ASCII, Unicode y UTF-8 y finalmente encontró un completamente claro del artículo
reimpresión: Deft_MKJing Mi Ke Jing
https://blog.csdn.net/Deft_MKJing/article/details/79460485
Le gustan las cosas a escribir, ver blog ha sido un tanto ignorante de la codificación, esta tarde no sé qué ver, de repente quiere saber a continuación, se encuentra este artículo, después de leer muy pronto, esto se debe dejar de hacer el memorial.
1.ASCII
sabemos, ordenador interno, toda la información es en última instancia un valor binario. Cada dígito binario (bit) tiene dos estados 0 y 1, y por lo tanto ocho bits pueden combinarse los 256 estados, que se llama un byte (byte). Esto es, un total de un byte puede ser usado para representar 256 estados diferentes, cada estado correspondiente a un símbolo, que es de 256 símbolos, de 00.000.000 a 11.111.111.
Años 60 del siglo pasado, los Estados Unidos desarrollaron un conjunto de codificación de caracteres, la relación entre los personajes y los bits inglés, reglamentos uniformes hechos. Esto se conoce como código ASCII, todavía en uso.
código ASCII codificación proporciona para un total de 128 caracteres, tales como espacios SPACE 32 (binario 00100000), la letra mayúscula A es 65 (binario 01000001). Los 128 símbolos (incluyendo 32 símbolos de control no se pueden imprimir), solo se necesita un byte 7 detrás del uno uniforme todo predeterminada cero.
2. No-ASCII codificado
Inglés con una codificación de 128 símbolo suficiente, pero para representar otros idiomas, 128 símbolos no es suficiente. Por ejemplo, en francés, hay símbolos fonéticos encima de las letras, que no pueden ser representados por los códigos ASCII. Como resultado, algunos países europeos decidieron utilizar el byte más significativo de inactividad incorporado en el nuevo símbolo. Por ejemplo, el francés E codifica como 130 (binario 10000010). Como resultado, el sistema de codificación utilizado por los países europeos, puede representar hasta 256 símbolos.
Sin embargo, también aquí hay un nuevo problema. Diferentes países tienen diferentes letras, por lo tanto, incluso si están utilizando la codificación de 256 símbolos, letras representan no es lo mismo. Por ejemplo, 130 representa la codificación en é francesa, letra hebrea que representa la codificación de Gimel (ג), en la codificación de los símbolos de Rusia en nombre de otro. Pero en cualquier caso, todos estos códigos, el símbolo representa 0-127 es lo mismo, no es lo mismo en este párrafo es sólo 128--255.
En cuanto a los países asiáticos de texto, símbolos utilizados aún más, hasta 10 millones de caracteres chinos. Un byte puede representar solamente 256 tipos de símbolos, es definitivamente no es suficiente, tiene que usar varios bytes expresan un símbolo. Por ejemplo, la codificación simplificado chino es GB2312 común, el uso de dos bytes de un carácter, por lo que teóricamente representa hasta 256 x 256 = 65536 símbolos
problema de codificación china discutió necesidades especiales, esta nota no implica. Aquí sólo se observaron que, aunque un símbolo está representado por una pluralidad de bytes, pero el código de caracteres y en lo sucesivo clases GB son Unicode UTF-8 y no relacionado.
3.Unicode
Como se mencionó en la sección anterior, hay una variedad de codificar el mundo, con un número binario puede ser interpretada como diferentes símbolos. Por lo tanto, con el fin de abrir un archivo de texto, debe conocer la codificación, o la lectura de la codificación incorrecta, será ilegible. ¿Por correo electrónico a menudo ilegible? Debido a que codifica el uso remitente y el destinatario no es el mismo.
Imagínese, si hay un código, se incluyen todos los símbolos del mundo. Cada símbolo se le asigna un código único, entonces el problema de la basura desaparecerá. Esta es Unicode, como su nombre lo he dicho, esto es todo un símbolo de codificación.
Unicode es sin duda una gran colección de su tamaño actual con capacidad para más de un millón de símbolos. Codificar cada símbolo es diferente, por ejemplo, U + 0639 representa la letra árabe Ain, U + 0041 para las mayúsculas Inglés A, U + 4E25 expresó caracteres graves. tabla específica símbolo de la correspondencia puede consultar Unicode.org, caracteres especiales o tabla de correspondencia.
4.Unicode problema
hay que señalar que, Unicode es sólo un conjunto de símbolos, que sólo proporciona la notación binaria, pero no especifica cómo se debe almacenar en código binario.
Por ejemplo, los caracteres Unicode Yan números hexadecimales 4E25, una conversión completa en un número binario 15 (100,111,000,100,101), es decir, este símbolo representa al menos 2 bytes. Otros símbolos representan mayor, puede requerir de 3 bytes o 4 bytes, o incluso más.
Aquí hay dos problemas graves, la primera pregunta es, ¿cómo puede la diferencia entre Unicode y ASCII? La computadora sabe cómo tres bytes representan un símbolo, en lugar de los tres símbolos representan ello? El segundo problema es que ya sabemos, las cartas de un solo byte es suficiente, si Unicode normativa unificada, cada símbolo está representado por tres o cuatro bytes, se dirigen a dos antes de cada letra a tres bytes es 0, lo que es una gran pérdida para el almacenamiento, el tamaño del archivo de texto será grande y por lo tanto de dos a tres veces, lo que no es aceptable
Los resultados que causan son: 1) la aparición de una variedad de almacenamiento Unicode, lo que significa que hay muchos formato binario diferente, puede ser usado para representar Unicode. 2) Unicode no puede promover un largo período de tiempo, hasta que la aparición de Internet.
5.UTF-8
popularidad de Internet, instó a que aparezca codificación unificadas. UTF-8 es la aplicación más utilizada usando un Unicode en Internet. Otras implementaciones que comprende además UTF-16 (carácter de dos bytes o cuatro bytes), y UTF-32 (cuatro bytes representados por carácter), pero sustancialmente no en Internet. Repita, aquí está la relación, UTF-8 Unicode es una de implementación.
característica más grande UTF-8 es que es una codificación de longitud variable. Puede ser de 1 a 4 bytes de un símbolo, byte de longitud varía en función del símbolo.
Codificación UTF-8 reglas son muy simples, sólo dos:
1) Para los símbolos de un solo byte, un conjunto de byte 0, la parte posterior 7 del símbolo de código Unicode. Por lo tanto, para el alfabeto Inglés, codificación UTF-8 y los códigos ASCII son los mismos.
2) El símbolo n bytes (n> 1), los primeros n bits del primer byte se establece en 1, el n + 1 bit se pone a 0, los dos primeros bytes del conjunto trasero 10 de manera uniforme. Los bits restantes no mencionados, todos los símbolos de código Unicode.
La siguiente tabla resume las reglas de codificación, la letra X representa bits de codificación disponibles.
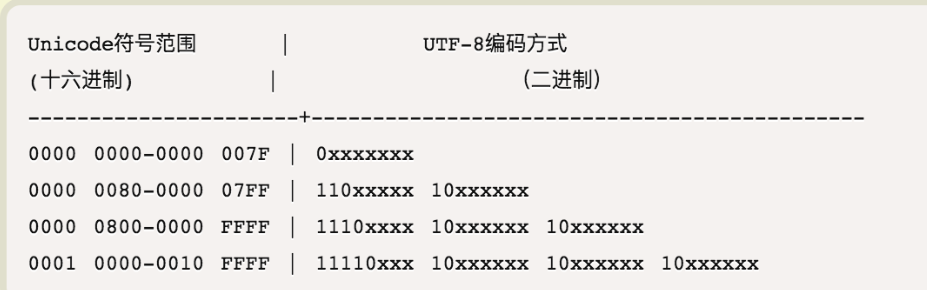
Ahora está sobre la mesa, la lectura de codificación UTF-8 es muy simple. Si el primer byte es 0, entonces este es un carácter de un solo byte, si el primer bit es 1, el número de consecutivo 1, que indica cuántos bytes ocupados por el carácter actual.
Aquí, los caracteres chinos estrictas o, por ejemplo, muestra cómo implementar codificación UTF-8.
Yan Unicode se 4E25 (100,111,000,100,101), de acuerdo con la tabla, se puede encontrar en el intervalo de 4E25 tercera fila (0000 0.800-0000 FFFF), y por lo tanto estricta codificación UTF-8 requiere tres bytes, es decir, el formato 1110xxxx 10xxxxxx 10xxxxxx. Entonces, el principio estricta último bit, llena secuencialmente, de atrás hacia adelante en el formato x, los 0s bits adicionales. Así obtenida, la estricta codificación UTF-8 es 1,110,010,010,111,000 10100101, se convierte en E4B8A5 hexadecimal
Y la conversión entre UTF-8 6.Unicode
Por el ejemplo de la sección anterior, podemos ver Yan código Unicode es 4E25, UTF-8 de codificación es E4B8A5, los dos no son lo mismo. Las transiciones entre ellas se pueden implementar mediante un programa.
plataforma Windows, existe un método de transformación sencilla es utilizar la incorporada en el Bloc de notas applet de notepad.exe. Después de abrir el archivo, haga clic en el menú Archivo en el comando Guardar como, se mostrará un cuadro de diálogo en la parte inferior hay una barra desplegable de codificación.
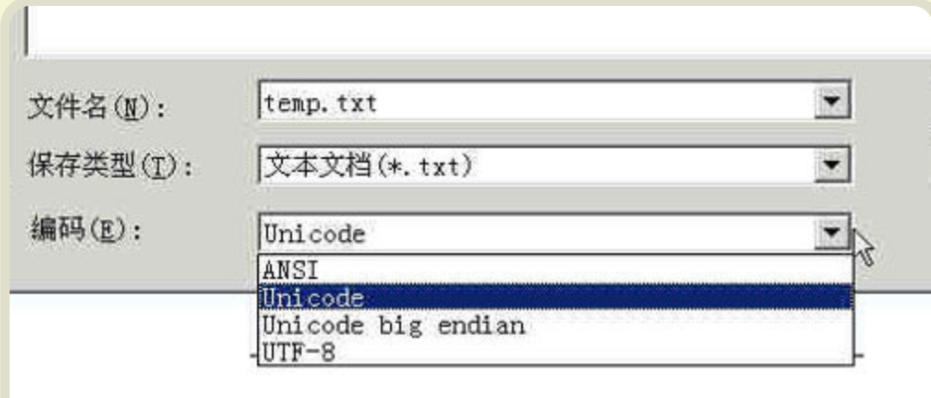
Hay cuatro opciones: ANSI, Unicode, Unicode big endian y UTF-8.
1) ANSI es la codificación predeterminada. Para Inglés archivos son la codificación ASCII de archivo Chino simplificado GB2312 está codificado (sólo para la versión de Windows chino simplificado, si es tradicional china usará en código Big 5).
2) en el presente documento se refiere a una codificación Unicode UCS-2 de codificación notepad.exe utiliza, es decir, directamente en caracteres Unicode con dos bytes, esta opción con poco formato endian.
3) Unicode big endian codifica en una opción correspondiente. Voy a explicar en la siguiente sección big endian y little endian significado.
4) UTF-8 de codificación, la codificación es un método discutido.
Después de seleccionar la "codificación", haga clic en el botón "Guardar", la codificación de archivos inmediatamente convertir mejor.
Big endian 7.Little endian y
del que ya se ha mencionado, el formato UCS-2 puede almacenar código Unicode (punto de código no más de 0xFFFF). Caso del kanji Yan, código Unicode es 4E25, necesidad de almacenar dos bytes, un byte es 4E, otro byte es 25. Cuando se almacena, frente 4E y 25 en el post, esto es el modo endian grande; 25 frontal, 4E después, este es el modo endian pequeño.
Los dos extraño nombre viene del escritor británico Jonathan Swift "Los viajes de Gulliver". En el libro, Lilliput estallido de la guerra civil, la guerra es la causa de debate, si se cae de la mayor (Big-endian) o cabeza pequeña (Little-endian) golpeó comer huevos. Para este asunto, antes y después de la guerra estalló en seis ocasiones, un emperador perdió la vida, otro emperador perdió su trono.
El primer byte en primer lugar, es el "modo mayor" (big endian), primer, segundo byte es el "modo de cabeza" (Little Endian).
Así que, naturalmente, habrá un problema: ¿cómo saber un ordenador en el final ¿qué tipo de un archivo codificado usando?
define especificación Unicode, la parte delantera de cada archivo se añaden secuencialmente a una representación de código de caracteres del nombre de este carácter se llama un "espacio cero-anchura de no separación" (cero la anchura del espacio no-break), representada por FEFF. Esto es exactamente dos bytes, y FF FE grande que 1.
Si los dos primeros bytes del archivo de texto es un FF FE, significa que el archivo es el modo mayor, y si los dos primeros bytes FF FE, significa que el archivo es un pequeño ejemplo de realización la cabeza.
8. Ejemplos
La siguientes dan un ejemplo.
Abrir el "Bloc de notas" aplicación Bloc de notas, cree un archivo de texto, el contenido es una palabra estricta, de forma secuencial utilizando ANSI, Unicode Guardar, big endian Unicode y codificación UTF-8.
A continuación, utilice un software UltraEdit editor de texto en la "función Hex," observar la codificación interna del archivo.
1) ANSI: archivo codificado es de dos bytes D1 CF, que es estricta codificación GB2312, se ha sugerido es el uso de GB2312 almacenados a granel.
2) Unicode: codificar cuatro bytes FF FE 25 4E, que muestra que una pequeña cabeza FF FE almacena, la codificación real es 4E25.
3) Unicode big endian: codificar cuatro bytes FE FF 4E 25, en el que la mayor FE FF indican almacena.
4) UTF-8: la codificación es de seis bytes EF BB BF E4 B8 A5, los tres primeros bytes EF BB BF indica que se trata de codificación UTF-8, después de la codificación de tres E4B8A5 particular es grave, y su orden de almacenamiento secuencia de codificación es consistente.
9. suplementario
hoy al mirar sólo para ver el pitón en la codificación del artículo, grabarlo. La lógica básica de lo anterior se ha nacido, otra introducción del complemento.
Ahora, un derrame cerebral y accidente cerebrovascular son Unicode de codificación ASCII diferencias: código ASCII es de 1 byte, y la codificación Unicode es por lo general de 2 bytes.
Una carta con la codificación ASCII es 65 decimal, binario 01000001;
Personajes están codificados en ASCII 0 48 decimal, binario 00110000, carácter de atención '0' es diferente de 0 y números enteros;
los caracteres chinos más allá del alcance del código ASCII, Unicode codificados decimal binario 20013 0.100.111.000.101.101.
Se puede adivinar, si la codificación ASCII de A con la codificación Unicode, justo en frente de 0s puede, por lo tanto, la codificación Unicode A es 0.000.000.001.000.001.
El nuevo problema ha surgido: si unificado en la codificación Unicode, el problema de la basura desaparece. Sin embargo, si se escribe esencialmente todo el texto está en Inglés, a continuación, utilizar la codificación Unicode que el código ASCII requiere el doble de espacio de almacenamiento en el almacenamiento y el transporte será muy valioso.
Así, en el espíritu de conservación, y la aparición de la codificación Unicode en un "código de longitud variable" codificación UTF-8. UTF-8 codificada de acuerdo con Unicode carácter a un tamaño diferente de las figuras 1-6 codifica en bytes, letras utilizadas comúnmente se codifican en un personajes bytes típicamente de 3 bytes, solamente un carácter raro serán codificado en bytes 4-6. Si desea transferir el texto contiene una gran cantidad de caracteres en inglés, el uso codificación UTF-8 será capaz de ahorrar espacio:

Unicode UTF-8 caracteres ASCII
A 01000001 00000000 01000001 01000001
en x 01001110 00101101 11100100 10111000 10101101
también se puede encontrar a partir de la tabla anterior, codificación UTF-8 tiene una ventaja adicional es que la codificación ASCII en realidad puede ser visto como codificación UTF-8 parte de ella, un montón de historia sólo es compatible con ASCII software heredado de codificación pueden continuar funcionando en codificación UTF-8
Para averiguar la relación entre ASCII, Unicode y UTF-8, ahora podemos resumir el carácter general la codificación funciona el sistema informático:
En la memoria del ordenador, el uso uniforme de la codificación Unicode, cuando la necesidad de ahorrar tiempo o las necesidades de disco duro a transmitir, se convierte en codificación UTF-8.
Utilice Bloc de notas para editar el tiempo, caracteres UTF-8 lee desde el archivo se convierte a caracteres Unicode en la memoria, después de la edición es completa, ahorrar tiempo y luego se convierte a Unicode UTF-8 para guardar el archivo:

Así que ya ves será similar a <meta charset = "UTF-8" /> fuente de información en muchas páginas, mostrando codificación UTF-8 de la página que se utiliza.