Tarea 1: Ahora hay un artículo largo titulado "Apicultura de abejas en China". Utilice una computadora para extraer sus palabras clave.
1. Frecuencia de palabras: si una palabra es importante, debería aparecer varias veces en este artículo. Realizamos estadísticas de "frecuencia de término" (término de frecuencia, abreviado como TF).
2. Palabras vacías: como resultado, debe haberlo adivinado. Las palabras más utilizadas son ---- "的", "是", "在" ---- las palabras más utilizadas en esta categoría. Se denominan "palabras vacías" , que significan palabras que no son útiles para encontrar los resultados y deben filtrarse.
Regla 1: si una palabra es relativamente rara, pero aparece varias veces en este artículo, es probable que refleje las características de este artículo, que es exactamente la palabra clave que necesitamos.
Supongamos que los filtramos y solo consideramos las palabras significativas restantes
Descubrió que las tres palabras "China", "abeja" y "agricultura" aparecen tantas veces
Dado que "China" es una palabra muy común, en términos relativos, "abeja" y "cría" no son tan comunes, "abeja" y "cría" son más importantes que "China".
3. IDF: las palabras más comunes ("的", "是", "在") dan el menor peso,
Las palabras más comunes ("China") dan menos peso,
Las palabras menos comunes ("abeja", "agricultura") dan mayor peso.
Este peso se denomina "Frecuencia de documento inversa" (Frecuencia de documento inversa, abreviado como IDF),
Su tamaño es inversamente proporcional a lo común que es una palabra.
4. TF-IDF: Después de "frecuencia de término" (TF) y "frecuencia de documento inverso" (IDF), los dos valores se multiplican para obtener el valor TF-IDF de una palabra.
Cuanto mayor sea la importancia de una palabra para el artículo, mayor será su valor TF-IDF.
Por lo tanto, las primeras palabras son las palabras clave de este artículo.
Implementación:
1. Calcular la frecuencia de las palabras
Frecuencia de término (TF) = la cantidad de veces que aparece una palabra en el artículo
Los artículos se dividen en largos y cortos, para facilitar la comparación de los diferentes artículos, se estandariza la "frecuencia de palabras".
Frecuencia de palabras (TF) = número de apariciones de una palabra en el artículo / número total de palabras en el artículo
O frecuencia de palabras (TF) = la cantidad de veces que aparece una palabra en el artículo / la cantidad de palabras con la mayor frecuencia de palabras
2. El número de apariciones de una palabra en el artículo.
En este momento, se necesita un corpus para simular el entorno del lenguaje.
Frecuencia inversa de documentos (IDF) = log (número total de documentos en el corpus / número total de documentos que contienen la palabra + 1)
3. Calcular TF-IDF
TF-IDF = frecuencia de término (TF) * frecuencia de documento inversa (IDF)
Puede verse que TF-IDF es directamente proporcional al número de apariciones de una palabra en el documento, e inversamente proporcional al número de apariciones de la palabra en todo el idioma.
Por lo tanto, el algoritmo para extraer automáticamente las palabras clave es calcular el valor TF-IDF de cada palabra en el documento.
Luego, ordénelas en orden descendente, tomando las primeras palabras.
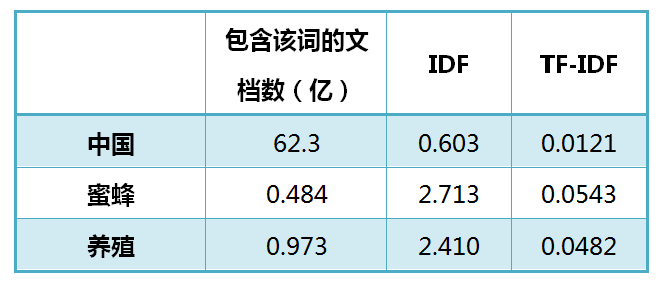
Puede verse en la tabla anterior que "abeja" tiene el valor de TF-IDF más alto, "agricultura" es el segundo y "China" es el más bajo. (Si también se calcula el TF-IDF de la palabra "的", será un valor muy cercano a 0.)
Entonces, si elige solo una palabra, "abeja" es la palabra clave de este artículo.
para resumir:
La ventaja del algoritmo TF-IDF es que es simple y rápido, y el resultado es más acorde con la situación real.
La desventaja es que simplemente medir la importancia de una palabra por "frecuencia de palabras" no es lo suficientemente completo, y algunas veces las palabras importantes pueden no aparecer muchas veces.
Además, este algoritmo no puede reflejar la información de posición de las palabras. Las palabras que aparecen en la posición delantera y las palabras que aparecen detrás de la posición se consideran ambas de la misma importancia, lo cual es incorrecto.
(Una solución es dar más peso al primer párrafo del texto completo y a la primera oración de cada párrafo).
Tarea 2: TF-IDF y aplicaciones similares con coseno: busque artículos similares
Además de buscar palabras clave, también espero encontrar otros artículos similares al artículo original.
Necesita usar similitud de coseno:
Oración A: me gusta ver televisión, no películas
Oración B: no me gusta ver televisión o películas
La idea básica es: si las palabras utilizadas en estas dos oraciones son más similares, su contenido debería ser más similar.
Por tanto, podemos partir de la frecuencia de palabras y calcular su similitud.
1. Segmentación de palabras
Oración A: Me / me gusta / ver / TV, no / me gusta / ver / películas.
Oración B: No / no / me gusta / ver / TV, ni / no / me gusta / ver / películas.
2. Enumere todos los valores
Me gusta, mirar, TV, películas, no, también.
3. Calcula la frecuencia de las palabras
Oración A: I 1, como 2, ver 2, TV 1, película 1, no 1, también 0.
Oración B: I 1, como 2, ver 2, TV 1, película 1, no 2, también 1
4. Escribe el vector de frecuencia de palabras.
Oración A: [1, 2, 2, 1, 1, 1, 0]
Oración B: [1, 2, 2, 1, 1, 2, 1]
Podemos juzgar la similitud de los vectores por el tamaño del ángulo incluido. Cuanto menor sea el ángulo, más similar.
Suponiendo que el vector a es [x1, y1] y el vector b es [x2, y2], la ley de los cosenos puede reescribirse en la siguiente forma
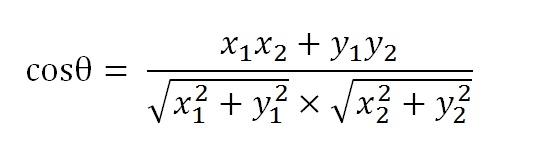
En conclusión:
Obtenemos un algoritmo para "encontrar artículos similares":
- Utilice el algoritmo TF-IDF para encontrar las palabras clave de dos artículos
- Saque varias palabras clave (como 20) para cada artículo, combínelas en un conjunto y calcule la frecuencia de palabras de cada artículo para las palabras de este conjunto (para evitar diferencias en la longitud del artículo, puede utilizar la frecuencia relativa de palabras) ;
- Genere los respectivos vectores de frecuencia de palabras para dos artículos
- Calcule la similitud de coseno de dos vectores, cuanto mayor sea el valor, más similar
Calcule la similitud de coseno de dos vectores, cuanto mayor sea el valor, más similar
Tarea 3: Cómo usar la frecuencia de palabras para resumir artículos automáticamente
La información está contenida en oraciones, algunas oraciones contienen más información y algunas oraciones contienen menos información.
El "resumen automático" consiste en encontrar las frases que contienen más información.
La cantidad de información en una oración se mide por "palabras clave". Si incluye más palabras clave, significa que la oración es más importante.
Luhn propuso utilizar "clúster" para representar la agregación de palabras clave. El llamado "grupo" es un fragmento de oración que contiene varias palabras clave.
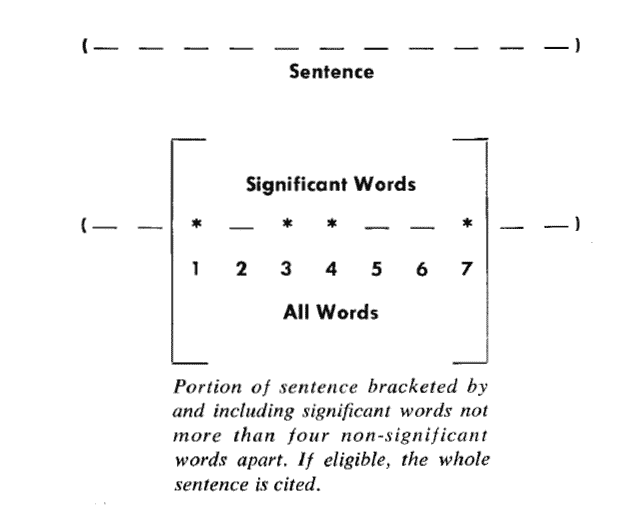
Siempre que la distancia entre las palabras clave sea menor que el "umbral", se considera que están en el mismo grupo. El umbral sugerido por Luhn es 4 o 5.
En otras palabras, si hay más de 5 otras palabras entre dos palabras clave, estas dos palabras clave se pueden dividir en dos grupos.
Importancia del conglomerado = (número de palabras clave incluidas) ^ 2 / longitud del conglomerado
Hay 7 palabras en el grupo, 4 de las cuales son palabras clave. Por tanto, su puntuación de importancia es igual a (4 x 4) / 7 = 2,3.
Luego, busque las oraciones que contengan el grupo con la puntuación más alta (por ejemplo, 5 oraciones) y júntelas para formar el resumen automático de este artículo.


1 Summarizer (originalText, maxSummarySize):
2 // Calcula la frecuencia de palabras del texto original y genera una matriz, como [(10, 'the'), (3, 'language'), (8, 'code') ...]
3 wordFrequences = getWordCounts (originalText)
4 // Filtra las palabras vacías , la matriz se convierte en [(3, 'idioma'), (8, 'código') ...]
5 contentWordFrequences = filtStopWords (wordFrequences)
6 // Seguir La frecuencia de las palabras se ordena y la matriz se convierte en ['código', 'idioma' ...]
7 contentWordsSortbyFreq = sortByFreqThenDropFreq (contentWordFrequences)
8 // Divida el artículo en oraciones
9 oraciones = getSentences (originalText)
10 // Seleccione la oración donde la palabra clave aparece primero
11 setSummarySentences = {}
12 para cada palabra en contentWordsSortbyFreq:
13 firstMatchingSentence = buscar (oraciones, palabra)
14 setSummarySentences.add (firstMatchingSentence)
15 if setSummarySentences.size () = maxSummarySize:
16 break
17 // Combina las oraciones seleccionadas en el orden de aparición para formar un resumen
18 summary = ""
19 para cada oración en oraciones:
20 if oración en setSummarySentences:
21 resumen = resumen + "" + oración
22 resumen de devolución