Directorio de artículos
-
- 1. Antecedentes
- 2. Método
-
- 2.1 Marco de aprendizaje contrastivo
- 2.2 Tamaño del lote utilizado para el entrenamiento
- 2.3 Método de mejora de datos
- 2.4 Los modelos más grandes son más propicios para el aprendizaje contrastivo no supervisado
- 2.5 El cabezal de mapeo no lineal puede brindar mejores resultados
- 2.6 Un tamaño de lote más grande y un tiempo de capacitación más prolongado son más propicios para el aprendizaje comparativo
- 2.7 Métodos de evaluación
- 3. Efecto
论文:Un marco simple para el aprendizaje contrastivo de representaciones visuales
Código: https://github.com/google-research/simclr
Fuente: ICML 2020 | Sr. Hinton | Google
contribuir:
- Demostrar que la combinación de diferentes aumentos de datos es importante
- Se introduce una estructura de transformador no lineal aprendible entre la expresión de características y la pérdida contrastiva, que ha logrado una gran mejora.
- Con la bendición de un gran tamaño de lote y una gran época, el aprendizaje comparativo puede lograr mejores resultados que el aprendizaje supervisado
Efecto:
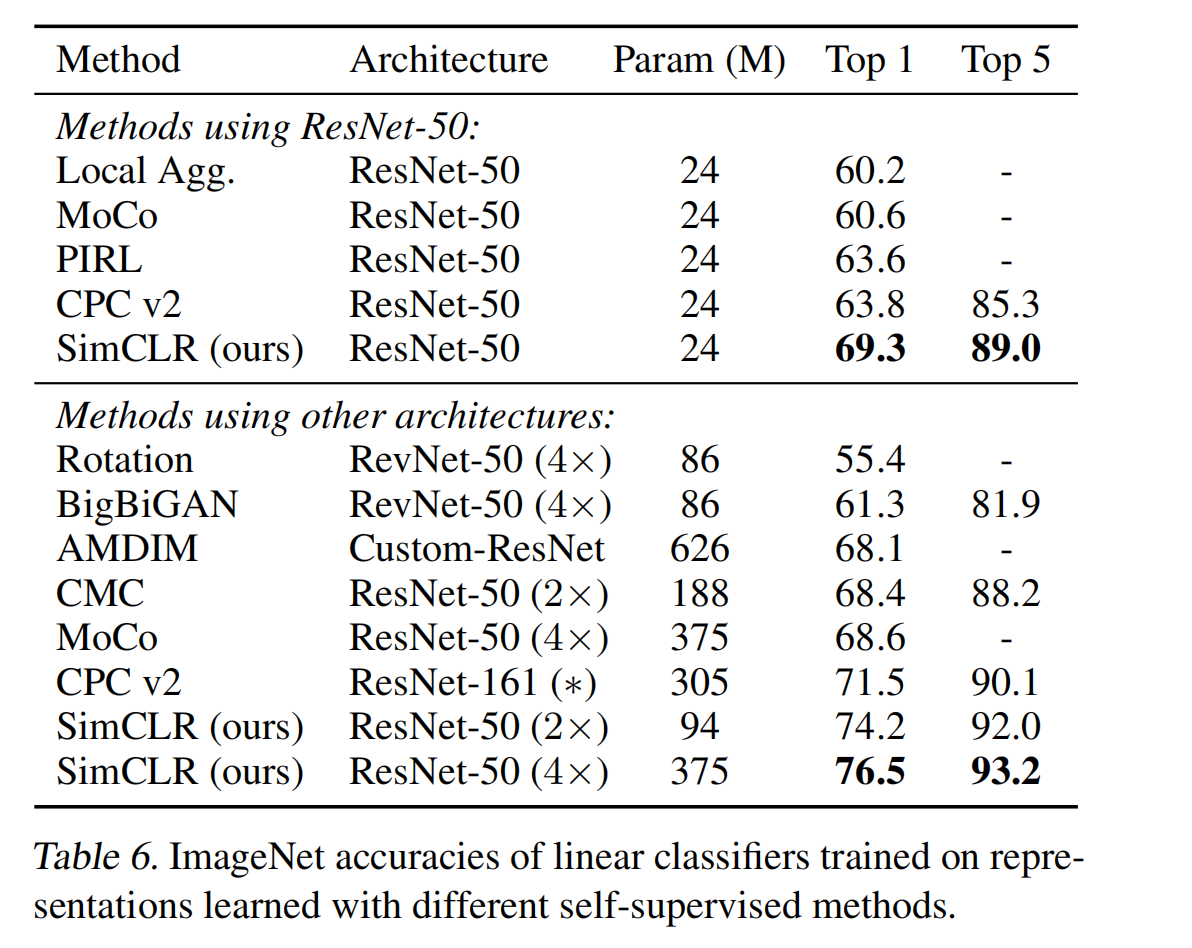
- Después de usar el aprendizaje contrastivo autosupervisado para entrenar ImageNet para extraer características, se entrenó un clasificador lineal para obtener un 76,5 % de top-1 acc, que era un 7 % más alto que el SOTA en ese momento, y logró el mismo efecto que la red de referencia supervisada ResNet50
1. Antecedentes
En la actualidad, existen aproximadamente dos rutas diferentes para la extracción de características visuales no etiquetadas, a saber, generativa y discriminativa, es decir, generativa y discriminativa.
- El método generativo consiste en aprender cómo generar los mismos píxeles que el espacio de entrada, pero la generación de nivel de píxel es computacionalmente intensiva y no tiene un significado fuerte de expresión de características.
- El método discriminante consiste en utilizar la función objetivo para juzgar si dos entradas provienen de los mismos datos. Generalmente, es necesario utilizar una tarea proxy para generar diferentes muestras para la misma entrada, por lo que si la tarea proxy no se usa bien, puede limitar el modelo generalizabilidad.
El método basado en discriminantes ha logrado el efecto de SOTA (como MOCO), por lo que el autor de este artículo ha realizado algunas exploraciones y experimentos para explorar las razones y ha demostrado las siguientes conclusiones:
- En la tarea de proxy, la combinación de diferentes métodos de mejora de datos puede obtener una mejor expresión de características, y el efecto de la mejora de datos para el aprendizaje contrastivo no supervisado es mayor que el del aprendizaje supervisado.
- El autor presenta un transformador no lineal aprendible entre la pérdida contrastiva de cálculo de la expresión de características, que puede mejorar en gran medida el efecto del modelo.
- La normalización de características es más propicia para el uso de métodos contrastivos de aprendizaje de entropía cruzada.
- El aprendizaje autosupervisado requiere un tamaño de lote más grande y un tiempo de capacitación más largo (en comparación con el aprendizaje supervisado)
El autor combinó formalmente los varios descubrimientos anteriores, por lo que construyó un marco de red simple SimCLR
2. Método
2.1 Marco de aprendizaje contrastivo

SimCLR se aprende maximizando la consistencia de diferentes vistas de la misma muestra en el espacio de características. La estructura de la red se muestra en la Figura 2
-
Primero, dada una muestra de entrada x, el autor utiliza el aumento de datos para generar dos imágenes, que son un par de pares positivos.
En este artículo, se utilizarán secuencialmente tres mejoras de datos: recorte aleatorio → cambio de tamaño al tamaño original → distorsión de color aleatoria → ruido gaussiano aleatorio. Porque el autor descubrió a través de experimentos que la combinación de recorte aleatorio y distorsión de color puede lograr los mejores resultados.
-
Luego, usando el codificador base f ( . ) f(.)f ( . ) para extraer las características de los datos, el codificador aquí es ResNet
-
A continuación, utilice el cabezal de proyección g ( . ) g(.) en las características resultantesg ( . ) para asignar características al espacio de pérdida contrastiva. dondeg ( . ) g (.)g ( . ) es un MLP con una capa oculta. dondeg ( . ) g (.)g ( . ) no es lineal porque se utiliza la función de activación de ReLU.
-
Finalmente, la tarea de predicción comparativa se realiza en las características finales, utilizando la pérdida de aprendizaje comparativa, es decir, dado un grupo de muestras transformadas, el modelo debe poder pasar el xi x_i dado .XyoIdentifique su correspondiente muestra positiva xj x_jXj
¿Cómo aprende específicamente el aprendizaje comparativo?
-
Primero, suponiendo que un lote ingresa N muestras, después de la tarea de proxy, se pueden obtener 2N muestras aumentadas
-
Entonces, usando f ( . ) f(.)f ( . ) yg ( . ) g(.)g ( . ) realiza la extracción de características correspondiente para obtenerzi z_izyo和zj z_jzj
-
A continuación, calcule la pérdida de aprendizaje contrastiva, para una muestra zi z_izyo, solo hay una muestra positiva zj z_jzj, todas las 2(N-1) muestras aumentadas restantes son muestras negativas, por lo que la función de pérdida correspondiente a la muestra i es la siguiente, el denominador es para excluir a i, sim significa multiplicación de puntos, τ \ tauτ representa el parámetro de temperatura

El proceso general de SimCLR:
¿Por qué es 2k-1 veces aquí, porque las dos muestras de agosto obtenidas por una muestra son muestras en el lote actual, por lo que cada muestra calculará la pérdida con todas las demás muestras, i y j se calcularán una vez, y j e i También se calcula una vez, por lo que cada muestra calculará la pérdida 2k-1 veces. Entonces el último L también se divide por 2, porque cada muestra se calcula 2 veces.

2.2 Tamaño del lote utilizado para el entrenamiento
Sabemos que el aprendizaje contrastivo depende más del número de muestras negativas, y solo cuando el número de muestras negativas es grande podemos aprender más características discriminatorias.
Entonces, el autor usó un tamaño de lote de 256 a 8192. Cuando el tamaño del lote es 8192, la cantidad de muestras negativas correspondientes a cada muestra es 16382 (16382 = 2x (8192-1))
Si usa un tamaño de lote tan grande y usa el optimizador SGD/Momentum combinado con cambios de tasa de aprendizaje lineal, será inestable, por lo que el autor usó el optimizador LARS.
BN global: los datos de todas las máquinas calculan la media y la varianza de BN juntas
En el entrenamiento distribuido, la media y la varianza de BN se obtienen calculando todas las muestras en una sola tarjeta. En el aprendizaje contrastivo, los pares positivos se obtienen en la misma máquina, lo que conducirá a la fuga de información. Se filtra al modelo que todos los pares de muestras positivos están en la diagonal. El modelo puede usar la información local filtrada para mejorar la tasa de precisión sin mejorando el resultado del aprendizaje.
Para evitar este problema, el autor utiliza todos los datos de todas las máquinas en una sola iteración para calcular la media y la varianza, lo que se resuelve mezclando los datos en MOCO.
2.3 Método de mejora de datos

La Figura 4 muestra diferentes métodos de mejora de datos. El autor también combinó diferentes métodos de mejora de datos y finalmente descubrió que la combinación de recorte aleatorio y color puede obtener los mejores resultados.
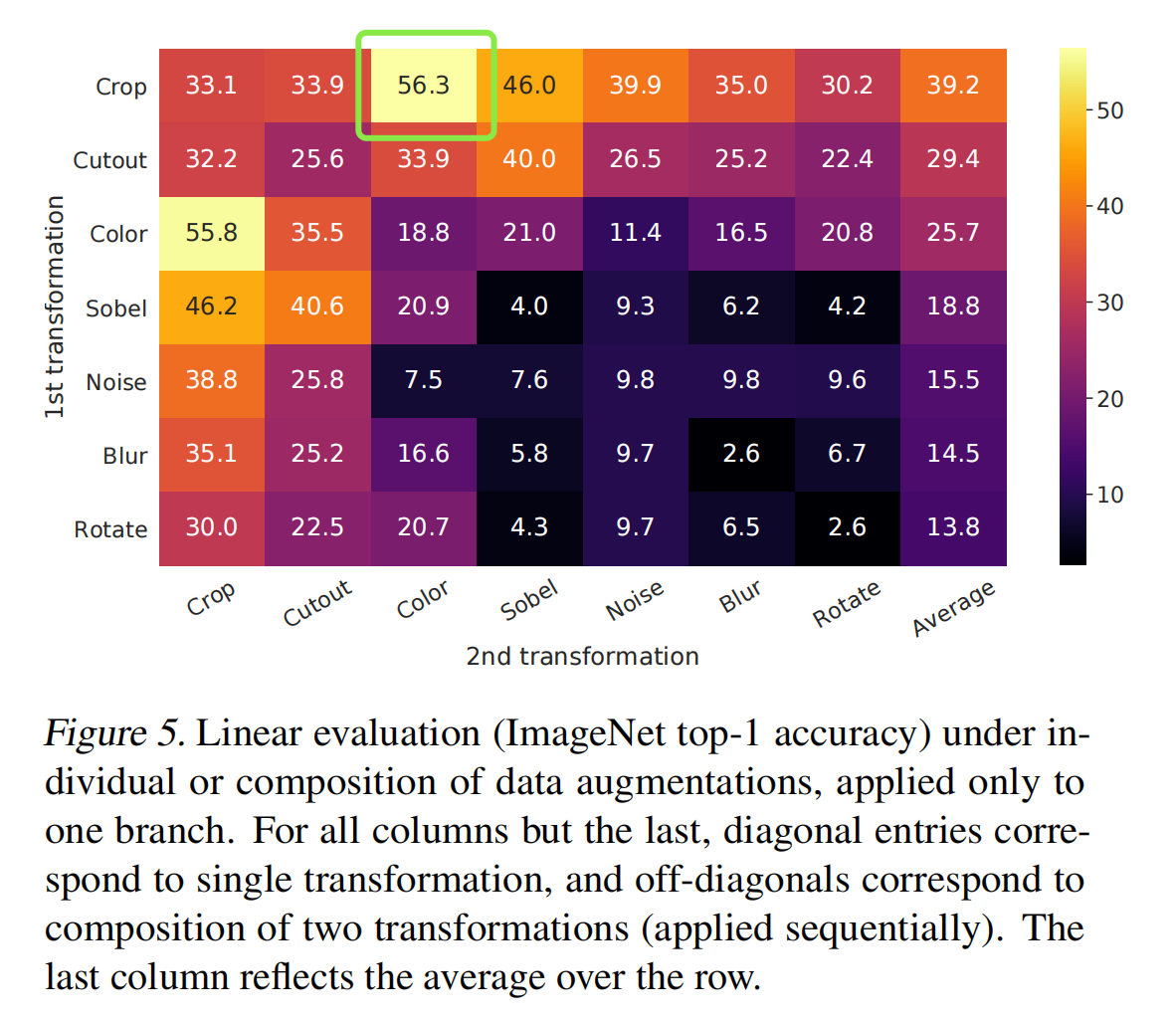
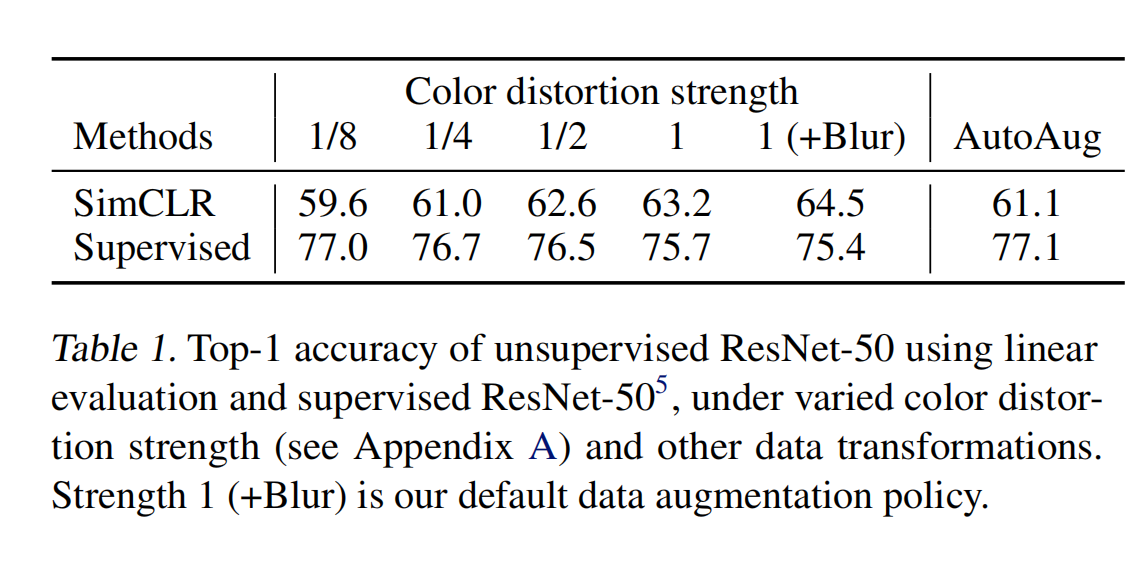
Y el autor demostró que el aumento fuerte es más importante en el aprendizaje no supervisado
2.4 Los modelos más grandes son más propicios para el aprendizaje contrastivo no supervisado

2.5 El cabezal de mapeo no lineal puede brindar mejores resultados

2.6 Un tamaño de lote más grande y un tiempo de capacitación más prolongado son más propicios para el aprendizaje comparativo

2.7 Métodos de evaluación
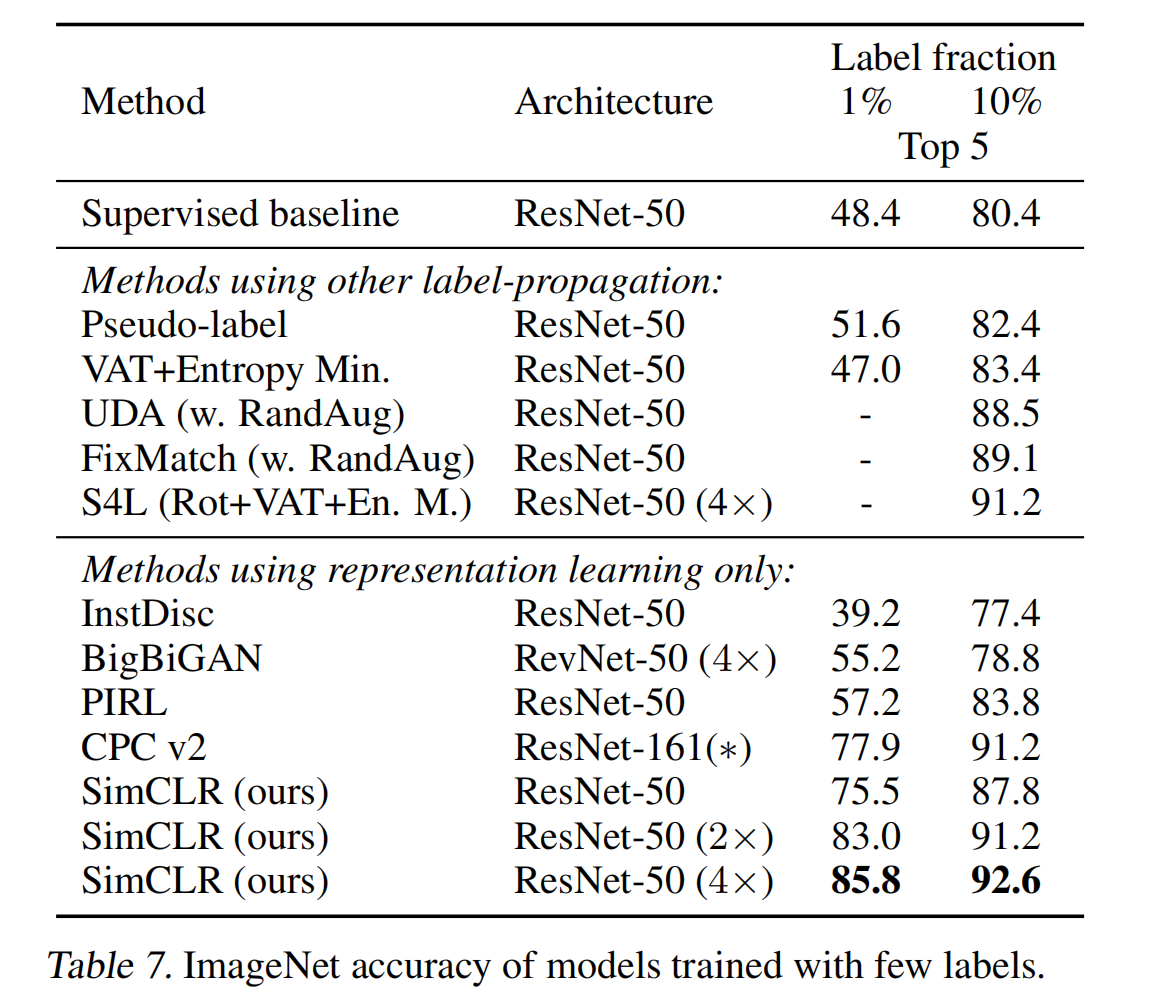
Muchas evaluaciones anteriores de métodos no supervisados y de aldea están en ImageNet, y algunas están en cifar-10.
En este artículo, el autor también utilizará el aprendizaje por transferencia para evaluar el efecto del modelo de pre-entrenamiento
El método utilizado por el autor para la evaluación es el protocolo lineal (es decir, congelar la columna vertebral de preentrenamiento y entrenar solo el último cabezal de clasificación agregado)
configuración:
- codificador base: R50
- cabezal de proyección (mapeo de salida a características de 128 d): MLP de 2 capas
- pérdida: NT-Xent, usando LARS, la tasa de aprendizaje es 4.8 y la caída de peso es 10 ^ -6
- tamaño del lote: 4096
- época: 100
3. Efecto