1) El proceso de agrupación k-means de juego manual de naipes:> 30 cartas, 3 tipos
Por primera vez, seleccione al azar tres centros de grupos K, 7, 6 y luego seleccione al azar 30 grupos para clasificar

Calcule el valor promedio, el valor promedio de las tres pilas de tarjetas es de aproximadamente 12,7,4, y luego vuelva a clasificar las tarjetas nuevamente, de acuerdo con la clasificación de distancia más pequeña

Calcule el promedio nuevamente, el valor promedio de las tres pilas de cartas es aproximadamente 12, 7, 3, y luego vuelva a clasificar las cartas

Finalmente, el valor promedio no cambia y finaliza la clasificación.
2). * El algoritmo K-means se escribe independientemente, la agrupación se realiza en los datos de longitud del pétalo del iris y se muestra con un diagrama de dispersión. (Puntos más)
3). Utilice sklearn.cluster.KMeans y datos de longitud de pétalo de iris para la agrupación y visualización con diagrama de dispersión.
sklearn.datasets de importación load_iris de sklearn.cluster importación KMeans importación matplotlib.pyplot PLT AS IRIS = load_iris () # adquirida del iris conjunto de datos iris.keys () X = iris.data [:, 0] # adquirido iris pétalos longitud los datos X = x.reshape (-1,1) # convertir los datos a un conjunto de datos # llamadas directas sklearn implementación de la biblioteca del iris de datos de agrupamiento km_model = KMeans (= n_clusters. 3) # construir un modelo dividido en tres categorías km_model. ajuste (la dirección X) # modelo de formación del Y-km_model.predict = (X-) # modelo de predicción de impresión ( " centro de la agrupación:"Km_model.cluster_centers_) Imprimir ( " resultado predicción: " , Y) # dibujo plt.scatter (X [:, 0], X [:, 0], Y = C, S = 50, = CMap ' Rainbow ' ) plt.show ()
Los resultados son los siguientes


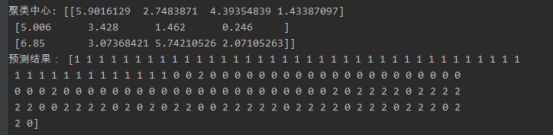
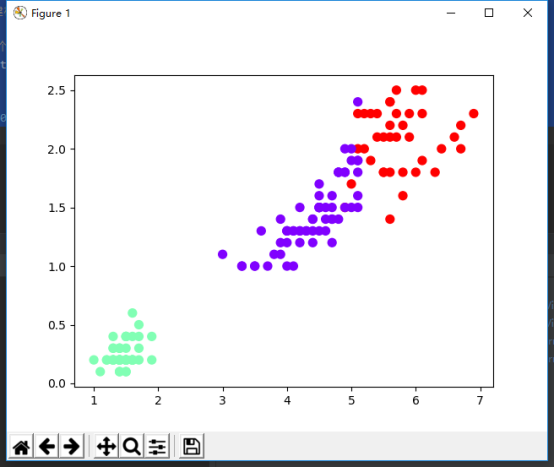
4). Los datos completos de las flores de iris se agrupan y se muestran con un diagrama de dispersión.
de sklearn.datasets importación load_iris de sklearn.cluster importación KMeans importación matplotlib.pyplot AS PLT IRIS = load_iris () # get iris conjunto de datos los X-iris.data = # Iris completos de datos # KMeans biblioteca llamada directa sklearn lograr Iris conjuntos de datos. km_model = KMeans (= n_clusters. 3) # modelos de construcción km_model.fit (X) # modelo de formación Y = km_model.predict (X) # modelo de pronóstico índice de agrupación para cada muestra de impresión ( " centro de la agrupación : " , km_model.cluster_centers_) print ( " Resultado de la predicción:" , y) # 画图 plt.scatter (x [:, 2], x [:, 3], c = y, s = 50, cmap = ' rainbow ' ) # x, y, c plt.show ()
El resultado es como se muestra
5) ¿Piensa en lo que se usa en el algoritmo k-means?