En primer lugar, lo que es Presto?
- Antecedentes: La desventaja de la colmena y Presto fondo
Colmena MapReduce utiliza como el marco de computación subyacente, está diseñado específicamente para el lote. Pero a medida que más y más datos, lleve a cabo un sencillo de usar consulta de datos colmena puede tardar unos minutos a unas pocas horas, obviamente, no puede satisfacer las necesidades de consulta interactiva. Presto es un motor de consultas SQL distribuido, que está específicamente diseñado para la alta velocidad, el análisis de datos en tiempo real. Es compatible con la norma ANSI SQL, incluyendo consultas complejas, la polimerización (agregación), la conexión (unión) y la función ventana (funciones de la ventana). De los cuales hay dos puntos vale la pena explorar, primero de la arquitectura, seguido por naturaleza, es la forma de lograr una baja latencia para apoyar la interacción oportuna.
- PRESTO lo que?
Presto es un código abierto distribuido motor de consultas SQL para la consulta análisis interactivo, la cantidad de datos para apoyar GB PB bytes. Presto está diseñado y escrito en su totalidad con el fin de solucionar problemas como el análisis interactivo y almacenamiento de datos comercial de la velocidad de procesamiento de este tamaño de Facebook.
- ¿Qué puede hacer?
Presto permite la consulta de datos en línea, incluyendo la colmena, Cassandra, bases de datos relacionales, y almacenes de datos propietarias. Presto a datos de consulta de múltiples fuentes de datos se combinan, se puede analizar a través de toda la organización. analistas demanda Presto como un objetivo, se espera que el tiempo de respuesta de menos de un segundo hasta varios minutos. Presto terminó el análisis de datos dilema, o utilizar los programas comerciales rápido caros, o el uso consumen una gran cantidad de hardware lenta programa de "libre".
- ¿Quién lo usa?
Facebook utilizando Presto consulta interactiva, una pluralidad de almacenamiento de datos interna, incluyendo almacén de datos 300PB. Cada día más de 1000 empleados de Facebook Presto, el número de consultas ejecutado más de 30.000 veces, la cantidad de datos de escaneado más de 1 PB. Las empresas de Internet líderes como Airbnb y Dropbox están utilizando Presto.
Dos, la arquitectura Presto
Presto es una carrera en varios servidores en un sistema distribuido. Instalación completa que comprende un coordinador y una pluralidad de trabajador. Enviar una consulta por parte del cliente, a someterse a la línea de comandos CLI de coordinador de Presto. análisis sintáctico coordinador, analizar y ejecutar el plan de consulta, y luego distribuir la cola de procesamiento para los trabajadores.
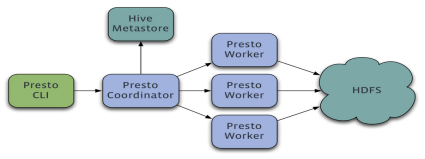
motor de consulta Presto es una arquitectura maestro-esclavo se compone de un nodo coordinador, un nodo servidor Discovery, múltiples nodos de trabajo, Descubrimiento servidor es generalmente incrustadas en el nodo coordinador. Coordinador es responsable de analizar el plan de ejecución de instrucciones SQL, distribuir tareas a realizar nodos de trabajo. nodo trabajador es responsable de la implementación real de las tareas de consulta. Después de nodo trabajador para iniciar el registro de servicio de localización del servidor, Coordinador Trabajador nodos para obtener un trabajo adecuadamente de Discovery Server. Si configura el conector de la colmena, es necesario configurar un servicio proporcionado Colmena Colmena MetaStore meta-información para el Presto, Trabajador nodos interactúan con HDFS leer los datos.
En tercer lugar, instalar Presto Servidor
- medios de instalación
Presto-cli-0.217-executable.jar Presto-server-0.217.tar.gz
- configuración de la instalación Presto Servidor
1, extraer el paquete de instalación
tar -zxvf Presto-server-0.217.tar.gz -C ~ / formación /
2, crear el directorio etc.
cd ~ / formación / Presto-server-0.217 / mkdir etc.
3, necesidad de incluir los siguientes archivos de configuración en el directorio etc.
la información de configuración de nodos: el nodo de las propiedades de JVM Config: herramienta de línea de comandos parámetros de configuración de JVM propiedades de config: los parámetros de configuración del servidor Presto Catálogo de propiedades: fuente de datos (conectores) parámetros de configuración de propiedades del registro de parámetros de configuración:
- Editar node.properties
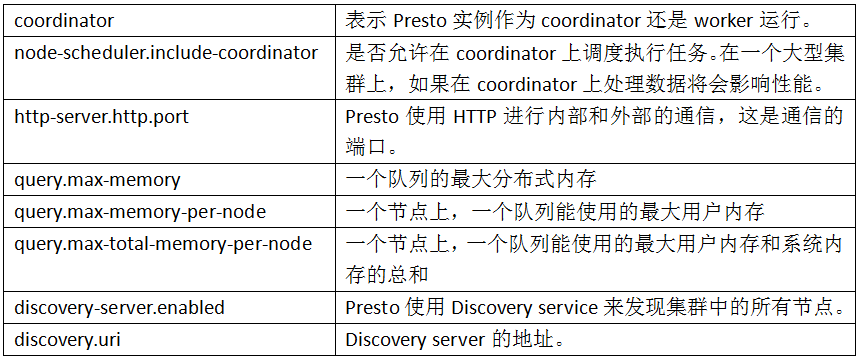
# Nombre de cluster. Presto todos los nodos del mismo clúster deben tener el mismo nombre de la agrupación. node.environment = producción identifica de forma única cada Presto # nodo. Node.id cada nodo debe ser único. O reiniciar el proceso de actualización node.id cada nodo de la aplicación Presto debe permanecer sin cambios. Presto Si varias instancias instaladas en un nodo (por ejemplo .: Presto pluralidad de nodos instalados en la misma máquina), a continuación, cada nodo debe tener una node.id. Presto único node.id = ffffffffffff-ffffffff-ffffffffffff directorio de almacenamiento de datos de posición # (ruta de acceso en el sistema operativo). Presto pondrá esta fecha directorio y almacenada en los datos. node.data-dir = / root / formación de datos / Presto-servidor-0.217 /
- Editar jvm.config
Dado que la JVM OutOfMemoryError resultará en un estado inconsistente, así que cuando nos encontramos con esta acción de error es recoger información general (para depuración) headp volcado, y luego obligado a terminar el proceso. Presto consulta será compilada en un archivo de código de bytes, y por lo tanto genera un número de clase Presto, hay que aumentar el tamaño que la región de Perm (Perm almacena principalmente en la clase) y permitiendo la descarga de clases JVM.
-server -Xmx16G -XX: + UseG1GC -XX: G1HeapRegionSize = 32M -XX: + UseGCOverheadLimit -XX: + ExplicitGCInvokesConcurrent -XX: + HeapDumpOnOutOfMemoryError -XX: + ExitOnOutOfMemoryError
- Editar config.properties
configuración coordinador
coordinador = true nodo-scheduler.include-coordinador = false http-server.http.port = 8,080 query.max-memory = 5 GB query.max-memoria-per-nodo = 1 GB query.max-Total-memoria-per-nodo = 2 GB descubrimiento-server.enabled = true discovery.uri = http: //192.168.157.226: 8080
Configuración de los trabajadores
coordinador = false http-server.http.port = 8,080 query.max-memory = 5 GB query.max-memoria-per-nodo = 1 GB query.max-Total-memoria-per-nodo = 2 GB discovery.uri = http: / /192.168.157.226:8080
Si queremos ser probado en una sola máquina, coordinador de configuración y el trabajador, por favor utilice la configuración siguiente:
coordinador = true nodo-scheduler.include-coordinador = true http-server.http.port = 8,080 query.max-memory = 5 GB query.max-memoria-per-nodo = 1 GB query.max-Total-memoria-per-nodo = 2 GB descubrimiento-server.enabled = true discovery.uri = http: //192.168.157.226: 8080
parámetros:
- Editar log.properties
Configurar el nivel de registro.
com.facebook.presto = aproximadamente
- Catálogo de configuración Propiedades
Presto conectores de datos de acceso. Estos conectores montados en los catálogos. conector puede proporcionar un catálogo de todo el esquema y tabla. Por ejemplo: conector Colmena de cada colmena se asignan a un esquema de base, por lo que si el conector de la colmena montado en el catálogo llamado la colmena, y la colmena web tiene una tabla llamada clics, a continuación, en el Presto puede colmena. web.clicks para acceder a esta tabla. La inscripción se hace mediante la creación de un catálogo de archivo catálogos propiedades en el directorio etc / catálogo. Para crear un conector colmena fuente de datos, puede crear un archivo etc / Catálogo / hive.properties, el archivo de contenido es el siguiente, al término de la carga de un hivecatalog hiveconnector.
# Indica la versión hadoop connector.name = Colmena-hadoop2 # Colmena Sitio-configurado dirección hive.metastore.uri = Ahorro: //192.168.157.226: 9083 ruta de perfil #hadoop hive.config.resources = / root /training/hadoop-2.7.3/etc/hadoop/core-site.xml,/root/training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
Nota: Para acceder a la colmena, entonces usted necesita para comenzar Colmena de MetaStore: Colmena de --service meta almacén

En cuarto lugar, se inicia Presto Servidor
inicio ./launcher
6.3.5 operativo Presto-cli
- Descarga: Presto-CLI-0.217-executable.jar
- Cambie el nombre del paquete de frasco, y añade permisos de ejecución
cp presto-cli-0.217-executable.jar presto chmod a + x presto
- Presto conexión del servidor
./presto --server localhost: 8080 --catalog colmena --schema por defecto
En sexto lugar, el uso de Presto
- Presto operación utilizando Colmena

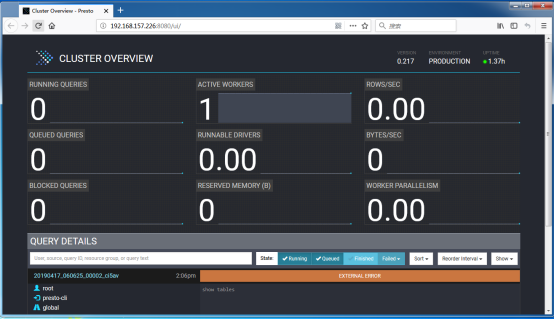
- El uso de Presto Web Console: Puerto: 8080
- Con Presto operaciones JDBC
1, necesidad dependiente Maven para contener
<dependency> <groupId> com.facebook.presto </ groupId> <artifactId> presto-jdbc </ artifactId> <versión> 0.217 </ versión> </ dependency>
2, Código JDBC

************************************************** *****************************************
