meta
En este capítulo, vamos a volver a reconocer conjuntos de datos escritos a mano, pero en lugar de utilizar SVM kNN.
Reconocer los números escritos a mano
En kNN, utilizamos directamente la intensidad de los píxeles como un vector de características. Esta vez vamos a utilizar un histograma de orientación de gradiente (HOG) como un vector de características.
En este caso, antes de encontrar HOG, utilizamos los momentos de segundo orden de la corrección de la inclinación de la imagen. Por lo tanto, en primer lugar definir una función de Corrección de Desviación () , la función de la adquisición de una imagen digital y corregido. La siguiente es la función Deskew ():
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
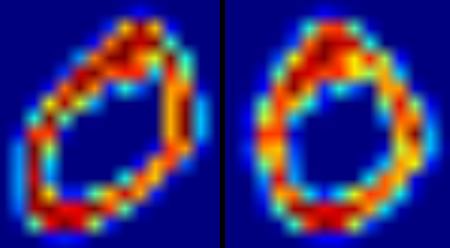
return imgSe aplica la siguiente figura se muestra un cero a la función de corrección de desplazamiento de imagen. Imagen de la izquierda es la imagen original, como el desplazamiento a la derecha imagen corregida.
A continuación, tenemos que encontrar descriptores HOG para cada celda. Con este fin, hemos encontrado un número de piloto Sobel para cada unidad en las direcciones X e Y. A continuación, busque su tamaño y dirección del gradiente en cada píxel. Los gradientes se cuantifican a 16 valores enteros. Esta imagen se divide en cuatro sub-cuadrados. Para cada calcular sub-cuadrado la dirección correcta importante pequeño histograma (16 bin). Así, cada sub-cuadrado proporciona un vector que contiene 16 valores para usted. (Cuatro sub cuadrado) en conjunto proporcionan cuatro de tales vectores que contienen un vector de valores de características 64 para nosotros. Se trata de nuestros vectores de características de datos de entrenamiento.
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return histPor último, al igual que en el caso anterior, dividimos el primer conjunto de datos como una sola célula grande. Para cada número, reservado para las unidades de datos de entrenamiento 250, 250 los datos restantes reservados para probar. Completar el código de abajo, puedes descargarlo desde aquí:
#!/usr/bin/env python
import cv2 as cv
import numpy as np
SZ=20
bin_n = 16 # Number of bins
affine_flags = cv.WARP_INVERSE_MAP|cv.INTER_LINEAR
def deskew(img):
m = cv.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img
def hog(img):
gx = cv.Sobel(img, cv.CV_32F, 1, 0)
gy = cv.Sobel(img, cv.CV_32F, 0, 1)
mag, ang = cv.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist
img = cv.imread('digits.png',0)
if img is None:
raise Exception("we need the digits.png image from samples/data here !")
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]
# First half is trainData, remaining is testData
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]
deskewed = [list(map(deskew,row)) for row in train_cells]
hogdata = [list(map(hog,row)) for row in deskewed]
trainData = np.float32(hogdata).reshape(-1,64)
responses = np.repeat(np.arange(10),250)[:,np.newaxis]
svm = cv.ml.SVM_create()
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)
svm.train(trainData, cv.ml.ROW_SAMPLE, responses)
svm.save('svm_data.dat')
deskewed = [list(map(deskew,row)) for row in test_cells]
hogdata = [list(map(hog,row)) for row in deskewed]
testData = np.float32(hogdata).reshape(-1,bin_n*4)
result = svm.predict(testData)[1]
mask = result==responses
correct = np.count_nonzero(mask)
print(correct*100.0/result.size)Este método especial nos da casi el 94 por ciento de exactitud. Puede probar diferentes valores para los distintos parámetros de SVM para comprobar si se puede lograr una mayor precisión. O bien, puede leer el documento técnico sobre esta área y tratar de ponerlas en práctica.
Recursos adicionales
- Histogramas de gradientes Orientada vídeo: https://www.youtube.com/watch?v=0Zib1YEE4LU
práctica
- muestra OpenCV comprende digits.py, el método descrito anteriormente es una serie de mejoras para dar mejores resultados. También contiene material de referencia. Comprobar y entenderlo.
AI acoge favorablemente la atención Pan Chong blog de la estación: http://panchuang.net/
OpenCV documento oficial chino: http://woshicver.com/
Bienvenido atención Pan Chong blog en recursos estación Resumen: http://docs.panchuang.net/
