Sabemos que HDFS se diseñó e implementó por primera vez en base al modelo conceptual de papel GFS (Sistema de archivos de Google).
Luego, fui a buscar el documento original de GFS y lo leí cuidadosamente. La arquitectura general de GFS es la siguiente:
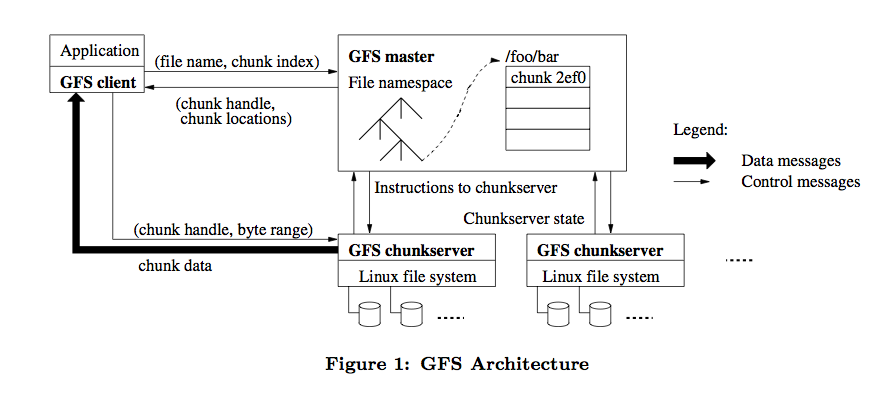
HDFS se refiere a él, por lo que la mayoría de los conceptos de diseño arquitectónico son similares, por ejemplo, HDFS NameNode es equivalente a GFS Master y HDFS DataNode es equivalente a GFS chunkserver.
Pero hay algunas diferencias en los detalles, por lo que este artículo analiza principalmente las diferencias.
Escribir modelo
HDFS hizo una simplificación al considerar el modelo de escritura, es decir, solo se permite un escritor o apéndice a la vez.
Bajo este modelo, solo un cliente puede escribir o agregar al mismo archivo al mismo tiempo.
GFS permite que varios clientes escriban o anexen el mismo archivo simultáneamente al mismo tiempo.
Permitir escrituras concurrentes trae problemas de consistencia más complicados.
Cuando varios clientes escriben simultáneamente, no se puede garantizar el orden entre ellos y se pueden interrumpir varios registros que el mismo cliente haya agregado con éxito.
Esto significa que cuando un cliente escribe datos de archivos continuamente, la distribución final de sus datos en el archivo puede ser discontinua.
La llamada consistencia es que para el mismo archivo, todos los datos que ve el cliente son consistentes, sin importar de qué copia se lean.
Si a varios clientes se les permite escribir un archivo al mismo tiempo, ¿cómo asegurarse de que los datos escritos sean consistentes entre varias copias?
Cuando hablamos de HDFS anteriormente, solo permitía que un escritor escribiera varias copias de manera canalizada. El orden de escritura es coherente y los datos seguirán siendo consistentes una vez completada la escritura.
Para varios clientes, es necesario permitir que todos los clientes que escriben al mismo tiempo escriban en el mismo modo de canalización para garantizar que el orden de escritura sea coherente.
Analizaremos este proceso de escritura en detalle en la siguiente sección.
Proceso de escritura
GFS utiliza un mecanismo de arrendamiento para garantizar la coherencia secuencial en la escritura de datos en varias copias.
El GFS Master emite el arrendamiento fragmentado a una de las copias. Llamamos a esta copia la copia primaria, y las otras copias se llaman copias secundarias.
La copia primaria determina un orden de escritura para el fragmento, y la copia secundaria se adhiere a este orden, asegurando así la consistencia global del pedido.
El diseño del mecanismo de arrendamiento de fragmentos es principalmente para reducir la carga sobre el maestro, y el servidor de fragmentos donde se encuentra la copia maestra es responsable de la disposición de la secuencia de la tubería.
Como se muestra a continuación, describimos este proceso en detalle.
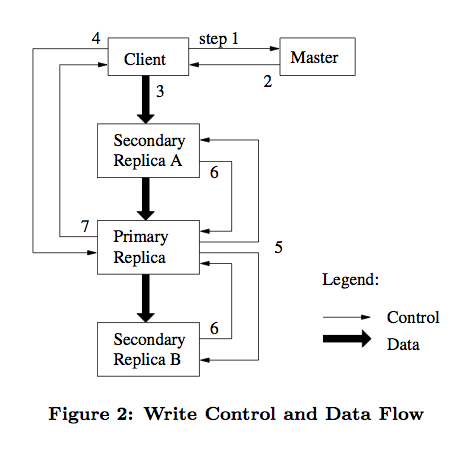
- El cliente le pide al Maestro que le pregunte qué servidor tiene el contrato de arrendamiento y la ubicación de otras copias.
Si ningún servidor chunks tiene un contrato de arrendamiento, indica que el fragmento no se ha escrito recientemente.
El Maestro eligió autorizar el arrendamiento a uno de los servidores en trozos. - Master devuelve la información de ubicación de las copias principales y secundarias del cliente.
El cliente almacena en caché esta información para uso futuro.
El cliente ya no necesita ponerse en contacto con el maestro, a menos que el servidor de fragmentos en el que se encuentra la copia maestra no esté disponible o el contrato de devolución caduque. - El cliente selecciona la secuencia de red óptima para enviar los datos, y el servidor de fragmentos almacena primero los datos en la caché interna de la LRU.
GFS adopta el método de separar el flujo de datos y el flujo de control, de modo que la transmisión del flujo de datos se pueda programar mejor en función de la topología de la red. - Una vez que todas las réplicas confirman que han recibido los datos, el cliente enviará un comando de control de solicitud de escritura a la réplica maestra.
La copia maestra asigna números de serie consecutivos para determinar el orden final de escritura. - La copia primaria reenvía las solicitudes de escritura a todas las copias secundarias, y las copias secundarias realizan operaciones de escritura en el orden en que se organiza la copia primaria.
- Después de escribir la copia secundaria, responda a la copia primaria para confirmar la finalización de la operación.
- Finalmente, la copia maestra responde al cliente. Si se produce algún error durante la escritura de cualquier copia, se informará al cliente, y el cliente iniciará un nuevo intento.
El proceso de escritura de GFS y HDFS adopta el método de canalización, pero HDFS no separa el flujo de datos y el flujo de control.
El orden de transmisión de la escritura de la canalización de datos HDFS en la red es coherente con el orden de la escritura final de los archivos.
El orden de transmisión de datos GFS en la red puede no ser el mismo que el orden en que finalmente se escriben los archivos.
GFS hace el mejor compromiso al admitir la escritura concurrente y optimizar la transmisión de datos de la red.
En primer lugar, una cosa para confirmar es que, como una de las implementaciones más importantes de GFS, los objetivos de diseño de HDFS y GFS son muy consistentes. En términos de arquitectura, tamaño de bloque, metadatos, etc., HDFS y GFS son más o menos lo mismo. Sin embargo, en algunos lugares, HDFS es diferente de GFS. Tales como: 1. Instantánea: la función de instantánea en GFS es muy poderosa, puede copiar archivos o directorios muy rápidamente y no afecta la operación actual (lectura / escritura / copia). El método de generar instantáneas en GFS se llama copia en escritura. En otras palabras, en algún momento, la copia de seguridad del archivo solo apunta el archivo de instantánea al fragmento original y aumenta el recuento de referencia del fragmento. Cuando se realiza la operación de escritura en el fragmento, el servidor de fragmento copiará el bloque de fragmento y la operación de modificación posterior caerá. En el trozo recién generado. HDFS no admite la función de instantánea temporalmente, pero utiliza la copia más básica para completar. Imagine que cuando los datos en HBase se están reparticionando (el proceso es similar al equilibrio de hash), HDFS necesita copiar y migrar todos los datos (nivel P / T), mientras que GFS solo necesita instantáneas, ¡lo cual es un inconveniente! 2. Registro de anexos (anexar): en términos de consistencia de datos, GFS es teóricamente más completo que HDFS. a) GFS proporciona un modelo de consistencia relativamente flexible. GFS admite operaciones de anexión de escritura y registro. La operación de escritura nos permite escribir archivos al azar. Las operaciones de adición de registros hacen que las operaciones paralelas sean más seguras y confiables b) HDFS tiene la misma función que GFS para el flujo de datos de la operación de escritura. Sin embargo, HDFS no admite operaciones de escritura de anexos y escritura paralela. NameNode usa el atributo INodeFileUnderConstruction para marcar el bloque de archivos que se está operando, independientemente de si se lee o se escribe. ¡DataNode ni siquiera ve el contrato de arrendamiento! Una vez que se crea, escribe y cierra un archivo, no hay necesidad de modificarlo. Un modelo tan simple es adecuado para la programación de Mapa / Reducir. 3. Reciclaje de basura(GC): a) La recolección de basura GFS adopta una estrategia de reciclaje inerte, es decir, el maestro no reciclará inmediatamente los recursos de archivos eliminados por el programa. GFS elige marcar los archivos eliminados en una forma específica (generalmente cambiando el nombre del archivo a un nombre oculto que contenga información de tiempo) para que los usuarios comunes ya no tengan acceso a dichos archivos. El maestro verificará periódicamente el espacio de nombres del archivo y eliminará los archivos ocultos hace algún tiempo (predeterminado 3 días). b) HDFS no utiliza dicho mecanismo de recolección de basura , pero adopta un método de eliminación directa más simple pero más fácil de implementar. c) Debe decirse que la recuperación retardada y la eliminación directa tienen sus propias ventajas. La recuperación retrasada deja el camino para esas operaciones de eliminación "accidentalmente". Al mismo tiempo, la operación específica de recuperación de recursos se completa cuando el nodo maestro está inactivo, lo que mejora el rendimiento de GFS. Pero la recolección retrasada ocupará mucho espacio de almacenamiento, ¿qué pasa si algunos usuarios desagradables están aburridos y han estado creando y eliminando archivos? Intenta analizar esta diferencia. Algunas personas dicen que GFS tiene una función muy completa y muy potente, mientras que HDFS es relativamente simple en estrategia, principalmente para facilitar la implementación. Pero, de hecho, GFS como plataforma de almacenamiento se ha implementado durante mucho tiempo en Google, almacenando datos generados o procesados por los servicios de Google, y también se utiliza para la investigación y el desarrollo de conjuntos de datos a gran escala. Por lo tanto, GFS no es solo un estudio teórico, sino una realización concreta. Como descendientes de GFS y la implementación de código abierto, HDFS debería ser más maduro en tecnología, y es imposible simplificar las funciones de "pereza". Por lo tanto, no se debe establecer la simplificación. Personalmente, creo que la diferencia entre GFS y HDFS se debe a la diferencia entre "especial" y "común". Como todos sabemos, Hadoop es un software / marco de código abierto. Al comienzo del diseño, tuvo en cuenta las diferencias en las necesidades de los usuarios (para todas las personas y empresas del mundo), como el uso intensivo de datos (como el almacenamiento de datos de Taobao ).), Computacionalmente intensivo (algoritmo de PR de Baidu), híbrido, etc. Al comienzo del diseño, GFS era relativamente claro acerca de los objetivos, todos los cuales eran de Google, por lo que GFS puede optimizar el rendimiento de sus funciones principales.