Una codificación de caracteres de desarrollo:
Carácter que codifica el proceso de desarrollo:
Fase 1:
El equipo sólo reconocer los números, todos nuestros datos se basan en cifras para demostrar que en el ordenador, a causa de señal de Inglés limitado,
por lo que el byte más significativo de la obligación de utilizar un 0. Cada byte es de entre 0 y 127 números para representar, por ejemplo correspondiente a un 65, una correspondencia 97.
este es el código estándar americano para el intercambio de información -ascii.
Fase 2:
Con la popularidad de los ordenadores en el mundo, muchos países y regiones se ven en los personajes equipo introducidas, tales como caracteres chinos.
En este caso encontró que un byte puede representar un rango de números demasiado pequeños para contener todos los caracteres chinos, las disposiciones de usar dos bytes para representar un carácter.
establece que: el código de caracteres ASCII original permanece sin cambios, utilice un byte, con el fin de distinguir un carácter chino con dos caracteres ASCII,
caracteres chinos máximo cada byte se define como 1-bit (binario chino es negativo). esta especificación es GB2312 de codificación,
y más tarde añadido más caracteres chinos sobre la base de GB2312, tales como caracteres chinos, también apareció GBK.
Fase 3:
un nuevo problema en China es reconocer los caracteres chinos, pero si los personajes se pasan a otros países, la tabla de códigos de país no está incluido en los personajes, de hecho, muestran otro símbolo o ilegible.
Con el fin de resolver los diversos países a causa de caracteres localizados el impacto causado por la codificación, poner todos los símbolos son codificados -unicode en todo el mundo unificado de codificación.
en este punto, uno en cualquier carácter en el mundo son fijos, tales como 'hermano', se basan en cualquier lugar hexadecimal 54E5 hizo representar.
el código de caracteres Unicode ocupa dos bytes de tamaño.
conjunto de caracteres comunes:
ASCII: un byte puede contener sólo 128 caracteres no se puede representar símbolos.
ISO-8859-1: (Latin-1): un byte, una colección de idiomas de Europa occidental, los caracteres chinos no se puede representar ..
ANSI: dos bytes, en el sistema operativo en chino simplificado se refiere a ANSI GB2312.
GB2312 / JDS / GB18030: dos bytes, el apoyo chino.
UTF-8:. es una longitud variable para la codificación de caracteres Unicode , llamado Unicode, que es uno de la aplicación Unicode.
Que codifica el primer byte sigue siendo compatible con ASCII, lo que hace que el manejo de los caracteres ASCII originales de software que no necesita o sólo una pequeña parte de los cambios, se puede seguir utilizando.
Por lo tanto, se ha convertido gradualmente electrónica codificada, páginas web y otras aplicaciones de texto almacenados o transmitidos, el uso de prioridad. Internet Engineering Task Force (IETF) requiere se requiere que todos los protocolos de Internet para el apoyo codificación UTF-8.
UTF-8 BOM: MS se dedica a la fuera del código, por defecto, 3 bytes, no utilice esta.
El almacenamiento de letras, números y caracteres:
letras y almacenamiento de números no importa qué juego de caracteres es de 1 byte.
Carácter de almacenamiento: Familia GBK dos bytes, UTF-8 familia de 3 bytes.
No se puede utilizar un solo byte juego de caracteres (ASCII / ISO-8859-1) para almacenar los chinos.
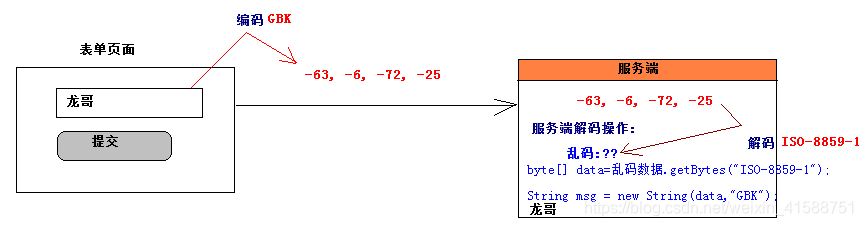
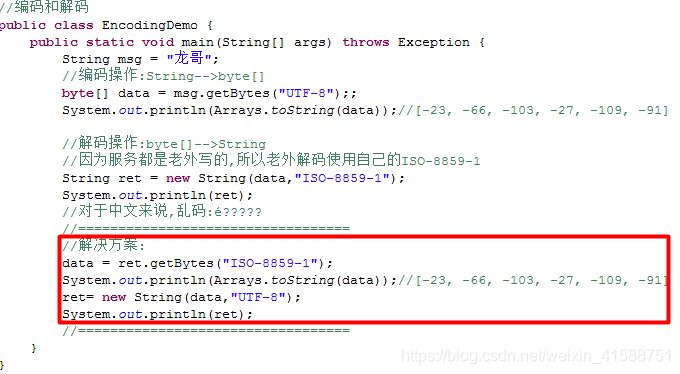
Dos codificación de caracteres y operaciones de decodificación:
Código: Convierte una cadena matriz de bytes.
Decoded: La matriz de bytes en una cadena
debe asegurarse de que la misma codificación y decodificación de un personaje, o ilegible.
Tres herramientas.
import java.io.UnsupportedEncodingException;
/**
* 字符编码工具类
*/
public class CharTools {
/**
* 转换编码 ISO-8859-1到GB2312
* @param text
* @return
*/
public static final String ISO2GB(String text) {
String result = "";
try {
result = new String(text.getBytes("ISO-8859-1"), "GB2312");
}
catch (UnsupportedEncodingException ex) {
result = ex.toString();
}
return result;
}
/**
* 转换编码 GB2312到ISO-8859-1
* @param text
* @return
*/
public static final String GB2ISO(String text) {
String result = "";
try {
result = new String(text.getBytes("GB2312"), "ISO-8859-1");
}
catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
}
return result;
}
/**
* Utf8URL编码
* @param s
* @return
*/
public static final String Utf8URLencode(String text) {
StringBuffer result = new StringBuffer();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (c >= 0 && c <= 255) {
result.append(c);
}else {
byte[] b = new byte[0];
try {
b = Character.toString(c).getBytes("UTF-8");
}catch (Exception ex) {
}
for (int j = 0; j < b.length; j++) {
int k = b[j];
if (k < 0) k += 256;
result.append("%" + Integer.toHexString(k).toUpperCase());
}
}
}
return result.toString();
}
/**
* Utf8URL解码
* @param text
* @return
*/
public static final String Utf8URLdecode(String text) {
String result = "";
int p = 0;
if (text!=null && text.length()>0){
text = text.toLowerCase();
p = text.indexOf("%e");
if (p == -1) return text;
while (p != -1) {
result += text.substring(0, p);
text = text.substring(p, text.length());
if (text == "" || text.length() < 9) return result;
result += CodeToWord(text.substring(0, 9));
text = text.substring(9, text.length());
p = text.indexOf("%e");
}
}
return result + text;
}
/**
* utf8URL编码转字符
* @param text
* @return
*/
private static final String CodeToWord(String text) {
String result;
if (Utf8codeCheck(text)) {
byte[] code = new byte[3];
code[0] = (byte) (Integer.parseInt(text.substring(1, 3), 16) - 256);
code[1] = (byte) (Integer.parseInt(text.substring(4, 6), 16) - 256);
code[2] = (byte) (Integer.parseInt(text.substring(7, 9), 16) - 256);
try {
result = new String(code, "UTF-8");
}catch (UnsupportedEncodingException ex) {
result = null;
}
}
else {
result = text;
}
return result;
}
/**
* 编码是否有效
* @param text
* @return
*/
private static final boolean Utf8codeCheck(String text){
String sign = "";
if (text.startsWith("%e"))
for (int i = 0, p = 0; p != -1; i++) {
p = text.indexOf("%", p);
if (p != -1)
p++;
sign += p;
}
return sign.equals("147-1");
}
/**
* 判断是否Utf8Url编码
* @param text
* @return
*/
public static final boolean isUtf8Url(String text) {
text = text.toLowerCase();
int p = text.indexOf("%");
if (p != -1 && text.length() - p > 9) {
text = text.substring(p, p + 9);
}
return Utf8codeCheck(text);
}
}
