red indica la red a la que está conectado el host, y el número de host indica el host (también único) en la red.
La clasificación es la siguiente, donde ABC es unidifusión, D es multidifusión y las direcciones de clase E están reservadas para uso futuro. Todos los 0
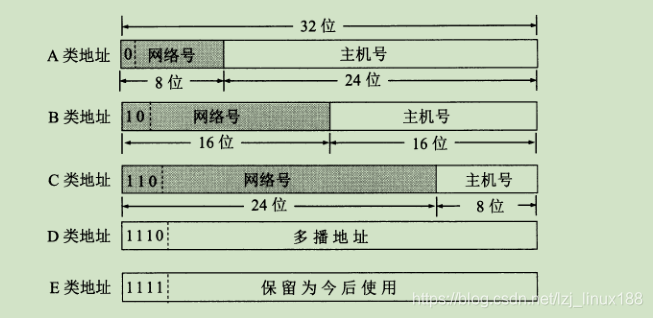
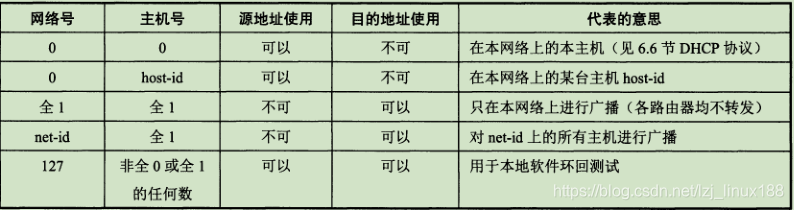
en la dirección IP significa "esto", y una dirección IP con un campo de número de red de todos los 0 es una dirección reservada, que significa "esta red" . El número de red 127 está reservado para pruebas de bucle invertido de software local. Si el número de host es todos 0, se refiere a la dirección de red , y todos los 1 significan todos, es decir, la dirección de difusión.
Las direcciones de clase A no están asignadas 127, las redes IP de clase B 128.0.0.0 no están asignadas, las redes IP de clase C 192.0.0.0 no están asignadas y las direcciones especiales en la red se muestran en la siguiente tabla:
las direcciones IP usan una estructura de dirección jerárquica para facilitar la IP Administración de direcciones (la razón es que la organización de administración solo asigna números de red, y el número de host es administrado internamente por la compañía), el mismo enrutador solo reenvía paquetes basados en el número de red del host de destino, lo que reduce el espacio de almacenamiento ocupado por la tabla de enrutamiento y El tiempo para encontrar la tabla de enrutamiento.Utilice números de red para identificar diferentes redes. Una red se refiere a una colección de hosts con el mismo número de red net-id. Varias LAN conectadas por repetidores y puentes siguen siendo una red, y las LAN con diferentes números de red deben interconectarse mediante enrutadores. La siguiente figura es Internet donde tres LAN están conectadas por enrutadores.

Subredes
La tasa de utilización de las direcciones IP en la clasificación de estructura de dos niveles mencionada anteriormente es a veces muy baja . Por ejemplo, el número de hosts que se pueden conectar a una red de direcciones de clase A supera los 10 millones. ¿Cuál es este concepto? Cuántas empresas tienen esa escala, la red de tipo B también se puede asignar a 60,000 números de host, y el tipo C tiene más de 200, muchas empresas han solicitado el tipo B pero no se han utilizado tanto; asigne una a cada red física El número de red hará que la tabla de enrutamiento sea demasiado grande y afectará el rendimiento de la red; la dirección IP de dos niveles no es lo suficientemente flexible; debido a que la dirección IP clasificada tiene los defectos mencionados anteriormente, se propone una solución de la dirección IP de dos niveles a la dirección IP de tercer nivel, a saber Agregue un campo de número de subred a la dirección IP para convertir la dirección IP de dos niveles en una dirección IP de tercer nivel. Esto es direccionamiento de subred o enrutamiento de subred .
La idea básica de dividir una subred es: tomar prestados unos pocos dígitos del número de host de la red como número de subred para dividir la red física en varias subredes . La división de subred es puramente una cuestión interna de la unidad, y la red fuera de la unidad no puede ver esta red. por el número de subredes, por lo que el exterior sigue siendo el rendimiento de una red . El datagrama IP enviado por una red externa a un host en esta red todavía tiene que encontrar el enrutador conectado a la red de la unidad de acuerdo con el número de red de destino del datagrama IP. El enrutador luego encuentra la subred de destino de acuerdo con el número de red de destino y el número de subred, entregando así los datos.La división en subredes solo subdivide el número de host de la dirección IP sin cambiar el número de red original de la dirección IP. La división en subredes es un asunto dentro de la unidad. Solo los enrutadores conectados a ella sabrán cómo dividir la subred dentro de la red. Hay varias subredes dentro..
Una vez que los datos en la red llegan al enrutador conectado a esta red, ¿cómo entrega los datos con precisión a una de las muchas subredes? Dado que ni la IP ni los encabezados de paquete tienen un campo sobre subredes, debe distinguirse por otra cosa. Esta es la máscara de subred . Después de que el enrutador recibe los datos de la red externa, puede obtener la dirección de red realizando la operación de la IP de destino y la máscara de subred, para saber a qué subred enviar los datos, y el enrutador tiene La dirección de red y la máscara de subred de todas las subredes conectadas. Si la red no divide la subred, el código fuente de la subred usa la máscara predeterminada (es decir, 1 con el mismo número de dígitos que el número de red) .
Reenvío de paquetes al usar subredes
Una vez que se utiliza la división en subredes, la tabla de enrutamiento debe contener la dirección de red de destino, la máscara de subred y la dirección del siguiente salto .
- Extraiga la dirección IP de destino D del encabezado del datagrama recibido .
- Primero determine si es entrega directa y verifique las redes conectadas directamente al enrutador una por una: use la máscara de subred de cada red y D una por una para ver si el resultado coincide con la dirección de red correspondiente. Si coinciden, el paquete se entrega directamente y la tarea de reenvío finaliza. De lo contrario, es entrega indirecta.
- Si hay una ruta de host específica con la dirección de destino D en la tabla de enrutamiento, el datagrama se transmite al enrutador del siguiente salto especificado en la tabla de enrutamiento; de lo contrario, se realiza el siguiente paso
- Haga coincidir cada fila en la tabla de enrutamiento para ver si la dirección de red de destino coincide. Si coincide, envíe el datagrama al enrutador del siguiente salto especificado por la fila; de lo contrario, realice el siguiente paso
- Si hay una ruta predeterminada en la tabla de enrutamiento, envíe el datagrama al enrutador predeterminado especificado en la tabla de enrutamiento; de lo contrario, vaya al siguiente paso
- Informe de error al reenviar paquetes.
Constituir una superred (sin direccionamiento de clasificación)
Particionar subredes ha aliviado las dificultades encontradas por Internet en el desarrollo, pero todavía hay muchos problemas que no se han solucionado. Si la entrada de la tabla de enrutamiento es demasiado grande, todavía se desperdicia el uso de la dirección IP, por lo que se propone un esquema de direccionamiento no clasificado.
El método de direccionamiento no clasificado se desarrolla en la máscara de subred de longitud variable VLSM. El nombre oficial es el CIDR de enrutamiento entre dominios no clasificado . Su característica principal es la eliminación de los tipos tradicionales de direcciones A, B y C y la división de subredes. El concepto de puede asignar más efectivamente el espacio de direcciones IP . CIDR divide la dirección IP en dos partes: prefijo de red y número de host, y luego vuelve al direccionamiento de dos niveles. CIDR forma un bloque de direcciones CIDR a partir de direcciones IP consecutivas con el mismo prefijo de red . Siempre que conozcamos cualquier dirección en el bloque de direcciones CIDR, podemos conocer la dirección inicial y la dirección máxima de este bloque de direcciones, y el número de direcciones en el bloque de direcciones. El algoritmo específico es que el número de host es todo 0 es la dirección IP más pequeña, y el número de host es todo 1 es la dirección IP más grande. Al mismo tiempo, el CIDR también usa la notación de barra diagonal, agregando una barra diagonal "/" después de la dirección IP, seguido del número de bits ocupados por el prefijo de red .Tenga en cuenta que CIDR no utiliza subredes, lo que significa que CIDR no especifica varios bits en la dirección de 32 bits como campos de subred, pero la unidad asignada a un bloque de direcciones CIDR aún puede dividir algunas subredes según las necesidades de esta unidad. Estas subredes también tienen solo un campo de red primero y un número de host.
Usando el bloque de dirección CIDR, el bloque de dirección CIDR se utiliza en la tabla de enrutamiento para encontrar la red de destino. Este tipo de agregación de direcciones a menudo se denomina agregación de ruta . Permite que un elemento en la tabla de enrutamiento represente muchas rutas de la dirección de clasificación tradicional original. La tabla de enrutamiento Por lo tanto, el número de proyectos en esta categoría se puede reducir mucho. La agregación de ruta también se conoce como la formación de una superred.
Cuando se usa CIDR, debido a la notación de prefijo de red, la dirección IP se compone de dos partes: prefijo de red y número de host, por lo que las entradas en la tabla de enrutamiento también deben cambiarse en consecuencia. En este momento, cada elemento consta del prefijo de red y el siguiente salto. Sin embargo, se puede obtener más de un resultado coincidente al buscar la tabla de enrutamiento, por lo que la ruta con el prefijo de red más largo debe seleccionarse de los resultados coincidentes . Use pistas binarias cuando busque rutas en la tabla de enrutamiento. Los lectores interesados en un uso específico pueden descargarlo en Baidu.
Proceso de transmisión de paquetes de datos en la red
La transmisión de paquetes de datos en la red es reenviada por la red como una unidad. El propósito de esto es simplificar los elementos de la tabla de enrutamiento en el enrutador (si se reenvía de acuerdo con la IP del host, las entradas en la tabla de enrutamiento serán muy grandes) Después de recibir el paquete, el enrutador primero busca la tabla de enrutamiento para ver si se puede entregar directamente a la red conectada al enrutador, si se puede entregar directamente; de lo contrario, se reenvía a otro enrutador, porque el enrutador y el enrutador están conectados a la misma red Reenviar paquetes a otros enrutadores es muy fácil y realista (solo necesita el protocolo ARP para lograrlo).El reenvío del paquete se basa en la dirección de red de destino para determinar el próximo salto. El datagrama IP eventualmente encontrará el enrutador en la red de destino donde se encuentra el host de destino (puede requerir entrega indirecta múltiple). Solo cuando llega al último enrutador, intenta Entrega directa al host de destino.
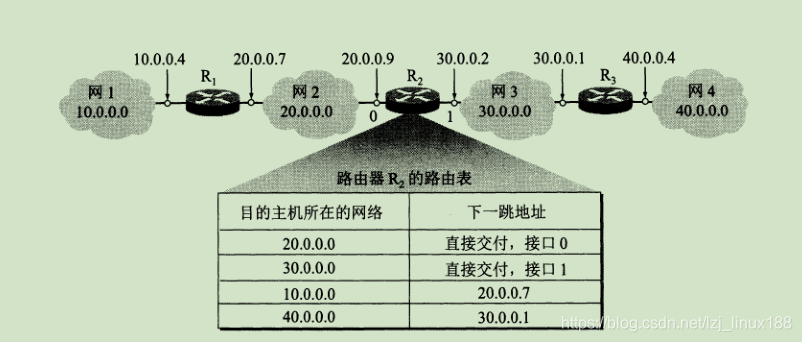
Aunque Internet realiza el reenvío de paquetes en función de la red donde se encuentra el host de destino, los administradores de red pueden controlar más fácilmente la red y probar las consideraciones de red y seguridad, por lo que también puede especificar una ruta para el host de destino, es decir, una ruta de host específica .
El enrutador también puede usar la ruta predeterminada para reducir el espacio ocupado por la tabla de enrutamiento y el tiempo que lleva buscar la tabla de enrutamiento. Este método de reenvío es muy útil cuando una red tiene pocas conexiones externas. La ruta predeterminada a menudo muestra sus beneficios cuando el host envía datagramas IP. El host debe buscar su propia tabla de enrutamiento cuando envía cada datagrama IP. Si un host está conectado a una red pequeña, y esta red usa solo uno Enrutador y conexión a Internet, entonces en este caso es muy apropiado usar la ruta predeterminada. Como se muestra en la figura a continuación, cualquier host en la red N1 solo necesita tres elementos: el host de destino conectado a N1 se puede entregar directamente y el host de destino se reenvía a R2 en N2, de lo contrario se entregará a R1. En la tabla del enrutador real, los caracteres "otros" y "directos" no aparecen, pero se registran como 0.0.0.0 ( esta red ) el

algoritmo de reenvío de paquetes del enrutador es el siguiente:
- Extraído de la dirección IP del anfitrión de destino de la parte de cabecera de datagrama D , la dirección de red de destino obtuvo N .
- Si N es una dirección de red conectada directamente a este enrutador, la entrega directa se realiza sin pasar a través de otros enrutadores; de lo contrario, es una entrega indirecta y se realiza el siguiente paso.
- Si hay una ruta de host específica cuya dirección de destino es D en la tabla de enrutamiento, el datagrama se transmite al enrutador del siguiente salto especificado en la tabla de enrutamiento; de lo contrario, se realiza el siguiente paso.
- Si hay una ruta a la red N en la tabla de enrutamiento , el datagrama se transmite al enrutador del siguiente salto especificado en la tabla de enrutamiento; de lo contrario, se realiza el siguiente paso.
- Si hay una ruta predeterminada en la tabla de enrutamiento, el datagrama se transmite al enrutador predeterminado indicado en la tabla de enrutamiento; de lo contrario, se realiza el siguiente paso.
- Informe de error al reenviar paquetes.
Una cosa a tener en cuenta es que no hay lugar en el encabezado del datagrama IP que pueda usarse para indicar "la dirección IP del enrutador del siguiente salto". En el encabezado del datagrama IP, solo se escriben las direcciones IP de origen y de destino, y no hay ninguna dirección intermedia La dirección IP del enrutador que pasa. Entonces, ¿cómo puede el datagrama que se reenvía encontrar el enrutador del siguiente salto?Después de recibir un datagrama para reenviarlo, el enrutador busca la ruta en la tabla de enrutamiento y obtiene la dirección IP del enrutador del siguiente salto. Luego reenvíelo al enrutador correspondiente. De manera similar, la tabla de enrutamiento no indica la ruta completa del paquete dado a una red. La tabla de enrutamiento solo indica que cuando se llega a una red, primero debe ir a un enrutador y luego continuar buscando la tabla de enrutamiento después de llegar al enrutador del siguiente salto. Mire hacia abajo hasta que finalmente llegue a la red de destino.
Protocolo ARP
En el estudio anterior, aprendí que la capa IP y superiores usan direcciones IP, y la capa de enlace de datos usa direcciones de hardware (es decir, direcciones MAC), como se muestra

en la siguiente figura: Al enviar datos, los datos van de la capa superior a la capa inferior. Luego se transmite en el enlace de comunicación. Una vez que el datagrama que usa la dirección IP se entrega a la capa de enlace de datos, se encapsula en una trama MAC. Las direcciones de origen y destino utilizadas en la transmisión de la trama MAC son ambas direcciones de hardware. Después de que el dispositivo recibe la trama correcta, solo después de quitar el encabezado y la cola de la trama MAC a los datos de la capa MAC, la capa de red puede encontrar la dirección IP de origen y la IP de destino en el encabezado del datagrama IP Dirección
** En resumen, la dirección IP se coloca en el encabezado del datagrama IP y la dirección de hardware se coloca en el encabezado de la trama MAC. Cuando el datagrama IP se coloca en el marco MAC de la capa de enlace de datos, todo el datagrama IP se convierte en los datos del MAC, por lo que la dirección IP del datagrama no se puede ver en la capa de enlace de datos **。
Durante la transmisión del datagrama IP, la dirección IP de origen y la dirección IP de destino nunca cambiarán, pero la dirección MAC puede cambiar durante la transmisión, debido a que la dirección MAC es diferente cuando se transmite por diferentes enlaces. Por lo tanto, en la transmisión de datos, también necesitamos conocer la dirección MAC del dispositivo, y el formato de la dirección MAC y la dirección IP es inconsistente, y no se puede establecer una asignación simple. Entonces, ¿cómo obtener la dirección MAC del dispositivo durante la transmisión?
Para el problema anterior, el protocolo ARP se utiliza en la red para obtener la dirección MAC del dispositivo. Aquí, dado que el protocolo IP utiliza el protocolo ARP, el protocolo ARP generalmente se clasifica en la capa de red.

** El principio de funcionamiento de ARP: ** La capa de red utiliza una dirección IP, pero cuando se transmiten tramas de datos en el enlace de la red real, la dirección de hardware de la red se debe utilizar eventualmente. Por lo tanto, se requiere un caché ARP en el host para almacenar la tabla de mapeo de la dirección IP de cada dispositivo a la dirección de hardware. Cuando el dispositivo A quiere enviar un mensaje al dispositivo B, el flujo de trabajo ARP es el siguiente:
- Primero, verifique si la dirección IP del host B está en la caché ARP del dispositivo A. En caso afirmativo, use la dirección de hardware en la caché directamente. De lo contrario, vaya al siguiente paso
- El proceso ARP del dispositivo A difunde un paquete de solicitud ARP en la red de área local y envía su dirección IP, dirección MAC y dirección IP del dispositivo que se encuentra.
- Todos los hosts en la red de área local pueden recibir el paquete de solicitud ARP. Solo cuando la dirección IP en el host coincida con la dirección IP a consultar en el paquete de solicitud ARP, el dispositivo aceptará el paquete ARP y enviará una respuesta ARP al host A. Otros dispositivos no responden. Al mismo tiempo, el host B registrará la dirección IP y la dirección MAC del dispositivo A en la tabla de caché ARP.
- Después de recibir el paquete de respuesta ARP del host B, el host A también escribirá la asignación de la dirección IP del host B a la dirección de hardware en la caché ARP.
El caché ARP en el dispositivo sigue siendo muy útil. El uso del caché ARP puede reducir la cantidad de tráfico en la red (no es necesario que envíe una solicitud ARP cada vez que transmite un paquete de datos). Al mismo tiempo, ARP establece un tiempo de supervivencia para cada elemento de dirección mapeado almacenado en la memoria caché. Cualquier elemento que exceda el tiempo de supervivencia se elimina de la memoria caché (el propósito es considerar el reemplazo del adaptador de red en la red, y la dirección MAC debe actualizarse después de reemplazar el adaptador de red. )
ARP es resolver el problema de mapear las direcciones IP y las direcciones de hardware de hosts o enrutadores en la misma red de área local. Si no están en la misma red de área local, no se pueden resolver. En este caso, se necesita un enrutador para obtener la dirección MAC del host en la misma red de área local.
Puede comunicarse utilizando una dirección MAC. ¿Por qué necesita una dirección IP?
Como hay varias redes en todo el mundo, utilizan diferentes direcciones de hardware. Para permitir que estas redes heterogéneas se comuniquen entre sí, se debe realizar una traducción de direcciones de hardware muy compleja. Por lo tanto, usar el mismo direccionamiento IP para tratar este complejo problema, de modo que su comunicación sea tan simple y conveniente como conectarse a la misma red (protegiendo las diferencias de varios hardware heterogéneos).
Formato de datagrama IP
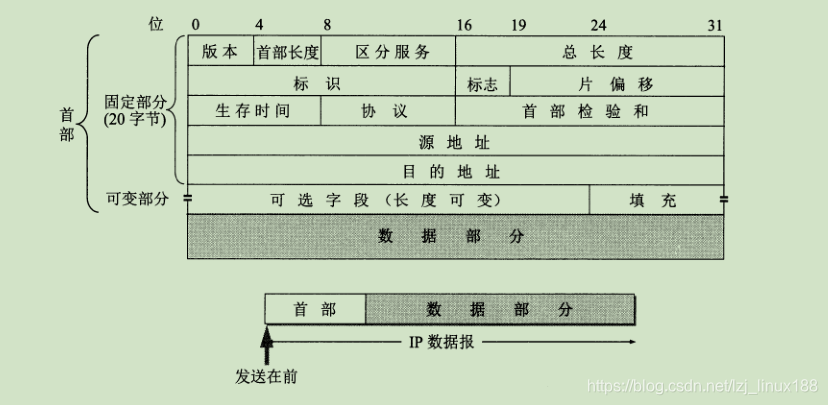
El formato del datagrama IP es el anterior, la siguiente es una breve introducción a cada campo.
- Versión: se refiere a la versión del protocolo IP, y el número de versión de IPv4 es 4
- Longitud del encabezado: se refiere a la longitud del encabezado IP, la unidad es una palabra de 32 bits. La longitud es entre 20 ~ 60 bytes.
- Servicios diferenciados: también conocidos como tipos de servicios, normalmente no se utilizan.
- Longitud total: la longitud de la suma del encabezado y los datos, en bytes. La longitud máxima del datagrama es 2 16 -1, o 65535 bytes.
- Identificación: el software IP mantiene un contador en la memoria. Cada vez que se genera un datagrama, el contador se incrementa en 1 y este valor se asigna al campo de identificación. Cuando la longitud del datagrama excede la MTU de la red y debe fragmentarse, el valor de este campo de identificación se copia en el campo de identificación de todos los fragmentos de datagrama. El valor del mismo campo de identificación permite que cada datagrama fragmentado se vuelva a ensamblar correctamente en el datagrama original .
- Indicador: el bit más bajo MF (más fragmento), MF = 1 significa que hay fragmentos de datagramas detrás; MF = 0 significa que este es el último
indicador de varios fragmentos de datagramas. El bit medio DF (no fragmentar) significa No es posible fragmentar, y la fragmentación solo se permite cuando DF = 0. - Desplazamiento de segmento: la posición relativa de un segmento en el paquete original después de la fragmentación de un paquete más largo. Relativo al punto de inicio del campo de usuario, donde comienza el segmento. La unidad es de 8 bytes
- Tiempo de vida: indica la vida útil del datagrama en la red. Este campo lo establece la fuente de los datos enviados. El enrutador disminuye el valor TTL en 1 antes de reenviar el datagrama. Si el valor TTL disminuye a cero, el datagrama se descarta , No más adelante
- Protocolo: el campo de protocolo indica qué protocolo se utiliza para los datos transportados en este datagrama.

- Suma de verificación de encabezado: este campo solo verifica el encabezado del datagrama, pero no incluye la porción de datos. Esto puede reducir la carga de trabajo de cálculo.
- Dirección de origen
- Dirección de destino
- La parte variable del encabezado del datagrama IP.
En el protocolo IP, existe la longitud total de los paquetes de datos IP, pero cada protocolo de capa de enlace de datos debajo de la capa IP especifica la longitud máxima (MTU) del campo de datos en un marco de datos. Cuando un datagrama IP se encapsula en Al vincular cuadros, la longitud total de este datagrama no debe exceder el valor de MTU. Si la longitud del datagrama transmitido excede el valor de MTU de la capa de enlace de datos, el datagrama excesivamente largo debe fragmentarse.
Protocolo de mensajes de control de Internet ICMP
ICMP permite a los hosts o enrutadores informar condiciones de error y proporcionar informes sobre condiciones anormales. El protocolo ICMP pertenece al protocolo de la capa IP. El mensaje ICMP se usa como los datos del datagrama de la capa IP, más el encabezado del datagrama, para formar un datagrama IP y enviarlo. El formato del mensaje es el siguiente: los
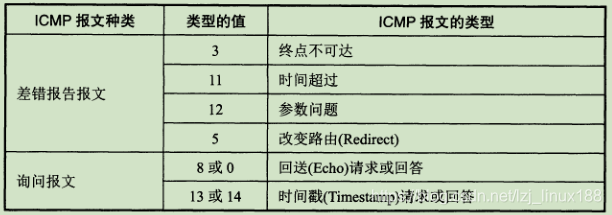
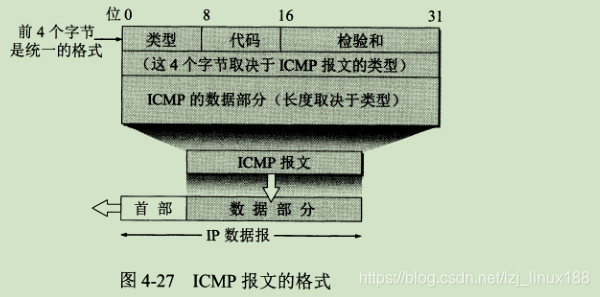 mensajes ICMP se dividen en mensajes de informe de errores ICMP y mensajes de consulta ICMP. El campo de código del mensaje ICMP es para distinguir aún más varias situaciones diferentes en un determinado tipo. El campo de suma de verificación se utiliza para verificar todo el mensaje ICMP. .
mensajes ICMP se dividen en mensajes de informe de errores ICMP y mensajes de consulta ICMP. El campo de código del mensaje ICMP es para distinguir aún más varias situaciones diferentes en un determinado tipo. El campo de suma de verificación se utiliza para verificar todo el mensaje ICMP. .
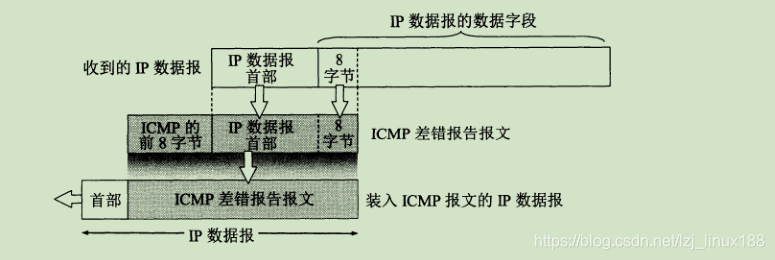
Los campos de datos en todos los mensajes de informe de error ICMP tienen el mismo formato : el encabezado del datagrama IP recibido para el informe de errores y los primeros 8 bytes del campo de datos se extraen como el campo de datos del mensaje ICMP . Los primeros 8 bytes del campo de datos del datagrama recibido se extraen para obtener el número de puerto de la capa de transporte y el número de secuencia de transmisión del mensaje de transporte. Esta información es útil para que el punto de origen notifique al protocolo de alto nivel.
Multidifusión IP
La multidifusión es la transmisión de datos de una fuente a muchos destinos, es decir, comunicación uno a muchos. La comunicación de multidifusión puede reducir la cantidad de tráfico de datos en la red. Por supuesto, la multidifusión también necesita usar la dirección IP de multidifusión para la comunicación.
Sabemos que cada host en Internet debe tener una dirección IP globalmente única. Entonces, ¿cómo puede el host recibir paquetes de un grupo de multidifusión en particular? Obviamente, la dirección de destino de este datagrama de multidifusión no debe escribirse en la dirección IP de este host. Esto se debe a que decenas de miles de hosts pueden unirse al mismo grupo de multidifusión al mismo tiempo. Los datagramas de multidifusión no pueden escribir tantas direcciones IP de host en sus encabezados. En la dirección de destino del datagrama de multidifusión, se escribe el identificador del grupo de multidifusión (es decir, la dirección de multidifusión), y luego la dirección IP del host que se une al grupo de multidifusión se administra para asociarse con el identificador del grupo de multidifusión.
El identificador del grupo de multidifusión es la dirección de clase D en la dirección IP. La asociación mencionada anteriormente se logra a través del Protocolo de gestión de grupos de Internet IGMP. Entonces, la diferencia entre un datagrama de multidifusión y un datagrama de IP general es que usa una dirección IP de Clase D como dirección de destino, y el valor del campo de protocolo en el encabezado es 2, lo que indica que se usa el IGMP del Protocolo de administración de grupos de Internet. Las direcciones de multidifusión solo se pueden usar para las direcciones de destino, no las direcciones de origen, y no se generan mensajes de error ICMP para los datagramas de multidifusión.
Multidifusión de hardware en LAN
El rango de direcciones de hardware de multidifusión es 01-00-5E-00-00-00 a 01-00-5E-7F-FF-FF. Dado que los 24 bits superiores de la dirección de hardware se utilizan como logotipos de la compañía, solo los 24 bits inferiores se pueden asignar libremente Además, el lugar 23 solo puede ser 0 (esto es por razones históricas, en ese momento solo compré 1 OUI y solo asigné la mitad para multidifusión. Todavía la pobreza limita la imaginación ^ _ ^), por lo que solo 23 Bit La correspondencia entre la dirección de hardware de multidifusión y la dirección IP de multidifusión es que los 23 bits inferiores de la dirección MAC utilizan los 23 bits inferiores de la dirección de multidifusión IP. Como se muestra a continuación, esta relación de mapeo no es única.

El alcance de uso local del protocolo IGMP: IGMP no es un protocolo para administrar todos los miembros del grupo de multidifusión en Internet. IGMP no sabe el número de miembros incluidos en un grupo de multidifusión IP, o en qué redes se distribuyen estos miembros, y así sucesivamente. El protocolo IGMP es para que el enrutador de multidifusión conectado a la LAN local sepa si un host en esta LAN se ha unido o ha dejado un grupo de multidifusión .
IGMP también utiliza datagramas IP para transmitir sus mensajes, es decir, los mensajes IGMP más los encabezados IP constituyen datagramas IP, por lo que IGMP también es un componente del Protocolo de Internet IP.
