Ayer, clarifiqué más o menos la idea, utilizando una forma única para desempaquetar las palabras clave palabra por palabra, y probar la viabilidad hoy.
Los métodos actuales de vectorización de texto convencional incluyen principalmente one-hot, tf (frecuencia de término) y tf-idf (frecuencia de término-frecuencia de documento inversa).
Mis necesidades son relativamente simples, solo hay más de cien palabras clave relativamente cortas, así que primero use la vectorización de una sola vez, ejecute todo el proceso y luego regrese para probar la diferencia de precisión.
Para la segmentación de palabras, puede usar el paquete jieba de Python. Debido a que las palabras son relativamente cortas, no se dividen, y se dividen por palabras.
Se han eliminado más de cien palabras y hay más de 200 palabras clave, que también se sienten bien.
La verificación de la idea se realiza en Excel. Después de todo, la cantidad de datos es pequeña y parece conveniente.
El proceso es: primero use vba para dividir la palabra en palabras (también puede usar la fórmula de Excel para completar); use la función de diccionario vba para reproducir la palabra en la primera línea; luego use la fórmula countif para obtener la codificación única.
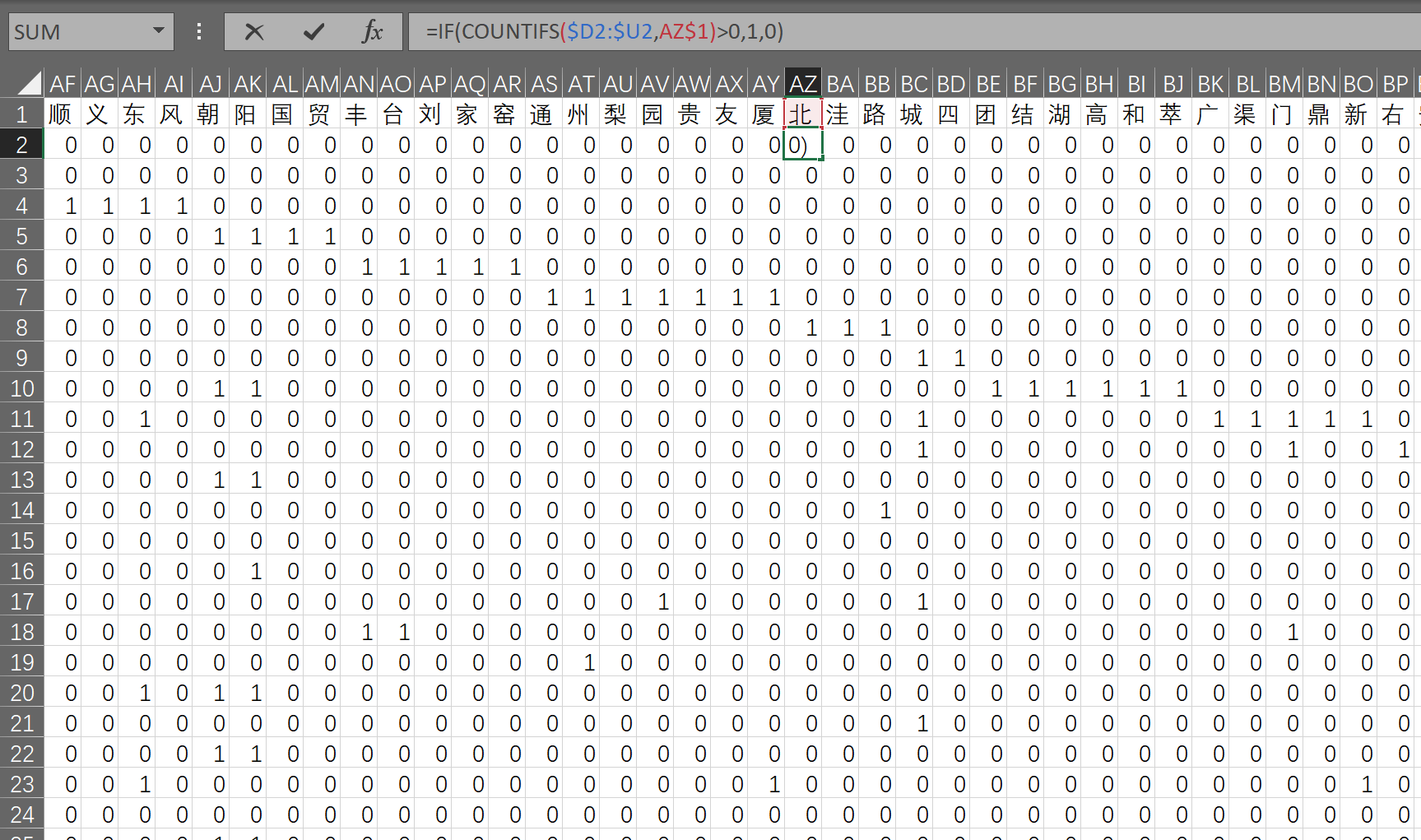
Después de encontrar la nueva palabra más tarde, se calcula la codificación de la nueva palabra y se puede calcular la similitud comparando los dos vectores.
La similitud de los vectores utiliza el método de similitud de coseno, que no se repite aquí. La explicación específica puede ser Baidu.
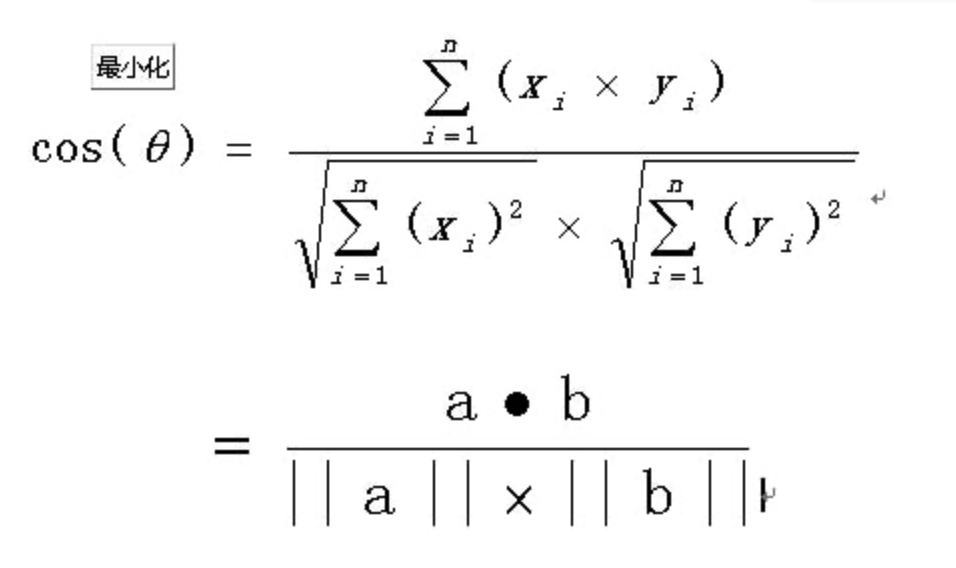
Encontré un código que usa numpy para calcular la similitud del coseno y lo probé.
import numpy as np
def cos_sim(vector_a, vector_b):
"""
计算两个向量之间的余弦相似度
:param vector_a: 向量 a
:param vector_b: 向量 b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
sim = num / denom
return sim
print( cos_sim(np.array([[1, 1, 1,1,1,1,1,1]]),np.array([[1, 2, 1,1,1,1,1,1]])) )
Calcula con éxito la similitud de estos dos vectores de prueba
En la actualidad, todo el proceso de cálculo se está ejecutando básicamente, el siguiente paso es usar C # para lograr las funciones anteriores.